
DeepSeek-V4 的推理速度迎来了显著提升。在模型架构不变的前提下,token 生成速度直接提升了 60% 至 85%。
6 月 27 日,北京大学与 DeepSeek 联合发布了推理加速框架 DSpark。该方案可被视为为大模型安装了“涡轮增压”系统:无需更换引擎,即可满负荷释放算力。目前,相关论文、训练代码及模型权重已基于 MIT 协议全部开源。

目前,DSpark 已部署至 DeepSeek-V4-Flash 和 DeepSeek-V4-Pro 预览版的线上服务中。用户近期感受到的回复提速,正是源于此项技术升级。
推测解码:大模型加速的核心原理
大模型生成文本需逐字计算,每输出一个字符都需完整运行一次模型,这是导致响应延迟的根本原因。业界主流的加速方案为“推测解码”:利用一个小而快的“草稿模型”预先猜测一串字符,再由大模型一次性验证。若猜测正确则直接采纳,错误则重新生成。
由于大模型“验证多个字符”的时间成本与“生成单个字符”几乎相当,只要草稿模型准确率足够高,单轮即可确认多个 token,从而大幅提升速度,且保证输出质量零损耗。
DSpark 的技术突破
尽管主流并行草稿模型(如 DFlash)能同时预测多个字符,但因缺乏上下文关联,容易出现连贯性偏差。此外,无效验证在高并发场景下会严重抢占 GPU 资源。针对上述痛点,DSpark 从“猜得更准”与“验证更聪明”两个维度进行了优化。
半自回归架构:提升预测准确度
DSpark 采用“半自回归”架构:先通过并行骨架网络生成初始预测,再叠加极轻量的序列模块,使后续 token 能够感知前序 token 的预测结果,实现“先集体猜测,再逐个修正”。
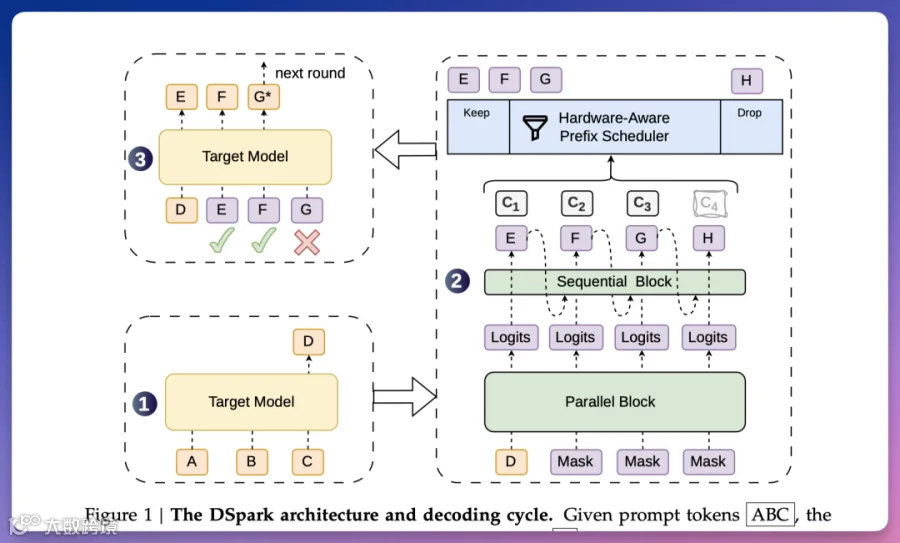
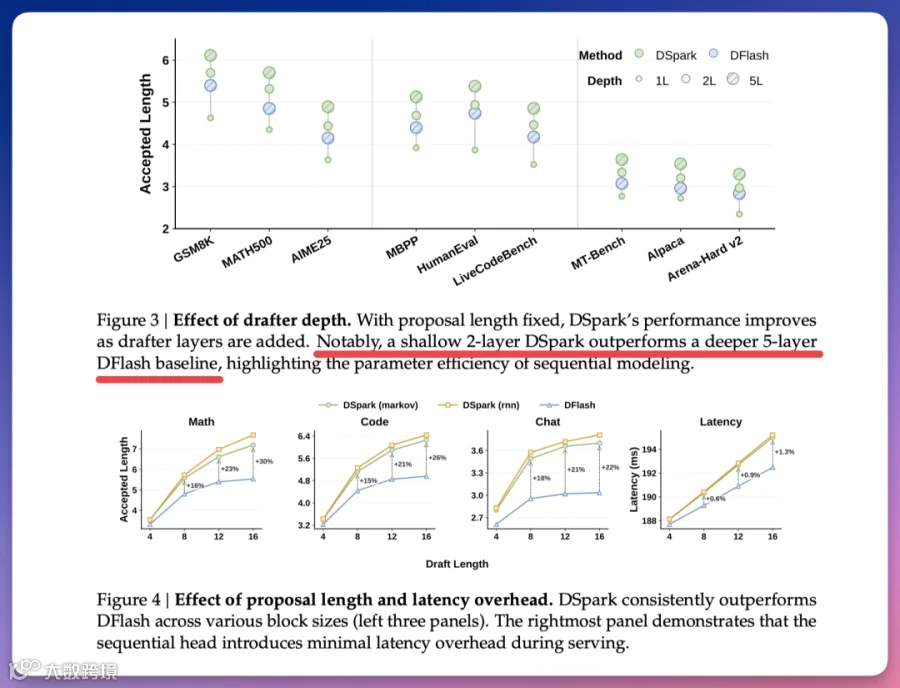
实测数据显示,仅含 2 层的 DSpark 在准确度上超越了 5 层的 DFlash。其修正模块带来的额外延迟仅为 0.2% 至 1.3%,几乎可忽略不计。
动态置信度打分:优化验证效率
DSpark 摒弃了无差别验证策略,引入置信度打分模块,预判每个草稿 token 被大模型接受的概率。系统可根据当前负载动态调整验证数量:GPU 空闲时多验证,高负载时仅验证高把握的 token,从而将计算资源优先分配给其他任务。
性能表现与应用前景
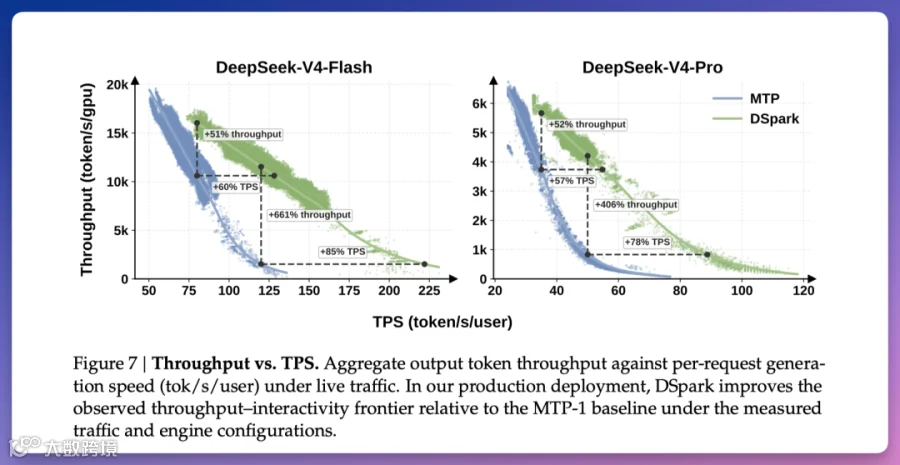
相比此前生产环境使用的 MTP-1 方案,在同等吞吐量下,DeepSeek-V4-Flash 的单用户生成速度提升 60% 至 85%,DeepSeek-V4-Pro 提升 57% 至 78%。在极端高并发场景下,整体吞吐量提升幅度甚至超过 400%。
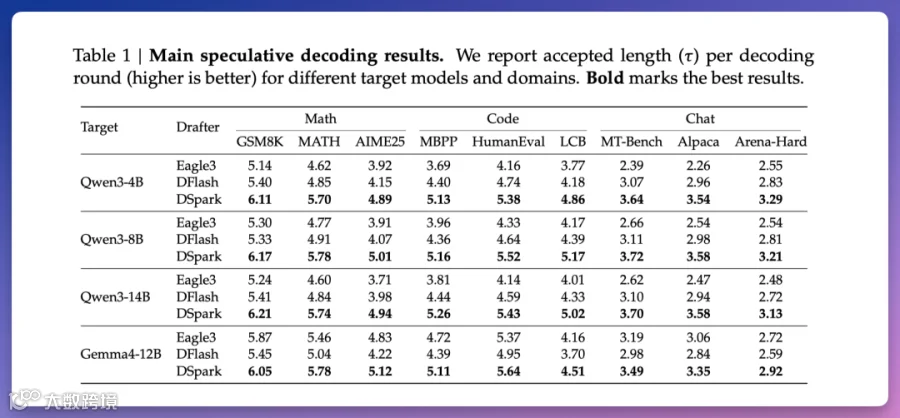
离线测试表明,DSpark 在数学、代码及对话领域全面超越 Eagle3 和 DFlash。以 Qwen3-4B 为例,其每轮验证通过的 token 数较 Eagle3 多出 30.9%,较 DFlash 多出 16.3%。该方案不仅适用于 DeepSeek 自家模型,在 Qwen3 和 Gemma4 系列模型上同样表现最佳。
面对日益高昂的 AI 推理成本,DSpark 提供了一种高效解决方案:无需训练新模型或更换硬件,仅在现有 GPU 上即可实现显著提速。第三方数据显示,DeepSeek 已成为 6 月增长最快的 AI 软件供应商,覆盖超 5 万家企业支出记录。
目前,DSpark 全套代码及模型权重(DeepSpec 仓库)已开源,开发者可通过以下链接获取:
DeepSpec GitHub 代码库:https://github.com/deepseek-ai/DeepSpec
DSpark 论文地址:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
DeepSeek-V4-Pro-DSpark 模型下载:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro-DSpark