

-
灰度化与二值化:将彩色图像转换为灰度图,再进一步处理成只有黑白两色的图像,突出文字与背景的对比。 -
噪声去除:消除图像中的斑点、划痕等干扰因素。 -
倾斜校正:自动检测并矫正歪斜的文本行,确保文字水平对齐。
-
CNN 负责从图像中提取字符的视觉特征。 -
RNN(如LSTM) 则擅长处理序列数据,能够结合上下文信息来识别字符。这对于越南文至关重要,因为一个单词的音调可能依赖于前后字符。
-
音调符号的细微差别:音调符号(如´(锐声)、`(重声))非常小,在低分辨率或模糊的图像中极易丢失或误判。一个音调的错误就会完全改变词义(例如,“ma”(鬼)、“má”(妈妈)、“mà”(但是))。 -
特殊字符的相似性:字母如u和ư,o和ơ,d和đ在形态上非常相似,尤其在笔迹潦草或字体特殊时,区分难度大。 -
字符粘连与断裂:在印刷质量差或手写文档中,字符可能相互粘连或发生断裂,给准确分割和识别带来困难。 -
复杂的手写体variability: 每个人的笔迹千差万别,手写越南文的识别仍是世界性难题,对模型的泛化能力要求极高。 -
上下文依赖性强:正确的音调往往需要结合整个单词甚至句子的上下文才能确定,这对识别模型的NLP能力提出了更高要求。
-
高精度识别:针对印刷体,尤其是在清晰文档上,识别准确率可超过98%。对于规整的手写体,识别率也在不断提升。 -
音调符号精准还原:这是越南文OCR最核心的特点之一。能够准确识别并还原ă, â, ê, ô, ơ, ư, đ等特殊字母以及á, à, ả, ã, ạ等五种音调符号。 -
多格式文档支持:可处理扫描的PDF、JPG、PNG等多种图像格式,并能直接输出为可搜索的PDF、Word、TXT或Excel等格式。 -
批量处理与自动化:支持一次性处理大量文档,极大提升了数据录入和文档数字化的效率。 -
多场景适应:先进的算法能够应对拍照时的阴影、透视变形、复杂背景等挑战,具备一定的抗干扰能力。
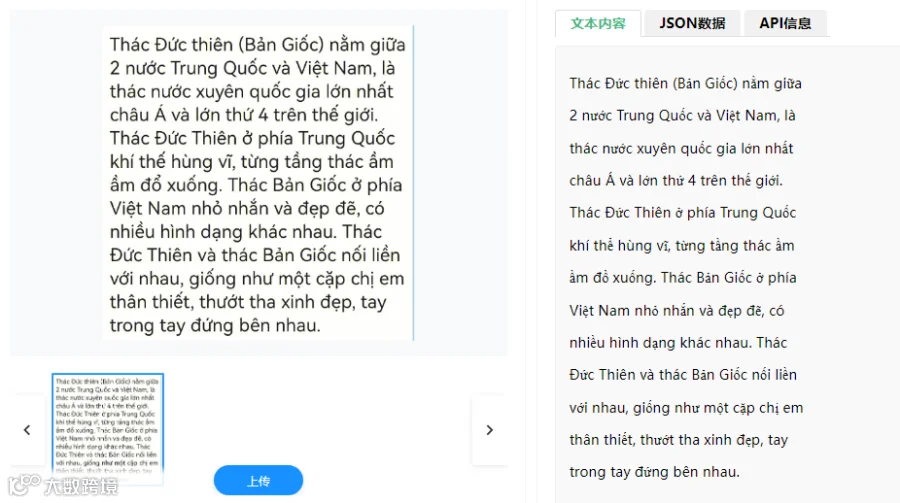
-
政府与公共事业:快速数字化海量的历史档案、户籍文件、地契等,实现高效检索与管理,推进“数字政府”建设。 -
金融与银行业:自动识别身份证、驾驶证、支票上的信息,用于开户、信贷审批等业务,减少人工输入错误,提升风控能力和客户体验。 -
教育与研究:将越南语教材、古籍、研究论文数字化,便于建立电子图书馆和进行文本分析,促进知识传播与学术研究。 -
企业办公自动化(OA): 自动识别和录入发票、合同、表单等商业文件,实现无纸化办公和业务流程自动化。 -
移动互联网应用:集成到手机APP中,实现即时翻译(摄像头对准越南语菜单或路牌即可翻译)、名片信息自动录入、扫描解题等便捷功能。 -
物流与电商:自动读取运单上的地址和商品信息,优化分拣和配送流程。