


-
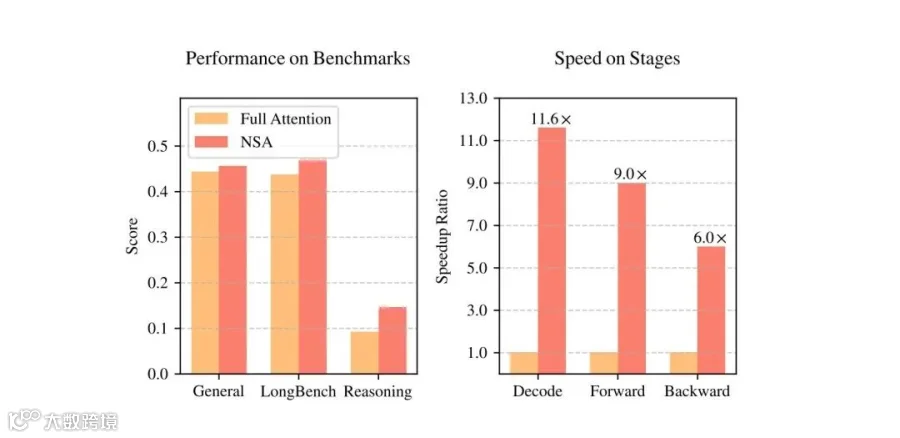
左图:尽管 NSA 是稀疏的,但它在通用基准测试、长上下文任务和推理评估中的平均表现超越了全注意力基线模型; -
右图:在处理 64k 长度的序列时,NSA 在解码、前向传播和后向传播的所有阶段都实现了显著的计算加速,相比全注意力模型效率大幅提升;

-
固定模式:比如只关注文本的开头或结尾(下沉注意力),或者只关注附近的一小段文本(窗口注意力)。但这些方法的问题是,它们假设某些部分更重要,忽略了其他可能的关键信息。 -
简化计算:比如用线性近似代替复杂的注意力计算。虽然这样计算更快,但在处理复杂任务时,效果可能不如人意。
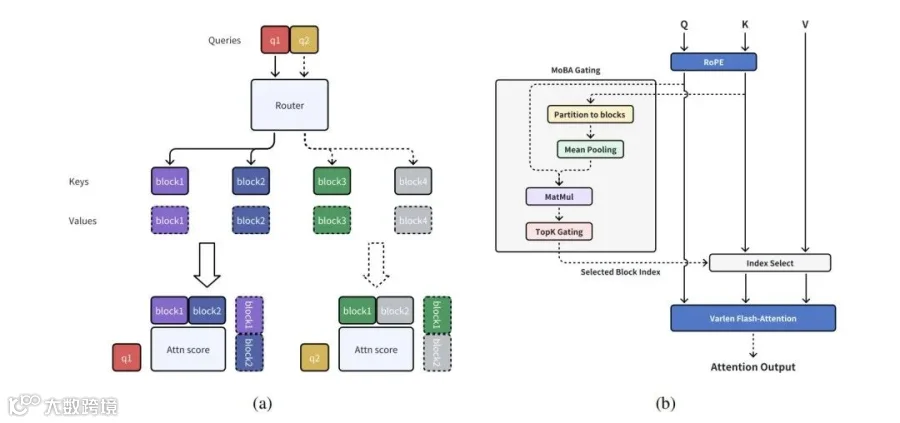
-
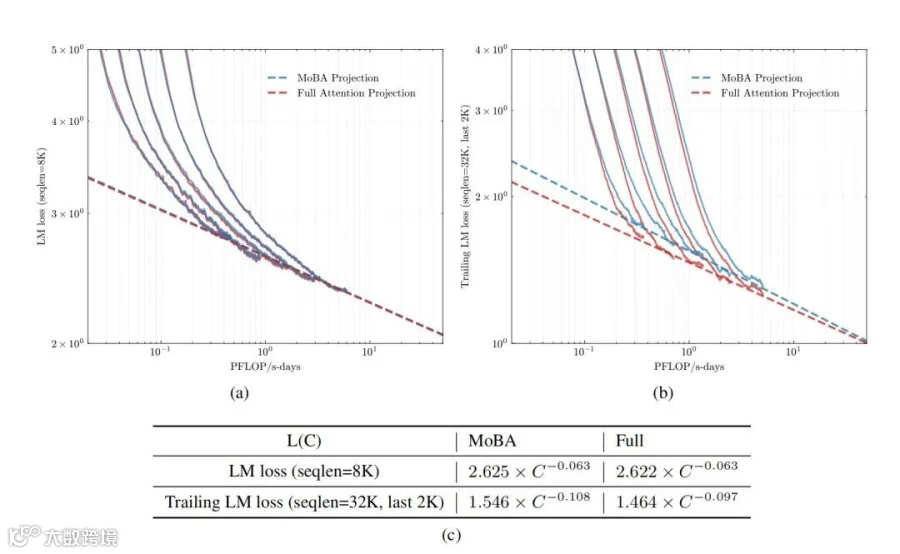
(a) 子图:展示了在序列长度为 8K 时,验证集上的语言模型损失随着 PFLOP/s - days(一种计算量单位)的变化趋势。可以看到随着计算量的增加,两种方法的语言模型损失都在下降,且 MoBA 和全注意力机制的曲线较为接近。 -
(b) 子图:显示了在序列长度为 32K 且只关注最后 1K 个标记时,验证集上的尾随语言模型损失随 PFLOP/s - days 的变化。同样,随着计算量上升,损失下降,两者曲线有相似的下降趋势。 -
(c) 表格:给出了拟合的缩放定律曲线公式。这些公式可以用于预测在不同计算资源(C)下的损失情况。
中矿金程(北京)软件工程研究院有限公司
联系电话:010--62322196
地址:北京海淀清华东路16号3号楼1001室
网址:www.zkjc.com.cn