

-
从“形”到“意”的跨越:传统OCR只能完成从图像到文字的转换(识其形),而文档抽取技术则能进一步理解文字的含义和关系(解其意)。 -
应对复杂场景:无论是格式多变的发票、结构复杂的合同,还是自由排版的简历,该技术都能像训练有素的文员一样,精准定位并提取关键信息。
-
文档采集:RPA机器人自动从邮件、扫描仪或业务系统中获取待处理文档。 -
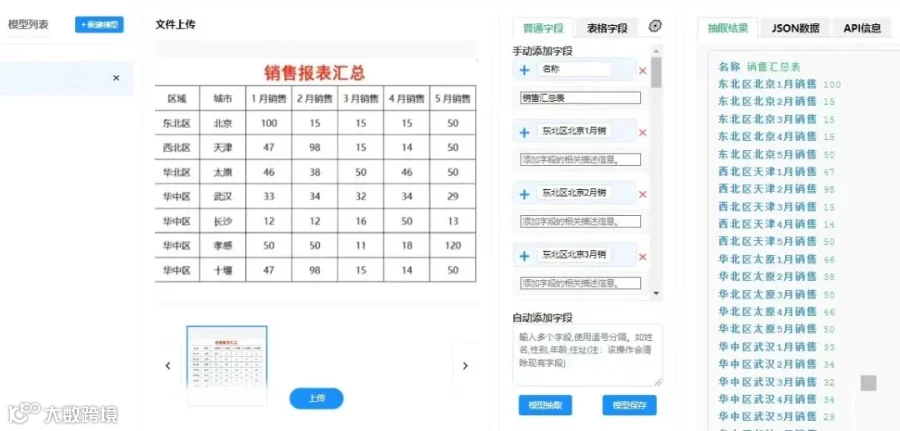
智能解析:文档被传送至抽取引擎,经过预处理、OCR识别后,AI模型开始解析文档结构和内容。 -
精准抽取:基于预定义的规则或机器学习模型,系统自动提取如金额、日期、条款等关键数据。 -
数据交付:抽取结果以结构化格式返回给RPA机器人。 -
自动执行:RPA将数据录入下游系统,完成业务流程的闭环。
-
发票处理:自动识别数十种发票版式,准确提取价税信息,实现秒级录入 -
报销审核:智能比对报销项目与制度要求,实现自动化合规审查
-
简历初筛:批量解析求职简历,智能匹配岗位要求,提升招聘效率 -
入职办理:自动提取身份证、学位证等信息,实现员工档案数字化
-
合同审查:快速提取关键条款,辅助法务人员进行风险识别 -
合规管理:自动监控合同履约情况,及时发出预警提示
-
更少的样本需求:小样本学习甚至零样本学习技术将降低对标注数据的依赖,使自动化快速适应新文档类型。 -
理解而非仅仅抽取:未来的技术将向文档理解发展,不仅能抽取字段,还能理解段落间的逻辑关系、识别文档的意图和情感。 -
与生成式AI结合:结合大型语言模型(LLM),RPA不仅能“读”文档,还能根据抽取的信息“写”报告、回复邮件或生成摘要,实现更高级别的自动化。