
最新科技资讯
价值前沿VF公众号

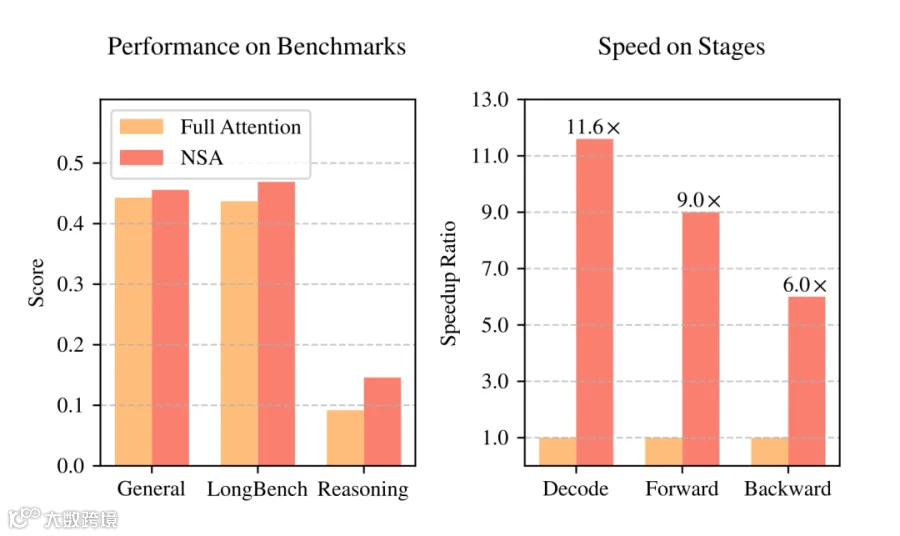
DeepSeek发布NSA技术!
与传统注意力机制有何区别?
如果你觉得这篇文章有价值,
别忘了点赞、转发,关注我,
获取更多深度行业分析!


来源:价值前沿VF公众号
声明:文章部分图片源自网络和AI生图,仅供参考,如有侵权问题请联系作者删除。文章部分预测来自AI分析,本文内容不构成投资建议,仅作为研究参考,据此操作,风险自担!
 价值前沿VF
价值前沿VF
最新科技资讯
价值前沿VF公众号
DeepSeek发布NSA技术!
与传统注意力机制有何区别?
如果你觉得这篇文章有价值,
别忘了点赞、转发,关注我,
获取更多深度行业分析!
来源:价值前沿VF公众号
声明:文章部分图片源自网络和AI生图,仅供参考,如有侵权问题请联系作者删除。文章部分预测来自AI分析,本文内容不构成投资建议,仅作为研究参考,据此操作,风险自担!