

-
格式多样性:不同银行、不同渠道(网银、柜面、回单)生成的流水格式各异,表格、纯文本、带水印的图片PDF等形态并存。 -
语言与表述灵活性:交易摘要(附言)使用自然语言描述,简写、俚语、行业术语、模糊表述(如“转账”、“消费”)普遍存在,同一语义有多种表达方式。 -
专业性与领域特性:涉及大量金融专属名词、账户编码、特定业务类型(如“银承”、“贴现”)。 -
噪音与变形:扫描件中的识别错误、版式扭曲、无关印章文字干扰等。 -
传统方法(如正则表达式、模板匹配、基于CRF的序列标注模型)严重依赖人工定义规则和特征工程,开发维护成本高,且对未见过的新表述或格式泛化能力差。
-
微调(Fine-tuning):将预训练好的大模型(如BERT、RoBERTa、DeBERTa或金融领域预训练模型如FinBERT)在已标注的银行流水数据集上进行有监督微调,将其适配为序列标注(用于抽取实体,如金额、日期)、文本分类(用于判断交易类型)或阅读理解(通过问答形式定位答案)等下游任务模型。这是当前最主流且效果显著的方法。 -
提示工程与少样本/零样本学习(Prompt Engineering & Few-shot/Zero-shot Learning):利用如GPT系列等生成式大模型,通过精心设计的自然语言提示(Prompt),引导模型直接生成或识别所需的关键字段内容。这种方式无需或仅需极少量标注样例,展现了强大的泛化与适应能力,尤其适合标注数据稀缺或格式频繁变化的场景。 -
多模态信息抽取:对于扫描件或图片流水,结合视觉大模型(如ViT)与语言大模型,构建多模态理解系统(如LayoutLM、Pix2Struct),同时利用文本、布局、视觉特征进行联合理解,显著提升从复杂版式中抽取信息的准确性。
-
强大的语义理解与泛化能力:能理解“向张三转账”、“支付给李四货款”、“张三收款”本质均为“对手方”为“张三”的交易,减少对表面字符串的依赖。 -
上下文感知:能依据上下文消歧义,例如判断“余额”是交易前余额还是交易后余额,识别跨行或跨页的关联信息。 -
减少特征工程依赖:模型自动学习文本中与任务相关的深层次特征,降低了人工设计复杂规则和模板的成本。 -
处理复杂格式与噪音的鲁棒性增强:通过预训练获得的对噪声文本的容忍度,能更好地应对OCR错误或非标准表述。
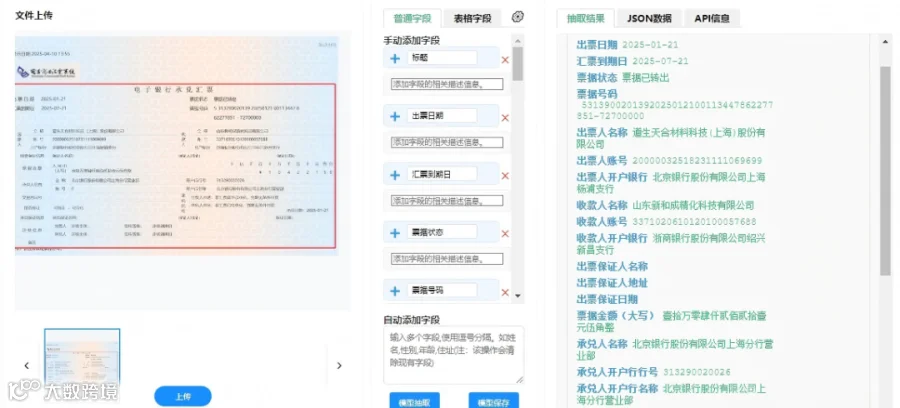
-
对PDF、图像等非结构化文档,使用OCR技术(可结合大模型提升OCR后矫正效果)转化为统一文本。 -
文档结构与字段定位:识别流水文本的逻辑区域(如表头、交易条目、表尾),定位各关键字段的大致位置。大模型可以通过序列标注或目标检测(多模态场景)完成。
-
结构化字段:如“交易日期”、“记账金额”、“余额”等,通常格式相对固定,微调后的模型能以极高准确率抽取。 -
半结构化/非结构化字段:如“交易摘要”、“对手方名称”、“对手方账号”。这是大模型最能发挥优势的领域。通过微调或提示学习,模型能理解摘要中蕴含的交易类型(餐饮、工资、报销)、业务性质(贷款发放、保费代扣)、对手方实体,并进行归一化输出。 -
关联与归一化:将抽取出的离散字段进行关联,形成完整的交易记录。并对抽取结果进行规范化(如日期格式统一、对手方名称清洗、交易类型标准化编码)。