

-
OCR(光学字符识别):负责将图像中的文字区域检测并转换为可编辑的文本内容,同时保留文字的位置、顺序等版面信息。 -
大模型数据抽取能力:在OCR输出的文本基础上,根据用户定义的字段规则,理解文档语义和版面结构,准确识别并提取目标信息。 -
两者形成“识别+理解”的链路:OCR解决“图像里有什么字”的问题,大模型解决“这些字里哪个是我需要的字段”的问题。
-
图像预处理:对倾斜、模糊、光照不均的原始图像进行校正、二值化、降噪等处理,提高后续识别的准确性。 -
文字检测:定位图像中所有包含文字的区域,输出每个文字块的边界框坐标。 -
文字识别:对每个文字块内的字符序列进行识别,转换为计算机可读的文本字符串。 -
版面分析(部分系统具备):判断文字块属于标题、正文、表格还是落款,为后续字段定位提供线索。
-
语义理解:大模型经过海量文本训练,具备对自然语言的深层理解能力。它能识别出“统一社会信用代码”与“社会信用代码”“信用代码”等变体表述指向同一实体。 -
上下文推断:即使字段标签与目标值不在同一行或同一表格内,模型也能根据相对位置、邻接文本等上下文线索进行推断。例如,在证照中,发证日期通常位于“发证日期:”标签的右侧或下方不远处。 -
少样本泛化:这是文档抽取技术的核心优势之一。用户无需标注数千张样本,仅需提供少量(例如5-10张)典型证照图像,并标注需要抽取的字段位置,模型即可从中学习该类证照的版面规律和语言模式。这一能力建立在预训练大模型的迁移学习基础上——模型先在广泛多样的文档数据上进行预训练,再通过少量特定证照样本进行微调。
-
上传样本:提供少量同一类型证照的图像文件(如5张不同企业的营业执照扫描件)。 -
定义字段:以自然语言方式声明需要抽取的字段名称,例如“企业名称”“统一社会信用代码”“成立日期”“经营范围”。 -
标注示例(可选):在样本图像上框选每个字段对应的文字区域,作为模型的参考示例。
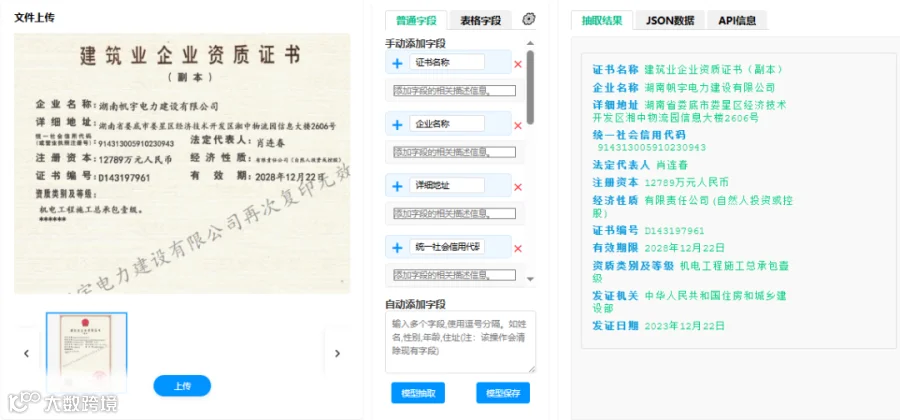
-
用户需上传5至10张典型的营业执照样本图像,系统接收后将其作为模型适配的数据集。 -
用户在界面中配置需要抽取的字段,例如“统一社会信用代码”“企业名称”“法定代表人”等,系统记录字段名称及对应的标注位置。 -
系统基于这些少量样本对预训练大模型进行快速微调,完成针对当前证照类型的抽取能力适配。 -
用户批量上传待处理的证照图像,系统依次执行OCR识别和大模型抽取。 -
系统将抽取结果以JSON、CSV或Excel等结构化格式输出字段与值的对应关系。