

本文作者:大吉——词元无限FDE专家
这段时间,我在整理一个很典型的 AI Coding 项目。项目早期大量使用 Claude Code、Codex 来推进开发。页面、接口、工具函数、单元测试,很多都是在人给出需求之后,由 AI 参与生成的。
坦率讲,如果只看交付结果,效果并不差。页面能打开,按钮能点击,接口有返回,主要流程也能走通。站在产品验收的角度,它不是那种一眼就露馅的 demo。再往代码里看,也不乱。变量命名清楚,函数拆分规整,注释写得完整。单独打开任何一个文件,甚至会觉得它很专业。它不像传统印象里的屎山代码,不是那种命名混乱、缩进错乱、复制粘贴痕迹满屏的东西。这也是 AI Coding 最容易让人放松警惕的地方。它先给你一个能跑的功能,再给你一份看起来整洁的代码。
但当我沿着业务链路继续往下读,问题开始浮现。同一个字段,在接口层已经校验过一次,到了 service 层又校验一次,进入组件后还要再判断一次。项目里已经有统一的时间格式化方法,它又重新实现了一套。权限、日志、错误处理都有公共能力,它仍然会在局部模块里补出一套看似合理的替代方案。这些代码不是随手乱写出来的。恰恰相反,它们很像 AI Coding 最容易生成的那类代码。功能大体成立,局部逻辑完整,边界条件看起来考虑充分,但放进一个长期演进的系统里,就开始制造另一种复杂度。
Tokfinity
# 01
AI Coding 最先交付的是可用感
过去我们聊 AI Coding,常常先问它能不能写代码。今天这个问题已经没那么关键了。GitHub Copilot、Cursor、Claude Code、Codex、Jules 这些工具,都已经不只是补全几行代码。它们可以读仓库、写计划、改文件、跑测试,甚至提交一组完整 diff。AI Coding 正在从「帮你写一段」走向「替你完成一个任务」。
这当然是进步。它让一个人更快做出后台页面,更快补齐接口,更快迁移旧逻辑,更快验证一个产品想法。尤其是内部系统、运营工具、数据面板、CRUD 这类场景,效率提升非常直接。
所以我并不想把 AI Coding 描述成一种危险技术。真正需要讨论的是,为什么它明明让功能更快可用了,团队反而还需要治理。
答案就在「可用感」这三个字里。一个功能能跑,不代表它已经进入了系统秩序。一个接口有返回,不代表它复用了正确的公共能力。一个页面看起来正常,不代表权限、日志、异常、边界状态都落在了团队原本的工程约定里。
代码生成速度提高之后,原本可以在人工编码过程中慢慢暴露的问题,会被 AI 在几分钟内放大。需求不清晰,它会自行补全假设。项目规则没有显式化,它会按照通用经验发挥。公共能力没有被准确暴露,它会重新造轮子。AI 提高了生产速度,也提高了冗余进入系统的速度。
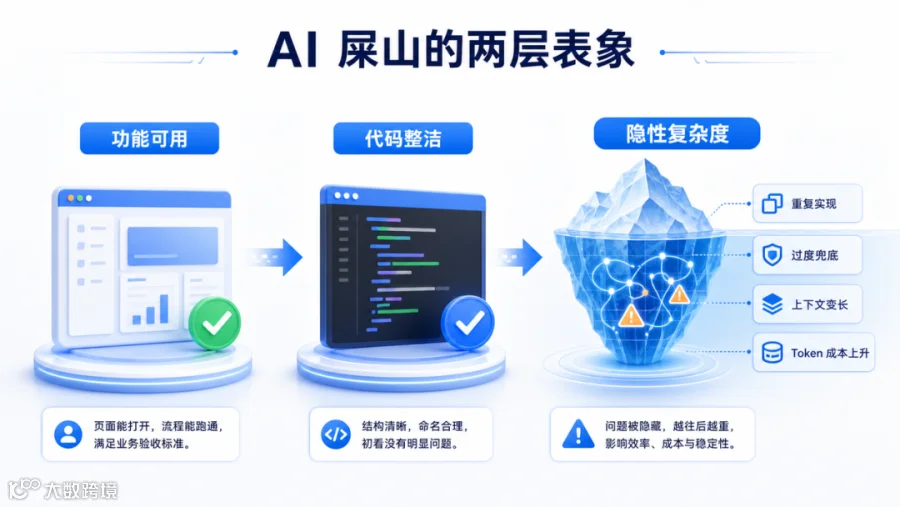
# 02
传统屎山是混乱,AI 屎山是过度合理
传统屎山代码通常来自长期堆积。业务不断变化,团队不断换人,deadline 不断压缩,很多临时方案来不及回收,慢慢堆成牵一发动全身的复杂结构。它的痛苦是可见的。变量名看不懂,模块边界不清楚,历史逻辑没人敢删,某个 if 分支背后可能藏着三年前一个客户的特殊需求。
AI 屎山不一样,AI 屎山更像有条理地膨胀。AI 很擅长写出局部合理的代码。它会补异常处理,会加 fallback,会写兼容逻辑,会为每一个潜在分支准备解释。站在单个函数的角度看,这些处理都不荒谬,甚至显得谨慎。
问题在于,软件系统不是单个函数的集合。接口入站已经完成 schema 校验,业务层就不应该继续把所有字段当成不可信。权限已经在统一中间件中处理,页面层就不应该再复制一套判断。日期、日志、错误码已经有公共封装,局部模块就不应该再生成风格相近但语义不一致的新实现。
AI 很容易在缺乏上下文时,把「谨慎」写成「冗余」。这类冗余短期看起来无害,长期却会改变系统语义。一个永远不会发生的 null 判断,会让新同事以及新的Coding Agent窗口误以为这里真的可能为空。一个为了不存在的历史版本保留的兼容分支,后续会被当成真实约束继续维护。一个重复实现的 formatDate,会让项目里逐渐出现三四种日期格式。
如果压缩成一张表,大概是这样:

所以,治理 AI 屎山不是在否定 AI Coding。恰恰相反,正因为 AI Coding 生成得快、交付得快、看起来也足够专业,团队才需要更早把规则、边界、复用、测试和 review 放到流程前面。
没有治理,AI Coding 会把短期效率变成长期复杂度。
# 04
根源不是 AI 不会写,而是它缺项目语境
围绕 AI Coding,过去一段时间有一种很有吸引力的说法,软件开发成本会趋近于零。
这个说法有一部分是对的。AI 确实显著降低了从 0 到 1 的原型门槛。一个页面、一个接口、一个 demo、一个内部工具,以前可能需要半天甚至几天,现在几轮对话就能看到可运行版本。
但软件开发不等于代码生成。一个按钮能点击,不代表业务流程正确。一个接口能返回数据,不代表它能承受真实边界。一个 demo 能跑起来,不代表它可以被长期维护、稳定部署、持续迭代。
真实的软件成本,往往出现在代码生成之后。需求澄清要成本,架构设计要成本,测试验证要成本,代码审查要成本,监控日志要成本,线上故障响应要成本,后续迭代和人员交接同样要成本。AI 降低的是局部生产成本,不是整体工程成本。
如果缺少治理,它会把成本从编码阶段转移到 review、问题排查和重构阶段。所以,真正的问题不是要不要用 AI Coding。问题是,团队有没有把 AI Coding 当成一套工程体系来建设,而不是把它当成一个无限生成代码的按钮。
# 05
把传统软件工程变成 AI 可执行的约束
避免 AI 屎山,并不意味着回到不用 AI 的时代。相反,越是相信 AI Coding 会成为主流,越需要把传统软件工程里那些被反复验证过的能力重新拿出来,并且改造成 AI 能理解、能执行、能验证的形式。
我觉得可以先做六件事:

这里最容易被低估的是项目地图和代码知识图谱。
很多 AI 重复造轮子的根源,不是它完全没被提醒,而是它找不到已有实现。关键词搜索只能解决一部分问题,因为同一个能力在项目里可能不叫同一个名字。
权限判断可能叫 checkPermission,也可能藏在 policy、guard、accessControl 里。日期格式化可能不叫 formatDate,而是封在某个 presenter 或 mapper 里。这时候,code graph 和 GitNexus 这类工具就很有价值。函数被谁调用,模块依赖方向是什么,某个 service 的上游和下游是谁,类似能力过去在哪些 PR 里出现过,这些信息如果能被 AI 检索到,它就更容易找到真实的公共能力,而不是凭语义相似度重新写一套。
落到执行上,可以给 AI 一个很明确的顺序。先用关键词找直接命中的公共方法,再用 code graph 查相邻模块和调用链,接着用 GitNexus 查历史改动、相似 PR 和模块归属。只有这些都找不到,才允许新增实现。
这会把 AI 的工作模式从「生成」调整为「融入」。
真实的软件系统不是功能片段的集合,而是一套长期生长的约定。AI 只有先理解这些约定,生成的代码才不会破坏系统的一致性。
# 06
Test 和 Review 可以更 AI Native
上面这些动作,还是偏传统软件工程。先写规格,复用公共能力,删掉多余代码,跑测试,做 review,小步提交。这些事情不会因为 AI Coding 出现而过时。
但更 AI Native 的做法,是把其中一部分动作交给专门的 Agent 来做,而不是仍然完全依赖人类手工执行。最值得优先 Agent 化的,其实就是 test 和 review。
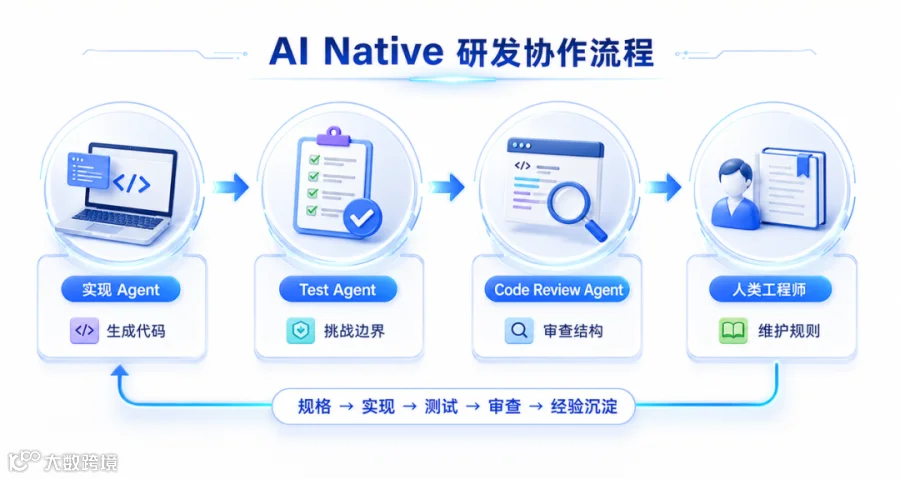
比如 Test Agent。它不是让实现 Agent 顺手补几条测试,而是让一个独立 Agent 站在验收者的位置上,根据规格文档和 diff 主动生成测试用例,补充边界条件,运行现有测试,解释失败原因,并判断失败到底来自新代码、旧测试,还是规格本身存在歧义。
实现 Agent 很容易证明自己写的代码是对的。Test Agent 的价值,是逼它面对不对的时候。接口为空怎么办。权限不足怎么办。并发提交怎么办。上游返回旧字段怎么办。用户中途取消怎么办。这些问题如果只靠实现 Agent 自己补,往往会补得过于乐观。让独立的 Test Agent 来做,是在流程里制造一种必要的对抗。
再比如 Code Review Agent。Code Review Agent 负责审查结构。它不应该替代人类工程师做最终判断,但可以先做第一轮结构性审查。有没有重复实现已有公共能力。有没有新增不必要的 fallback。有没有绕过架构边界。有没有引入没有业务路径能触发的分支。有没有把本该由上游保证的约束,又在下游重复防御了一遍。这类问题非常适合 Agent 先扫一遍,再把真正需要人判断的部分交给工程师。人类不应该把精力耗在机械检查上。人类更应该判断业务语义、架构取舍、产品边界和长期演进。
更合理的 AI Native 研发流程,不是一个 Agent 从头写到尾,而是让实现 Agent 写代码,让 Test Agent 挑战代码,让 Code Review Agent 审查结构,而人类工程师负责设定目标、维护规则、裁决冲突和沉淀经验。
# 07
AI Native 和传统软件工程不是对立面
AI Coding 的价值是真实的。它降低了原型门槛,提高了重复任务的处理效率,也让小团队具备了过去难以想象的软件生产能力。我们不会回到完全手写代码的时代,也没有必要回去。
但越是进入 AI Native 的开发方式,越不能误以为软件工程已经不重要。
事实恰恰相反。当代码生成变得便宜,真正稀缺的能力会重新回到判断、约束和维护上。谁能把业务规则写成清晰规格,谁能把团队经验沉淀成项目知识,谁能把架构边界变成机械检查,谁能让 Test Agent 和 Code Review Agent 成为稳定流程,谁能在 review 中删掉无意义的复杂度,谁就更有可能把 AI 的速度转化为系统的质量。
AI Native 不是完全放权给 AI 自由发挥。AI Native 应该是让 AI 参与生产,同时让传统软件工程中的规格、边界、测试、审查和知识沉淀变得更加显性、更加自动化、更加可复用。
这就是传统软件工程在 AI 时代的新价值。代码可以由 AI 快速生成。但系统能不能长期运转,仍然取决于人类是否愿意维护清晰的边界、真实的约束和可持续的秩序。
# 08
词元无限的产品矩阵
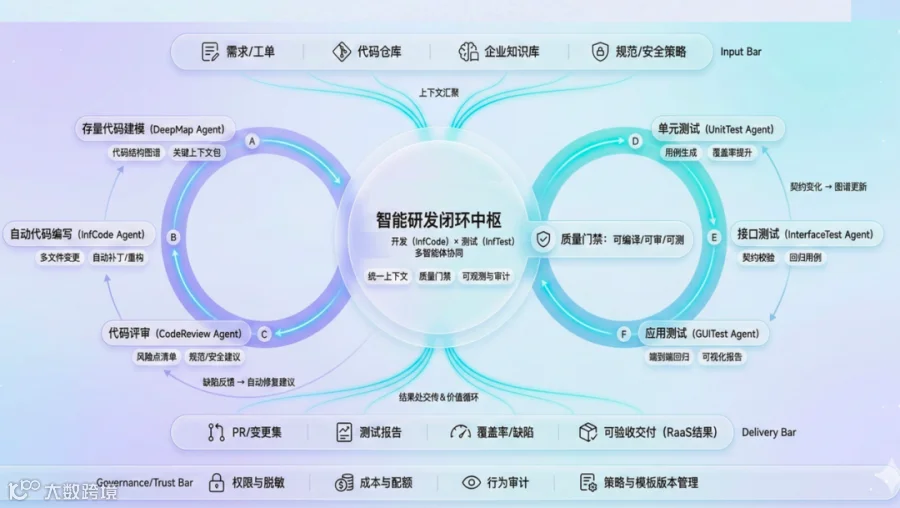
把上面这些判断落到我们自己的产品矩阵里,其实就是围绕一个目标展开。让 AI Coding 从单点生成,走向可控、可测、可审、可持续演进的研发闭环。
目前主要有以下四部分:

InfCode 负责把需求落到代码,InfTest 负责证明代码能不能站住,DeepMap 负责给 AI 提供长期项目记忆,CodeReview Agent 负责把无意义复杂度挡在主分支之外。
AI Native 研发真正需要的,不是一个会写代码的按钮。而是一套能把需求、代码、测试、审查、知识沉淀和治理策略串起来的AI Native系统。这也是我们现在真正想做的东西。
