
-
该智能文档抽取系统采用分层架构设计,自下而上依次为:图像预处理层、高精度OCR识别层、文档语义理解层与结构化信息输出层。其中,OCR识别层与语义理解层通过特征对齐模块实现深度融合,而非简单的串联关系。
-
合同文档的版式复杂多样,包含印刷体、手写体、印章覆盖文字、表格、多栏排版等多种情形。系统采用基于深度学习的端到端OCR模型,结合图像增强与版面分析算法,实现对非结构化文档的高保真文本提取。 -
具体而言,OCR模块首先通过卷积神经网络对文档图像进行版面分割,识别文本块、表格、印章等区域;随后采用多方向文本检测算法定位文本行,并利用注意力机制的序列识别网络完成文字转录。对于印章覆盖、低对比度等难点场景,系统引入了图像复原与纹理增强的预处理机制,有效提升了识别的鲁棒性。
-
领域自适应预训练:使用大规模合同文本语料,对基座大模型进行持续预训练,使模型熟悉合同领域的术语体系、句式结构与逻辑框架。语料涵盖采购合同、销售合同、劳务合同、保密协议等多种类型,涉及不同行业与格式规范。 -
指令微调:构建高质量的“文档-要素”标注数据集,每条数据包含原始合同文本(含OCR识别结果)与对应的结构化要素输出。通过有监督的指令微调,使模型学习从非结构化文本中定位并抽取指定要素的能力,如合同主体、签约金额、履约期限、违约责任等。
-
OCR识别的精度直接影响要素抽取的准确性。文档抽取系统采用特征级融合策略,将OCR模型输出的文本内容、字符级置信度、版面位置信息以及文本行间的空间关系,共同编码为多模态输入,送入语言模型进行处理。 -
这种融合方式使语言模型能够在语义理解过程中,充分利用版面信息与识别置信度,对于OCR低置信度的区域,模型会结合上下文进行推断与修正,从而在一定程度上弥补单一OCR识别的不足。
-
签约主体:甲方、乙方的完整名称、统一社会信用代码、地址、联系方式 -
合同标的:产品或服务名称、规格、数量 -
金额条款:合同总金额、付款方式、付款节点、发票信息 -
时间要素:合同生效日、终止日、履约期限、质保期 -
法律条款:违约责任、争议解决方式、管辖法院、保密义务
-
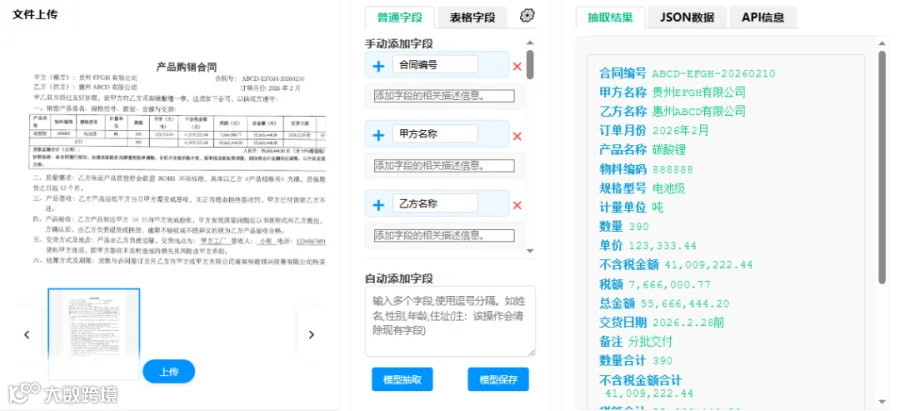
文档解析:调用OCR模块对文档图像进行识别,输出文本内容、位置信息与版面结构。 -
文本重建:根据版面分析结果,将OCR输出的文本块按照阅读顺序重建成连贯的文本流,同时保留表格等复杂结构的原始组织形式。 -
语义理解:将重建后的文本与版面信息输入微调后的大语言模型,模型依据预设的要素定义,逐项定位相关段落与句子,抽取对应的值。 -
结果校验:对抽取结果进行规则级校验,如金额格式校验、日期有效性校验、主体名称规范性校验,对疑似错误项进行标注以供人工复核。 -
结构化输出:将抽取结果以JSON、XML或Excel格式输出,便于对接下游业务系统。
-
效率提升:单份合同的要素抽取时间从人工的5-10分钟缩短至秒级,支持批量并发处理。 -
准确性保障:减少因疲劳、疏忽导致的人为差错,尤其在处理大量同类合同时,系统输出的稳定性优于人工。 -
数据沉淀:将非结构化的合同文档转化为结构化数据,为企业合同管理、风险分析与经营决策提供数据基础。