
-
在发票中:发票号码、开具日期、供应商名称、总金额。 -
在合同中:合同双方名称、生效日期、合同金额、终止条款。 -
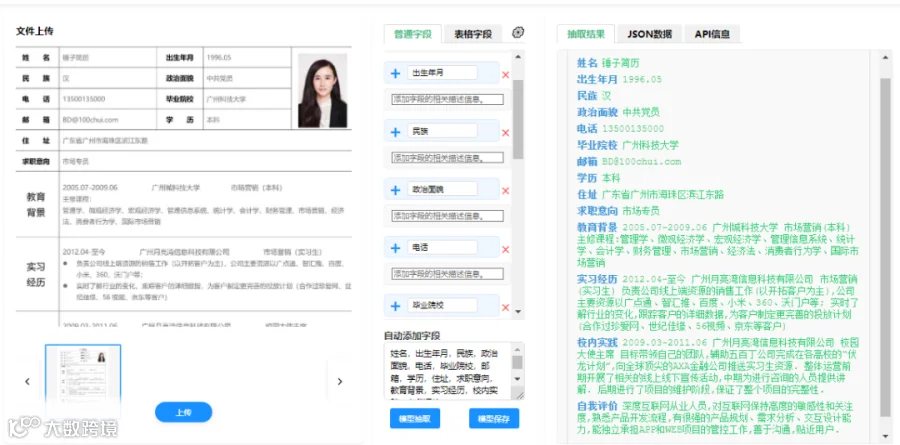
在简历中:候选人姓名、联系方式、工作经历、教育背景。

-
光学字符识别(OCR):如果文档是扫描件或图片格式,OCR技术首先登场。它的作用是识别图像中的字符,将其转换为机器可读的文本。这一步的准确性至关重要,是后续所有流程的基础。 -
文档结构解析:系统会分析文档的物理布局。它需要识别出哪些是标题,哪些是段落,哪些是表格,以及它们之间的相对位置关系。这就像系统在脑海中为文档绘制了一张“地图”。
-
让计算机通过大量已标注的文档样本自行学习如何识别和提取字段。这种方法更智能,能处理格式多变、语言复杂的文档。
-
命名实体识别(NER):这是NLP的一项核心技术。系统经过训练后,能够自动识别文本中的实体并将其分类。例如,它能识别出“北京”是地点,“2023年10月27日”是日期,“ABC科技有限公司”是组织机构。 -
序列标注模型:系统将文本视为一个序列,为序列中的每一个词或字打上标签(如B-金额, I-金额, O),从而精确地勾勒出关键字段的边界。 -
视觉特征学习:先进的模型不仅分析文本内容,还会考虑视觉特征,如字体大小、加粗、位置等,这些视觉线索对于判断一个字段的重要性(如标题)至关重要。
-
字段值的边界确定:系统需要判断“发票号: INV-2023-001”中,值是从“INV”开始,到“001”结束。 -
处理跨区域文本:有些字段的值可能分布在多行或多个单元格中(如商品清单),系统需要将它们正确地拼接起来。 -
表格处理:专门解析表格结构,理解表头与数据的对应关系,确保提取出的信息不错位。
-
数据标准化:将提取出的各式各样的日期(如“2023/10/27", "27 Oct 2023”)统一转换为一种标准格式。 -
纠错与验证:利用预定义的规则或外部知识库进行简单校验。例如,检查提取出的金额数字是否符合常识,或通过校验码验证身份证号码是否有效。
-
信贷审批:自动从银行流水、税务报表、工资单中提取收入、支出信息,加速信贷决策。 -
保险理赔:从理赔申请表、医疗记录、事故报告中提取事故详情、人员伤亡和财产损失信息,实现快速理赔定损。 -
合规与风控:扫描合同和法规文件,提取关键条款、义务和日期,确保合规并管理风险。
-
病历结构化:从非结构化的病历中提取患者症状、诊断结果、用药记录和手术信息,为临床研究和个性化诊疗提供数据支持。 -
保险结算:自动识别医疗账单中的诊疗项目、药品代码和费用,简化保险报销流程。
-
法律文件审阅:在大量的法律文书中快速定位关键条款,如责任限制、保密协议和违约条款,极大提升律师的工作效率。 -
政务服务:自动处理市民提交的各类申请表(如营业执照、户籍证明),提取关键个人信息和申请事项,实现“一网通办”。
-
单据处理:自动从提单、装箱单、采购订单和发票中提取货物描述、数量、收货地址等信息,实现供应链全程的可视化和自动化。
-
简历筛选:自动从海量简历中提取候选人的姓名、教育背景、工作年限、技能特长等信息,并结构化存入数据库,实现人才的快速匹配与筛选。
-
文献分析:从学术论文中自动提取标题、作者、摘要、关键词和研究方法,帮助研究人员快速进行文献综述和知识发现。
-
规则为骨架,AI为血肉:对于格式非常固定的部分使用规则,对于语言理解要求高的部分(如从一段描述中提取关键责任条款)使用NLP模型。 -
AI初步识别,规则精细加工:由机器学习模型粗略地定位和分类字段,再由规则引擎进行精确的提取和标准化。 -
人机协同循环:系统对置信度低的提取结果进行标记,交由人工复核。这些人工反馈的数据又可以用来重新训练模型,使其不断进化,变得越来越聪明。