

-
结构复杂性:藏文字符以“基字”为中心,上下可叠加“元音符号”、前加字、后加字、再后加字,形成纵向叠加的“字丁”。 -
字符相似性:许多字符间形态高度相似,仅靠细微笔画差异区分。 -
字体多样性:存在乌金体、乌梅体等多种印刷体和手写体,风格迥异。 -
文本行粘连:传统印刷中,字丁之间的基线粘连增加了准确切分的难度。
-
灰度化与二值化:将彩色图像转换为灰度图,再通过阈值算法将文字与背景分离,形成黑白二值图像。 -
噪声去除:使用滤波技术消除扫描或拍摄过程中产生的噪点、污渍。 -
倾斜校正:检测并矫正文本行的倾斜角度,确保文本水平。
-
行切分:通过投影轮廓分析或连通域分析,将整页图像分割成独立的文本行。 -
字丁切分:由于藏文字丁的纵向叠加和基线粘连,这是最大难点。通常采用投影分析法、连通域分析法或更先进的深度学习分割网络,来精确地定位和分离出每一个独立的“字丁”。
-
结构特征:提取笔画的端点、交叉点、轮廓、方向等几何特征。 -
统计特征:如图像矩、像素分布密度等。 -
深度学习特征:利用卷积神经网络自动学习并提取图像中的深层、抽象特征,这是当前主流且效果最佳的方法。
-
基于传统分类器的方法:如支持向量机、结合CNN的特征提取器,对单个字符进行分类。 -
基于时序模型的方法:采用“CRNN + CTC”的端到端架构。CRNN(卷积循环神经网络)首先提取图像特征序列,然后由RNN学习序列上下文信息,最后通过CTC(连接时序分类)输出对齐的字符序列。这种方法无需精确切分,尤其适合处理粘连文本,已成为研究热点。
-
字典匹配:将识别结果与藏文词典进行比对,纠正可能的拼写错误。 -
语言模型:利用N-gram或神经网络语言模型,根据上下文的概率关系,纠正不符合语法或常用习惯的错误,例如,纠正 "ཀྲུང་ཧྭ" 为正确的 "ཀྲུང་ཧྭ"(中国)。 -
规则库:根据藏文正字法规则,对特定搭配进行校正。
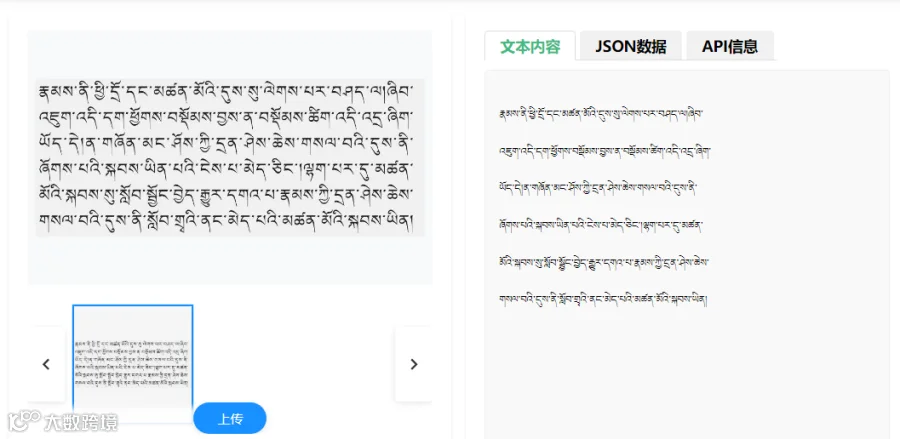
-
建立“藏文古籍文献数字化档案馆”。通过高速扫描仪或高分辨率相机获取古籍、经书、历史档案的图像,利用藏文识别技术将其批量转换为可搜索、可编辑的数字化文本。同时,构建关联知识图谱,揭示文献内容间的内在联系。
-
实现濒危文献的永久保存;极大便利学者的检索与研究,提升研究效率;通过数字化展示,让公众更便捷地接触和了解藏族优秀传统文化。
-
作业批改:学生拍摄纸质作业上传,系统自动识别藏文答案并进行正误判断。 -
点读笔与翻译:用户用手机摄像头拍摄教材上的藏文段落,App实时识别并提供汉语翻译、语音朗读。 -
资源库建设:快速将教师的纸质教案、试卷数字化,共享至教育资源平台。
-
实现个性化教学,减轻教师负担,打破教育资源壁垒,促进双语教育发展。
-
档案管理:将海量的纸质户籍档案、历史公文数字化,实现基于关键词的快速检索。 -
窗口服务:在出入境管理、社保办理等场景,通过OCR快速录入居民身份证、户口本上的藏文信息,提升办事效率。 -
公共信息处理:自动识别并录入各类调查问卷、统计报表中的藏文数据。
-
显著提高政府办公效率,推进“一网通办”,为藏族群众提供更便捷、精准的公共服务。
-
内容审核:自动识别社交媒体、新闻平台上的藏文内容,配合NLP技术进行合规性审查,净化网络空间。 -
搜索与推荐:识别图片中的藏文,使其能够被搜索引擎索引,提升图片搜索的准确性。 -
无障碍服务:为视障人士开发“藏文读屏”功能,实时识别并语音播报手机相机捕捉到的藏文文本。
-
增强互联网平台的内容治理能力,改善用户体验,促进信息无障碍流通。