

-
版式千差万别:不同银行、甚至同一银行不同时期的流水单格式各不相同,表头、列宽、字体均不统一。 -
结构复杂多样:包含合并单元格、跨页表格、嵌套表格以及手写备注等半结构化或非结构化信息。 -
图像质量参差不齐:扫描件可能存在倾斜、模糊、光照不均或印章遮挡文字等情况。
-
在识别之前,系统首先通过图像处理技术解决原始文件的质量问题。针对银行流水常见的扫描件倾斜、模糊、光照不均或带有印章干扰等情况,系统采用自适应去噪、倾斜校正和对比度增强算法,净化图像环境,为后续高精度识别奠定基础。这一步骤确保了无论是手机拍照的流水单,还是传真扫描的复印件,都能达到可识别的标准。
-
表格区域定位:利用改YOLO目标检测模型,系统能够快速从复杂的文档版面中精准定位表格区域,将其与周围的纯文本、页眉页脚区分开。 -
结构重建:系统通过语义分割与图神经网络,精确解析表格的内在逻辑。它不仅能识别实线、虚线等显式框线,还能通过文本的对齐方式和空间分布,推测出无线表或仅通过空白分隔的半结构化表格的行列关系。针对银行流水中常见的跨行合并(如摘要栏)、跨列合并(如“对方户名”拆分为名称和账号)等复杂表头,以及跨页表格的连续性,系统都能准确还原单元格的边界与合并状态。
-
在明确每个单元格的位置和范围后,系统启用高精度OCR引擎进行文字识别。该引擎针对金融场景进行了专门优化,对打印体、手写体、数字、日期及货币符号均有很强的抗干扰能力。识别并非孤立进行,系统会利用上下文感知机制,将识别出的文本“放回”对应的单元格中,确保“交易日期”、“收入金额”、“余额”等关键字段严格对号入座,不串行、不错列。
-
技术流程的最后一环是数据标准化与校验。系统将解析出的内容转换为可直接使用的结构化数据(如Excel、JSON或CSV)。在这个过程中,自然语言处理技术会对识别结果进行语义校对与逻辑校验。
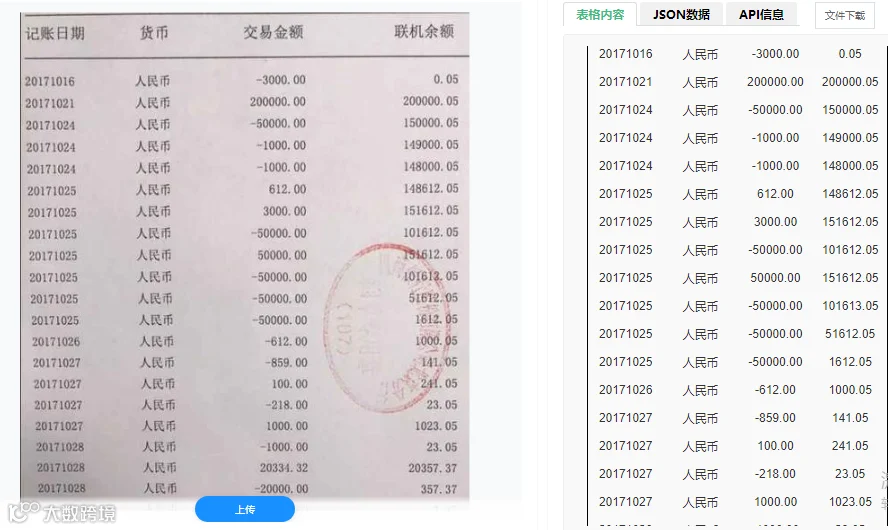
-
企业财务自动化:企业每月需处理来自多家银行的回单和流水。通过系统自动扫描或上传,即可秒级生成结构化电子数据,直接导入ERP系统,加速月结和报税流程。 -
审计与对账:审计师在抽凭和函证替代测试中,面对海量银行流水,利用该技术可快速完成数据采集,将精力集中在数据分析与风险判断上,而非机械的数据录入。 -
信贷风控:在中小微企业信贷场景中,银行需要通过企业流水评估经营状况。实时、准确的流水识别与分析,能帮助信贷员快速识别虚假流水,提升放贷效率与风控水平。
-
效率提升:录入效率提升10倍以上,分钟级完成百页级流水处理。 -
准确率跃升:结合深度学习与后期的校验逻辑,关键字段识别准确率可达99.5%以上。 -
流程优化:释放财务人员与业务人员从“表哥表姐”的数据搬运工作中解脱出来,转向更高价值的数据分析与决策支持。