

-
原始发票图像常存在光照不均、倾斜、褶皱、背景干扰等问题。系统首先采用图像滤波、二值化、透视变换(仿射变换)等技术对图像进行增强和矫正,为后续识别提供高质量的输入。
-
这是深度学习的核心应用环节。采用目标检测模型(如YOLO、SSD、Faster R-CNN) 或语义分割模型(如U-Net),对发票上的各个关键字段(如发票代码、号码、日期、金额、购买方、销售方、商品明细等)进行精准定位和边框标注。模型通过海量数据训练,学会了忽略无关信息,直接锁定目标区域。
-
对定位到的每一个文本区域进行字符识别。传统的OCR技术对规整印刷体有效,但对手写体、模糊字体效果不佳。深度学习模型,特别是CRNN(卷积循环神经网络)+ CTC(连接时序分类) 或基于Attention(注意力)机制的模型,将图像特征序列化并转化为文本序列,极大地提升了复杂场景下的字符识别准确率。
-
识别出的文本是零散的。系统需要根据先验知识(如发票的固定格式、字段间的逻辑关系)将这些文本重构为有意义的结构化数据(JSON/XML格式)。例如,通过关键字(如“金额”、“税率”)匹配、规则校验(如发票号码和代码的校验位)和自然语言处理(NLP) 技术,确保“¥100.00”被正确归类到“价税合计”字段,而不是其他无关信息。
-
高精度识别:对印刷体中文、数字的识别准确率可达99%以上,并能有效处理轻微模糊、倾斜、光照不足等复杂场景。 -
全字段覆盖:不仅能识别抬头、金额、日期等基础信息,更能精准提取复杂的商品明细清单(包括名称、规格、单位、数量、单价、税额等)。 -
多版式自适应:无需预先指定模板,模型凭借强大的泛化能力,可自动适配全国各地、各种类型的增值税发票(普票、专票、卷票、电子发票)、火车票、出租车票等多种票据。 -
智能逻辑校验:内置业务规则引擎,可自动校验发票信息的逻辑性,如大小写金额是否一致、发票代码是否符合规则等,有效防止误判。
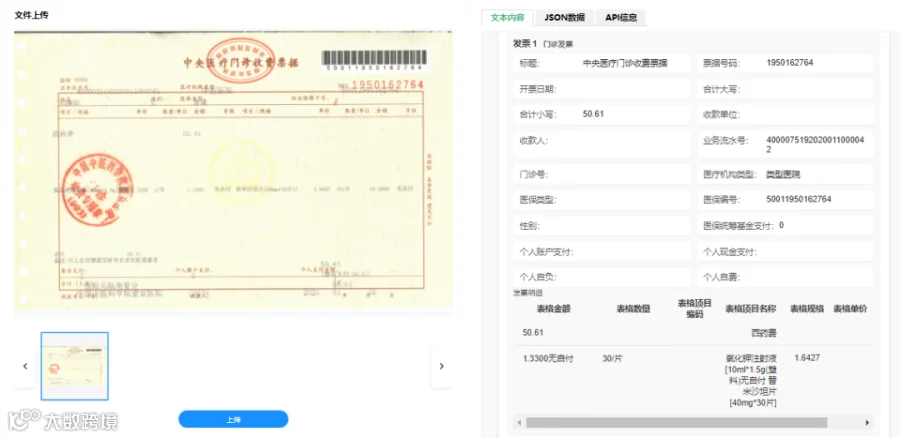
-
版式复杂多样:中国的发票种类繁多,不同行业、不同省份的版式千差万别,且税务局会不定期更新版本。这就要求模型必须具备极强的泛化能力(Generalization Ability),能够快速适应从未见过的新版式。 -
印章与文字重叠:发票上大量存在的红色印章常常与关键文字重叠,严重干扰识别。解决方案需要结合图像处理技术(如颜色分离)和深度学习模型对重叠区域的强鲁棒性训练。 -
低质量图像输入:在实际应用中,用户上传的图片可能来自手机拍照,存在模糊、反光、阴影等问题。这要求系统从预处理到核心模型都必须对噪声具有高鲁棒性(Robustness)。 -
复杂背景与字体:一些发票带有复杂的底纹背景,或使用特殊字体(如税控盘打印的点阵字体),增加了字符分割与识别的难度。 -
数据标注成本高昂:深度学习是数据驱动的,需要大量精准标注的发票图像数据进行训练。而发票信息敏感,标注工作需要专业知识和严格的隐私保护措施,导致数据获取和标注成本极高。
-
企业财务与审计:这是最核心的应用场景。实现自动化的发票录入、审核、报销和归档,极大提升财务工作效率,降低人力成本,并确保数据的准确性,便于后续的税务筹划和审计追溯。 -
金融与信贷:银行和金融机构在为企业办理对公信贷业务时,需要审核大量的增值税发票以验证其真实经营情况和流水。智能识别可以快速构建企业的经营画像,辅助风控决策。 -
政府与政务:税务部门利用该技术进行发票真伪查验和大数据分析,高效识别虚开发票等违法行为。政务报销系统也借此实现智能化升级。 -
供应链与电商:在处理采购订单、对账、结算等环节,需要核对大量进项发票。自动化识别可以加速供应链流程,提高协同效率。 -
代理记账行业:代账公司服务大量中小企业,每月处理成千上万张发票。该技术能将其从繁琐的manual 工作中解放出来,聚焦于更高价值的咨询服务。