
点击上方  蓝字关注我们
蓝字关注我们

作者 | 小钻风
编辑 | 邱忠标



01
测试背景



02
Kerberos


resource.storage.type 开启kerberos 需要指定文件存储格式hadoop.security.authentication.startup.state 是否开启kerberos 认证java.security.krb5.conf.path kerberos5配置文件所在路径login.user.keytab.username kerberos认证的用户principal名称login.user.keytab.path 用户的keytab认证文件所在路径kerberos.expire.time kerberos 认证的过期时间

03
准备测试环境
修改 common.propertis 文件
#......# resource store on HDFS/S3/NONEresource.storage.type=HDFS# whether to startup kerberoshadoop.security.authentication.startup.state=true# java.security.krb5.conf pathjava.security.krb5.conf.path=D:/security/krb5/krb5.conf# login user from keytab usernamelogin.user.keytab.username=hive@BIGDATA# login user from keytab pathlogin.user.keytab.path=D:/security/keytabs/hive.service.keytab#......
配置mysql
位于 dolphinscheduler-dao/src/main/resources 目录下
spring:datasource:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://192.168.242.40:3306/dolphinscheduler_2.0.1_test?useUnicode=true&characterEncoding=UTF-8&useSSL=falseusername: bigdatapassword: bigdata@xiaozuanfeng123hikari:connection-test-query: select 1minimum-idle: 5auto-commit: truevalidation-timeout: 3000pool-name: DolphinSchedulermaximum-pool-size: 50connection-timeout: 30000idle-timeout: 600000leak-detection-threshold: 0initialization-fail-timeout: 1
准备zookeeper 并启动
1、下载 zookeeper
D:\software\java>crul https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz --output apache-zookeeper-3.6.3-bin.tar.gzD:\software\java>tar -xvf apache-zookeeper-3.6.3-bin.tar.gzD:\software\java\apache-zookeeper-3.6.3-bin>cd conf D:\software\java\apache-zookeeper-3.6.3-bin\conf>copy zoo_sample.cfg zoo.cfgD:\software\java\apache-zookeeper-3.6.3-bin\bin>./zkServer.cmdregistry.plugin.name=zookeeperregistry.servers=127.0.0.1:2181
-Dspring.profiles.active=mysqldolphinscheduler-server/src/main/java/org/apache/dolphinscheduler/server/master/MasterServer.java
-Dspring.profiles.active=mysqldolphinscheduler-server/src/main/java/org/apache/dolphinscheduler/server/worker/WorkerServer.java
-Dspring.profiles.active=mysqldolphinscheduler-api/src/main/java/org/apache/dolphinscheduler/api/ApiApplicationServer.java
04
调试
创建数据源
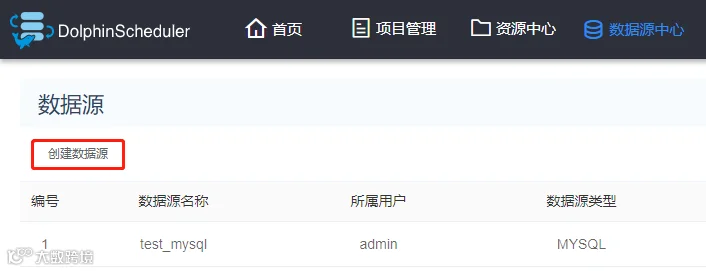
选择 HIVE/IMPALA 数据源
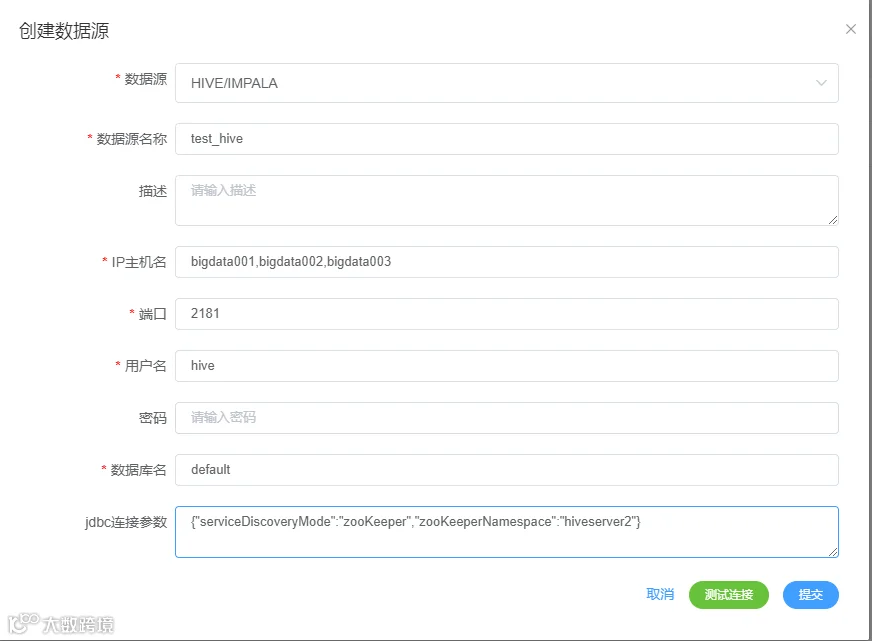
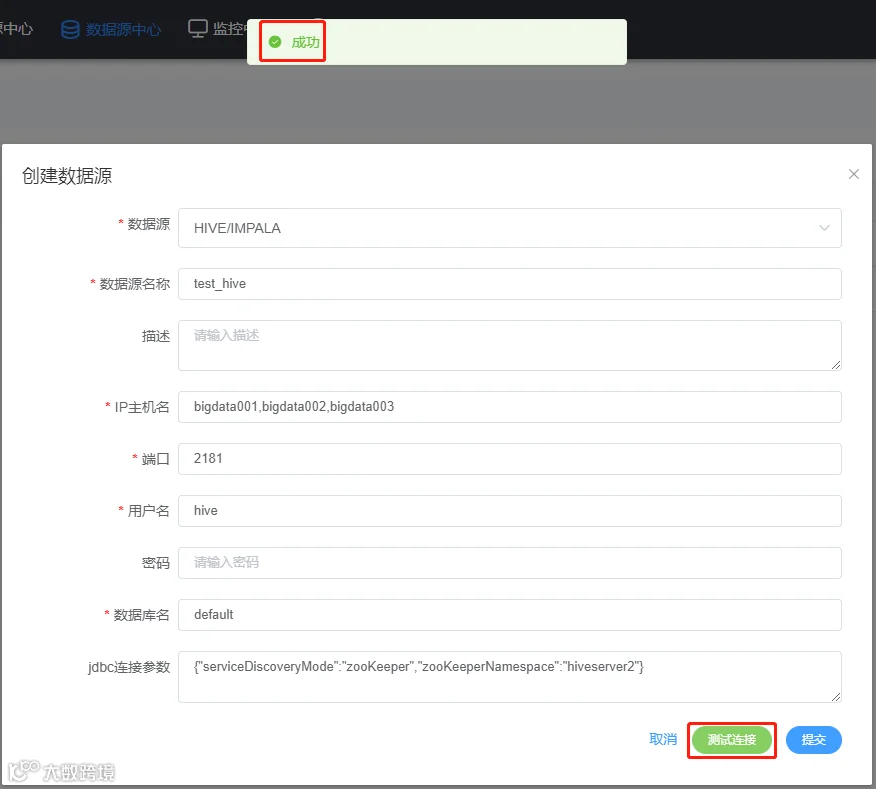
点击测试


05
源码分析
测试连接流程
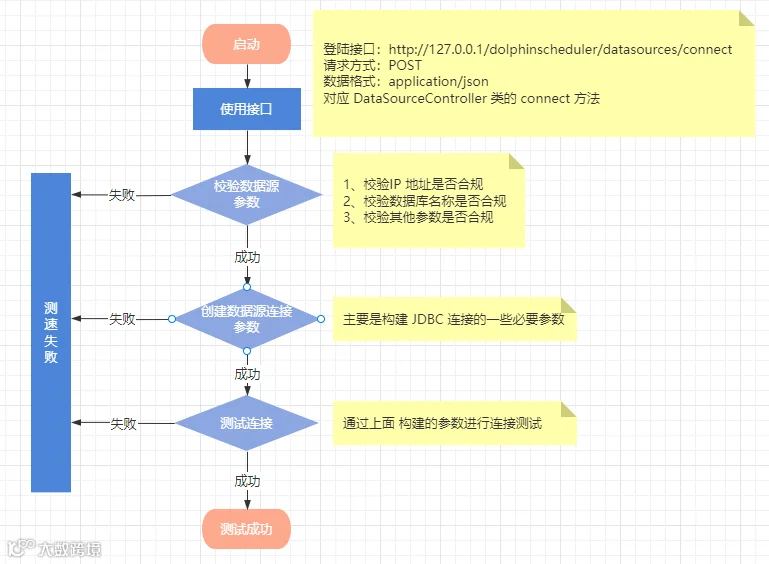
校验数据源参数
private static final Pattern IPV4_PATTERN = Pattern.compile("^[a-zA-Z0-9\\_\\-\\.\\,]+$");private static final Pattern IPV6_PATTERN = Pattern.compile("^[a-zA-Z0-9\\_\\-\\.\\:\\[\\]\\,]+$");protected void checkHost(String host) {if (!IPV4_PATTERN.matcher(host).matches() || !IPV6_PATTERN.matcher(host).matches()) {throw new IllegalArgumentException("datasource host illegal");}}
private static final Pattern DATABASE_PATTER = Pattern.compile("^[a-zA-Z0-9\\_\\-\\.]+$");protected void checkDatasourcePatter(String database) {if (!DATABASE_PATTER.matcher(database).matches()) {throw new IllegalArgumentException("datasource name illegal");}}
private static final Pattern PARAMS_PATTER = Pattern.compile("^[a-zA-Z0-9\\-\\_\\/\\@\\.]+$");protected void checkOther(Map<String, String> other) {if (MapUtils.isEmpty(other)) {return;}boolean paramsCheck = other.entrySet().stream().allMatch(p -> PARAMS_PATTER.matcher(p.getValue()).matches());if (!paramsCheck) {throw new IllegalArgumentException("datasource other params illegal");}}

构建数据源 JDBC 连接参数
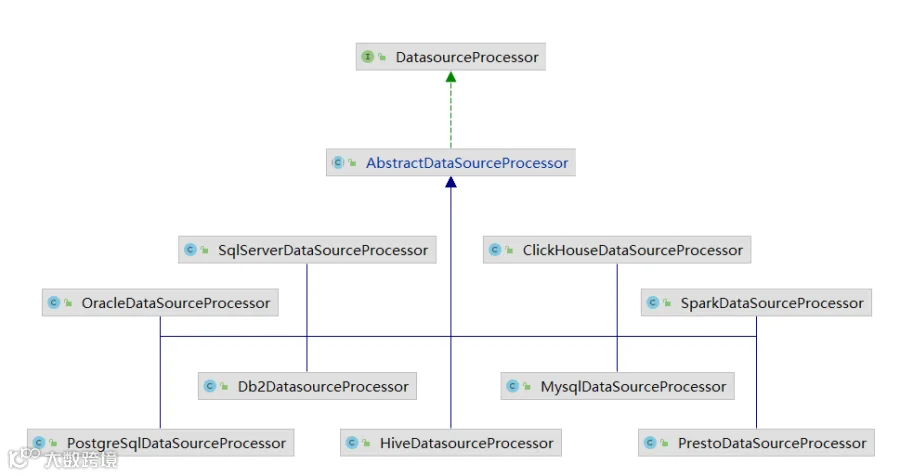
public BaseConnectionParam createConnectionParams(BaseDataSourceParamDTO datasourceParam) {HiveDataSourceParamDTO hiveParam = (HiveDataSourceParamDTO) datasourceParam;// 用来组装 如 jdbc:hive2://ip:port/db 的 jdbc urlStringBuilder address = new StringBuilder();address.append(Constants.JDBC_HIVE_2);for (String zkHost : hiveParam.getHost().split(",")) {address.append(String.format("%s:%s,", zkHost, hiveParam.getPort()));}address.deleteCharAt(address.length() - 1);String jdbcUrl = address.toString() + "/" + hiveParam.getDatabase();// 设置 hive 连接参数,见名知意HiveConnectionParam hiveConnectionParam = new HiveConnectionParam();hiveConnectionParam.setDatabase(hiveParam.getDatabase());hiveConnectionParam.setAddress(address.toString());hiveConnectionParam.setJdbcUrl(jdbcUrl);hiveConnectionParam.setUser(hiveParam.getUserName());hiveConnectionParam.setPassword(PasswordUtils.encodePassword(hiveParam.getPassword()));hiveConnectionParam.setDriverClassName(getDatasourceDriver());hiveConnectionParam.setValidationQuery(getValidationQuery());// 当文件存储系统为 HDFS 并且 开启 kerberos 认证时// 设置 kerberos 相关参数if (CommonUtils.getKerberosStartupState()) {hiveConnectionParam.setPrincipal(hiveParam.getPrincipal());hiveConnectionParam.setJavaSecurityKrb5Conf(hiveParam.getJavaSecurityKrb5Conf());hiveConnectionParam.setLoginUserKeytabPath(hiveParam.getLoginUserKeytabPath());hiveConnectionParam.setLoginUserKeytabUsername(hiveParam.getLoginUserKeytabUsername());}// 稍微重构了一下 transformOther 方法,提取到父类中hiveConnectionParam.setOther(transformOther(getDbType(),hiveParam.getOther()));hiveConnectionParam.setProps(hiveParam.getOther());// 返回return hiveConnectionParam;}
测试连接
public Result<Object> checkConnection(DbType type, ConnectionParam connectionParam) {Result<Object> result = new Result<>();// 测试连接// 获取连接try (Connection connection = DataSourceClientProvider.getInstance().getConnection(type, connectionParam)) {if (connection == null) {putMsg(result, Status.CONNECTION_TEST_FAILURE);return result;}putMsg(result, Status.SUCCESS);return result;} catch (Exception e) {logger.error("datasource test connection error, dbType:{}, connectionParam:{}, message:{}.", type, connectionParam, e.getMessage());return new Result<>(Status.CONNECTION_TEST_FAILURE.getCode(), e.getMessage());}}
dolphinscheduler-datasource-plugin/dolphinscheduler-datasource-api/src/main/java/org/apache/dolphinscheduler/plugin/datasource/api/pluginpublic Connection getConnection(DbType dbType, ConnectionParam connectionParam) {BaseConnectionParam baseConnectionParam = (BaseConnectionParam) connectionParam;String datasourceUniqueId = DataSourceUtil.getDatasourceUniqueId(baseConnectionParam, dbType);logger.info("getConnection datasourceUniqueId {}", datasourceUniqueId);// 有就直接获取// 没有就创建DataSourceClient dataSourceClient = uniqueId2dataSourceClientMap.computeIfAbsent(datasourceUniqueId, $ -> {Map<String, DataSourceChannel> dataSourceChannelMap = dataSourcePluginManager.getDataSourceChannelMap();DataSourceChannel dataSourceChannel = dataSourceChannelMap.get(dbType.getDescp());if (null == dataSourceChannel) {throw new RuntimeException(String.format("datasource plugin '%s' is not found", dbType.getDescp()));}return dataSourceChannel.createDataSourceClient(baseConnectionParam, dbType);});return dataSourceClient.getConnection();}
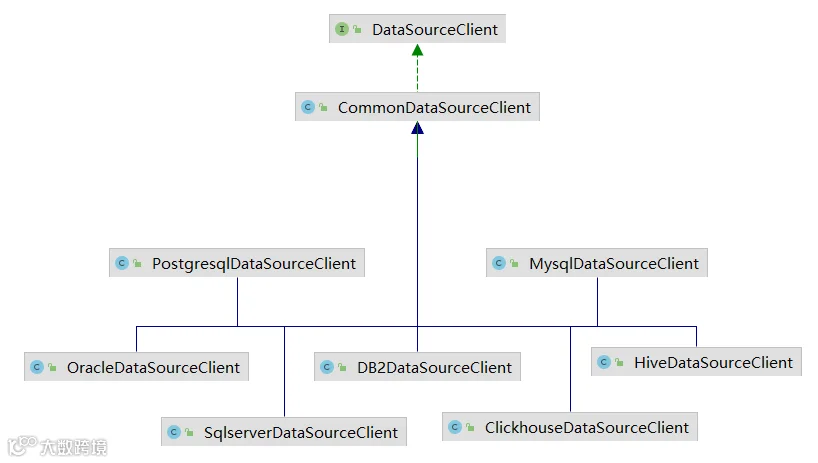
public CommonDataSourceClient(BaseConnectionParam baseConnectionParam, DbType dbType) {this.baseConnectionParam = baseConnectionParam;// 预初始化preInit();// 校验必要参数checkEnv(baseConnectionParam);// 初始化连接initClient(baseConnectionParam, dbType);// 检查连接连通性checkClient();}
protected void preInit() {logger.info("PreInit in {}", getClass().getName());// kerberos 连接池this.kerberosRenewalService = Executors.newSingleThreadScheduledExecutor();}
protected void checkEnv(BaseConnectionParam baseConnectionParam) {// 父类检验必要参数,在此忽略super.checkEnv(baseConnectionParam);// 校验 kerberos 必要参数checkKerberosEnv();}private void checkKerberosEnv() {// kerberos5配置文件所在路径String krb5File = PropertyUtils.getString(JAVA_SECURITY_KRB5_CONF_PATH);if (StringUtils.isNotBlank(krb5File)) {// 设置系统环境System.setProperty(JAVA_SECURITY_KRB5_CONF, krb5File);try {Config.refresh();Class<?> kerberosName = Class.forName("org.apache.hadoop.security.authentication.util.KerberosName");Field field = kerberosName.getDeclaredField("defaultRealm");field.setAccessible(true);field.set(null, Config.getInstance().getDefaultRealm());} catch (Exception e) {throw new RuntimeException("Update Kerberos environment failed.", e);}}}
protected void initClient(BaseConnectionParam baseConnectionParam, DbType dbType) {logger.info("Create Configuration for hive configuration.");// 可人为忽略this.hadoopConf = createHadoopConf();logger.info("Create Configuration success.");logger.info("Create UserGroupInformation.");// 创建 ugithis.ugi = createUserGroupInformation(baseConnectionParam.getUser());logger.info("Create ugi success.");// 父类初始化必要的测试连接super.initClient(baseConnectionParam, dbType);// 获取 hive session 连接this.oneSessionDataSource = JdbcDataSourceProvider.createOneSessionJdbcDataSource(dbType,baseConnectionParam);logger.info("Init {} success.", getClass().getName());}创建 UGIprivate UserGroupInformation createUserGroupInformation(String username) {// kerberos5 配置文件所在路径String krb5File = PropertyUtils.getString(Constants.JAVA_SECURITY_KRB5_CONF_PATH);// 用户的 keytab 认证文件所在路径String keytab = PropertyUtils.getString(Constants.LOGIN_USER_KEY_TAB_PATH);// kerberos 认证的用户 principal 名称String principal = PropertyUtils.getString(Constants.LOGIN_USER_KEY_TAB_USERNAME);try {// 创建 UGIUserGroupInformation ugi = CommonUtil.createUGI(getHadoopConf(), principal, keytab, krb5File, username);try {Field isKeytabField = ugi.getClass().getDeclaredField("isKeytab");isKeytabField.setAccessible(true);isKeytabField.set(ugi, true);} catch (NoSuchFieldException | IllegalAccessException e) {logger.warn(e.getMessage());}kerberosRenewalService.scheduleWithFixedDelay(() -> {try {ugi.checkTGTAndReloginFromKeytab();} catch (IOException e) {logger.error("Check TGT and Renewal from Keytab error", e);}}, 5, 5, TimeUnit.MINUTES);return ugi;} catch (IOException e) {throw new RuntimeException("createUserGroupInformation fail. ", e);}}咱们继续跟进。public static synchronized UserGroupInformation createUGI(Configuration configuration, String principal, String keyTab, String krb5File, String username)throws IOException {// 文件系统 是否为 HDFS 以及 是否开启kerberos 认证if (getKerberosStartupState()) {Objects.requireNonNull(keyTab);if (StringUtils.isNotBlank(krb5File)) {// 设置系统环境System.setProperty(JAVA_SECURITY_KRB5_CONF, krb5File);}// 进行登录return loginKerberos(configuration, principal, keyTab);}return UserGroupInformation.createRemoteUser(username);}public static synchronized UserGroupInformation loginKerberos(final Configuration config, final String principal, final String keyTab)throws IOException {// 配置 hadoop 认证模式为 kerberosconfig.set(Constants.HADOOP_SECURITY_AUTHENTICATION, Constants.KERBEROS);UserGroupInformation.setConfiguration(config);// 使用 principal 和对应的 keytab 登录UserGroupInformation.loginUserFromKeytab(principal.trim(), keyTab.trim());return UserGroupInformation.getCurrentUser();}创建 UGI 后获取 hive session 连接,在 JdbcDataSourceProvider 类中。(划重点,划重点,所有需要通过 JDBC 获取数据库连接的功能,都由该类向外提供)public static HikariDataSource createOneSessionJdbcDataSource(DbType dbType,BaseConnectionParam properties) {logger.info("Creating OneSession HikariDataSource pool for maxActive:{}", PropertyUtils.getInt(Constants.SPRING_DATASOURCE_MAX_ACTIVE, 50));HikariDataSource dataSource = new HikariDataSource();dataSource.setDriverClassName(properties.getDriverClassName());// 由于我的环境中需要 other 中的一些特征参数,所以需要将 other 参数拼接进 jdbc url 中// 而这么做,基本上可以解决许多特殊的或者定制化的连接// 其中该类中 createJdbcDataSource 方法同样可以这么处理dataSource.setJdbcUrl(DataSourceUtil.getJdbcUrl(dbType,properties));dataSource.setUsername(properties.getUser());dataSource.setPassword(PasswordUtils.decodePassword(properties.getPassword()));// 前些天与小伙伴聊到相关,刚好看到相关 pr,便集成进来Boolean isOneSession = PropertyUtils.getBoolean(Constants.SUPPORT_HIVE_ONE_SESSION, false);dataSource.setMinimumIdle(isOneSession ? 1 : PropertyUtils.getInt(Constants.SPRING_DATASOURCE_MIN_IDLE, 5));dataSource.setMaximumPoolSize(isOneSession ? 1 : PropertyUtils.getInt(Constants.SPRING_DATASOURCE_MAX_ACTIVE, 50));dataSource.setConnectionTestQuery(properties.getValidationQuery());if (properties.getProps() != null) {properties.getProps().forEach(dataSource::addDataSourceProperty);}logger.info("Creating OneSession HikariDataSource pool success.");return dataSource;}

在其父类 CommonDataSourceClient 中使用创建的连接。//Checking data source clientStopwatch stopwatch = Stopwatch.createStarted();try {// 执行 select 1 测试是否成功,若本地测试,需要在 dolphinscheduler-datasource-api 下的 pom.xml 文件中添加 hive-jdbc 依赖,直接拷贝现成即可this.jdbcTemplate.execute(this.baseConnectionParam.getValidationQuery());} catch (Exception e) {throw new RuntimeException("JDBC connect failed", e);} finally {logger.info("Time to execute check jdbc client with sql {} for {} ms ", this.baseConnectionParam.getValidationQuery(), stopwatch.elapsed(TimeUnit.MILLISECONDS));}

06
结尾
07
参与贡献

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手
微信(Leonard-ds) 手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
https://dolphinscheduler.apache.org/
您的 Star,是 Apache DolphinScheduler 为爱发电的动力❤️ ~
(Leonard-ds)



☞
WorkflowAsCode 来了,Apache DolphinScheduler 2.0.2 惊喜发布!
☞恭喜 Apache DolphinScheduler 入选可信开源社区共同体预备成员!
☞Apache DolphinScheduler 获评 2021 OSC 最受欢迎项目,白鲸开源获优秀中国开源原生创企奖项!
☞看看又是谁在悄悄做贡献?
☞感谢有你!所有贡献者来领礼物了
☞一文给你整明白多租户在 Apache DolphinScheduler 中的作用
☞开源并不是大牛的专属,普通人也能有属于自己的一亩三分地
☞在 Apache DolphinScheduler 上调试 LDAP 登录,亲测有效!
☞4 亿用户,7W+ 作业调度难题,Bigo 基于 Apache DolphinScheduler 巧化解
点击阅读原文,加入开源!

点个在看你最好看