
©作者|董梓灿,彭涵机构|中国人民大学

论文链接:https://arxiv.org/abs/2504.06792
开源链接:https://github.com/RUCAIBox/EASYEP
简介
近年来,混合专家模型凭借着强大的拓展性,已成为大模型的主流框架之一。然而,这类模型面临极高的显存开销,以 DeepSeek-R1 为例,其参数规模高达 6710 亿,在 BF16 精度下,约需 1500 GB 显存;即便在更节省的 FP8 精度下,也仍需 约 750 GB,相当于 4×8 A800 或 2×8 H800 的 GPU 集群配置。这一部署门槛凸显出:对如 DeepSeek-R1 这样的大规模 MoE 模型,探索高效的轻量化部署策略已势在必行。
在本研究中,我们分析了 大模型MoE模型 在不同领域任务中的专家激活模式,并观察到一种显著的一致性现象:仅需提供少量领域特定示例,模型便倾向于激活一个与该领域高度相关、稀疏且稳定的专家子集。我们将这一现象称为 少样本专家定位(Few-Shot Expert Localization)。MoE专家分析
我们选择了DeepSeek-R1这一代表性模型,对大模型混合专家模型的专家分布进行了分析,并发现了一种叫做少样本专家定位的现象:领域特定的专家可以用少量的实例进行定位。
不同领域专家特化
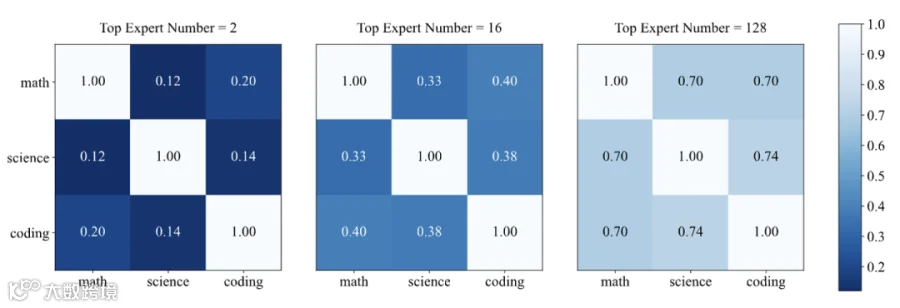
不同领域上,具有最高门控得分的专家的重合度很低。随着我们对选择的专家数量,这些高专家得分之间的重叠度增加,但是仍然有大量非重叠的专家。这说明了在DeepSeek-R1中存在领域特定的专家,仅仅在相关领域中才高度激活。
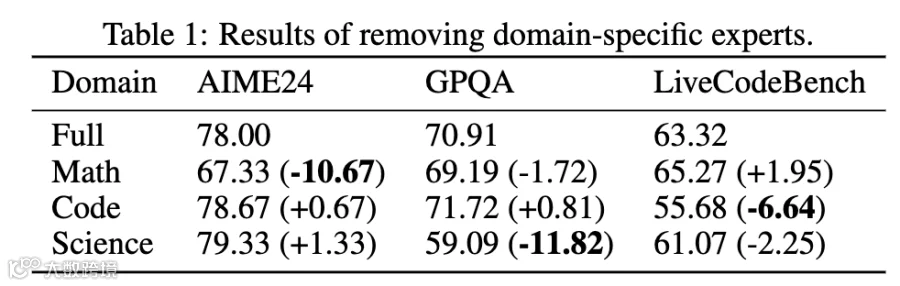
裁剪掉在仅仅某个领域具有最高的128门控得分的专家会对模型的该领域的性能产生较大降低,但是在其他领域上模型性能基本不变。这说明领域特定专家在特定领域发挥关键作用,但是在其他领域是冗余的。
同领域专家聚集
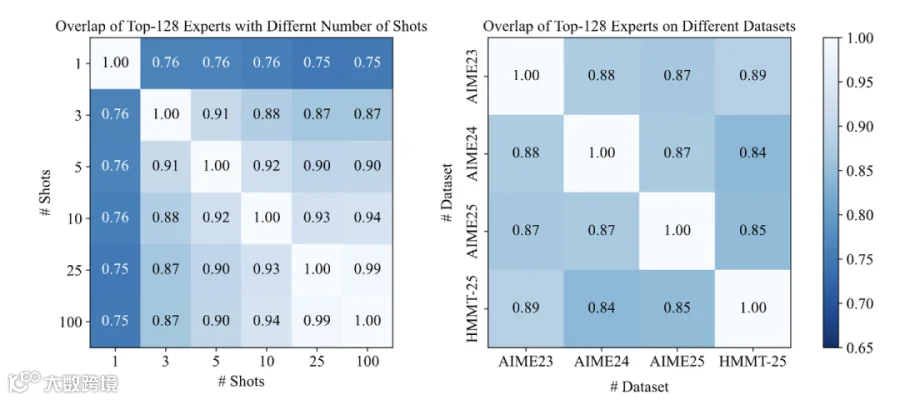
在同一个数据集中,仅仅5个样本已经可以检测到90%的相关专家。在25个样本时,选择到的专家逐渐固定,进一步增加样本仅仅能带来较小的收益。这说明了使用多样本领域特定剪枝的可行性。
此外,在同一个领域下不同数据集之间的专家重叠率很高,说明了这种同个领域下不同数据集中的关键专家保持稳定。
EASY-EP
受启发于少样本专家识别现象,我们提出了一种专家剪枝框架 EASY-EP,以降低大规模 MoE 模型的内存开销。给定一个来自目标领域的小规模示例集,我们将其输入 MoE 模型中进行前向传播,并收集专家激活的统计信息,综合考虑每个专家的输入和输出,以用于剪枝决策。为了有效识别大模型中的领域特定专家,我们计算所有词元上基于输出的专家重要性分数和面向专家粒度的词元贡献度的乘积之和,以此来评估每个专家的重要程度:
此外,我们的方法还支持混合领域裁剪,通过将不同领域的专家得分在归一化后进行平均来评估多领域下专家的重要性:
以下是EASY-EP的总体流程图:
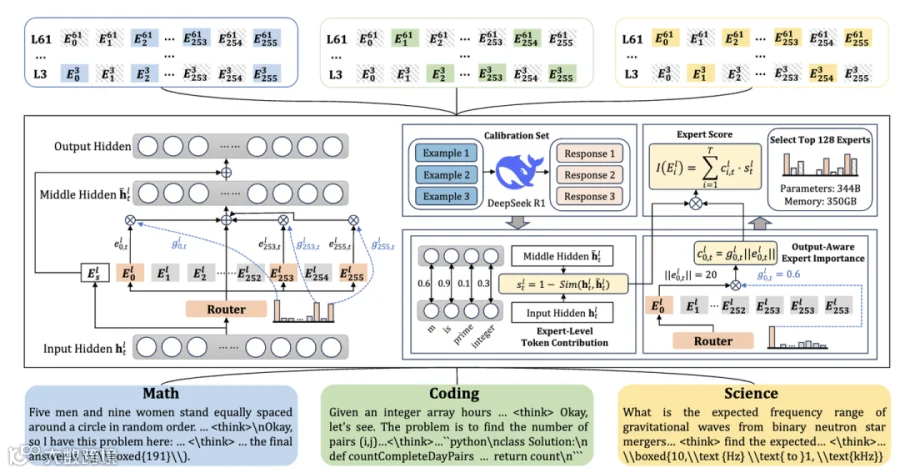
基于输出的专家重要性评估
为了评估每个专家的重要性,我们对路由专家模块的输出进行分解分析,并据此推导其输出的 L2 范数上界。
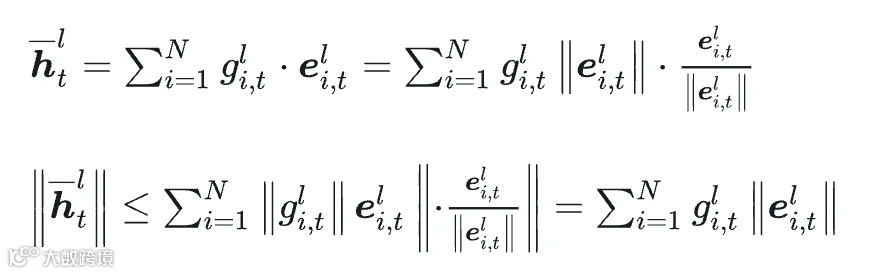
我们发现,对于当前词元,具有最大门控值与专家输出模长乘积的专家,其对 L2 范数上界的影响最大。因此,我们将该乘积作为衡量当前词元下专家重要性的估计指标,具体如下:
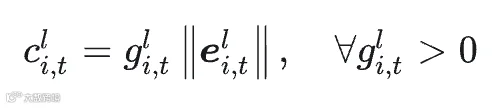
面向专家的词元贡献评估
在混合专家模型的残差路径中,路由专家模块对隐状态的影响程度各不相同,具体表现为隐状态在进入与经过专家模块前后的相似度变化差异。其中,对于相似度变化较大的情况,说明该专家模块对当前词元的表示产生了较强的干预;反之,相似度变化较小则意味着影响较弱。 因此,在计算每个专家的最终重要性得分时,不能简单地对所有词元的贡献进行平均处理,而应根据不同词元在该专家层中的实际影响程度进行加权评估。 为此,我们提出了一种基于相似度变化的词元贡献评估方法。具体而言,给定路由专家模块前后的隐状态表示,我们计算两者的余弦相似度与1之间的差值,将该差值作为衡量当前词元在该专家层中贡献程度的指标:
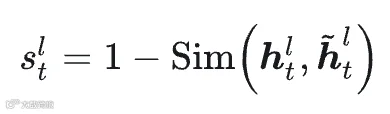
实验
专家裁剪性能评估
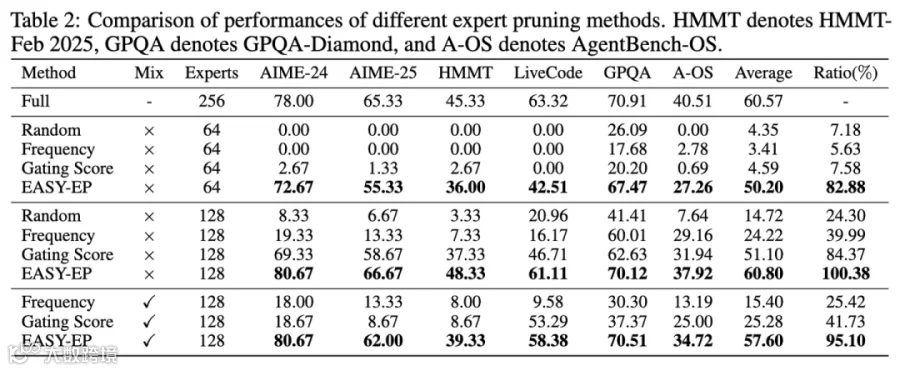
我们评测了我们的方法在不同设置下(领域特定、混合领域)的效果,结论如下:
我们的方法在所有设定下超越了基线方法,并在仅保留一半专家的条件下达到了和满血R1相媲美的效果。
我们的方法在较大压缩率的设定下仍然能够保证较好的性能,在仅仅保留64个专家的条件下能够达到满血模型的83%的平均性能。
我们的方法在混合领域下性能保持较好,可以达到满血模型的95%,进一步说明了多领域中存在一些专家共同作用,保证模型通用的推理能力。
分析
我们针对以下问题进行了更详细的实验和分析,完整的分析请看原论文:
EASY-EP中不同组件的影响:相比于仅仅使用门控得分,无论是加入专家输出模长还是词元贡献度都能带来性能上的提升。进一步结合两者的EASY-EP进一步提高了性能。
实例数目的影响:当仅仅使用较少样例的时候,模型会受到样本特性的影响,性能较低,随着增加样本数量,模型性能迅速提升,达到和满血模型相媲美的效果。
裁剪数据的影响:相比于使用完整的输入和模型输出的拼接,无论是只给输入、模型输出还是真实答案,都会带来性能上的下降。尤其是使用预训练数据时,模型的能力难以得到保留。这说明了模型的输入、推理和输出的范式对专家裁剪的重要性。
领域特定裁剪后模型的泛化性能:使用领域数据进行裁剪后,在其他领域上进行评测的性能降低,但是保持了一定的性能,说明了专家的领域专业化以及模型的推理能力的保留。同时,相近领域(数学和科学)裁剪后,在另一领域的性能保留更多。
吞吐率分析
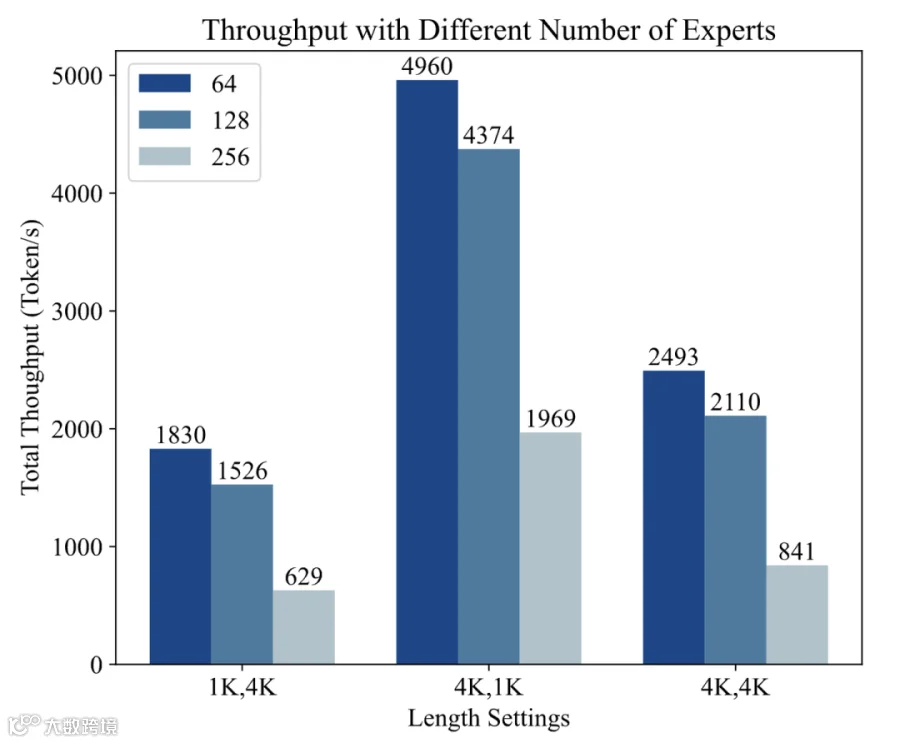
在给定两台H800的情况下,我们评测了不同输入输出长度和专家数目的吞吐率。其中,在使用192个专家及以下,可以使用单台H800进行部署,其他使用两台H800进行部署。可以看见,在专家裁剪之后,模型的吞吐率发生了较大的提升(4K输入+4K输出条件下,128和64个专家分别提升2.51和2.97倍)。此外,相比于长输入,长输出条件下,吞吐进一步提升,说明了裁剪后更轻量化的模型在R1这种longcot范式下更加适用。
完成团队
Zican Dong1, Han Peng1, Peiyu Liu2, Wayne Xin Zhao1, Dong Wu3, Feng Xiao4, Zhifeng Wang4
1. Gaoling School of Artificial Intelligence, Renmin University of China
2. University of International Business and Economics
3. YanTron Technology Co. Ltd
4. EBTech Co. Ltd