
点亮 ⭐️ Star · 照亮开源之路
这是一系列关于 DolphinScheduler v2.0.1的源码分析文章,包括对 Master、Worker 基本原理、Master 提交执行、Worker 接受执行、 command 解耦、command 唯一消费实现原理、kill
执行分析等在内的深度解析与思考。
1
Master提交执行
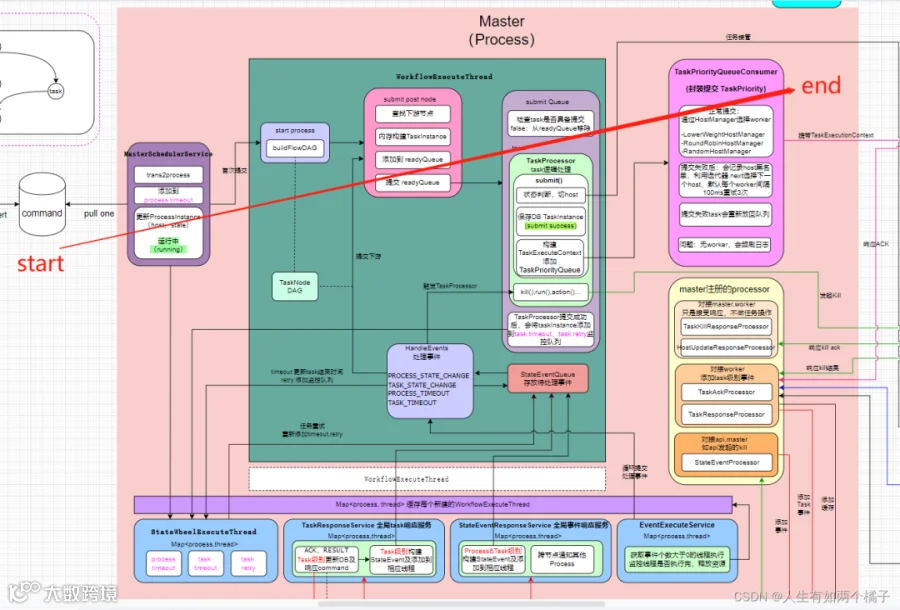
如图中start -> end, master提交执行大致就是从command开始,到提交到consumer结束。
MasterSchedulerService
负责消费command,并将command转化为processInstance,保存或更新DB并删除command,此时 processInstance 状态被更新为 running 状态。
如果 processInstance 级别设置超时,添加到超时队列。
创建 WorkflowExecuteThread 线程并首次提交,以后该线程的触发执行完全由事件驱动,该线程有且仅对应一个 processInstance。
WorkflowExecuteThread
构建 task dag 图,用于触发提交下游;
submitPostNode()方法是核心提交下游的方法,这里需要注意的是在 dag 中,task 是被上游触发提交的,而非自己检测上游判断自己是否达到提交条件,所以当依赖多个上游时,下游就有可能被重复提交;
内存构建 taskInstance ,这里没有落表;
判断是否可提交task,会提交到 readyToSubmitTaskQueue 队列;
触发 readyToSubmitTaskQueue 的执行,真正提交 task,这里会通过判断上游 task 的状态来决定该 task 是否具备提交条件
TaskProcessor
根据 task 的类型不同,抽象出来不同 TaskProcessor 处理器,用来管理 task 整个生命周期的所有操作,包括 submit(),run(),kill() 等,主要有两个操作
将 taskInstance 保存DB,此时页面才看到一个task记录,状态为submit success;
构建 TaskExecutionContext,再封装为 TaskPriority,添加到 taskPriorityQueue 队列;
提交成功,会将 task 添加到 task 超时队列, task 重试队列(见思考2),并且会将 taskId 到TaskProcessor 映射缓存到 activeTaskProcessorMaps ,标识为激活的 task ,这个很重要,后面会参与 process 状态判断,触发 task 的其他操作等;
从 readyToSubmitTaskQueue 移除 task;
TaskPriorityQueueConsumer
本质是个轮询线程,不断扫描处理 taskPriorityQueue 队列的 TaskPriority 。
根据不同策略选择 worker 进行提交。这里需要注意,worker 选择策略只是优先选择出一个worker,不代表只会往这个 worker 上提交,具体提交策略是当一个 worker 提交失败后:会记录 worker 黑名单,从所有相同 group 的其他worker 中,利用迭代器 .next 选择下一个 worker 继续提交,默认每个 worker 间隔100ms重试3次;
收集提交失败的,放回队列;
优化点1:
如果采用的 LowerWeightHostManager ,最好是同 group 的 worker 按负载排序,优先选低负载的 worker 。
优化点2:已修复
当 worker 没有资源时,频繁刷日志,这里高版本已经优化了,原理是提交失败后 sleep 。
日志:fail to execute : %s due to no suitable worker, current task needs worker group %s to execute
2
master 注册的 processor
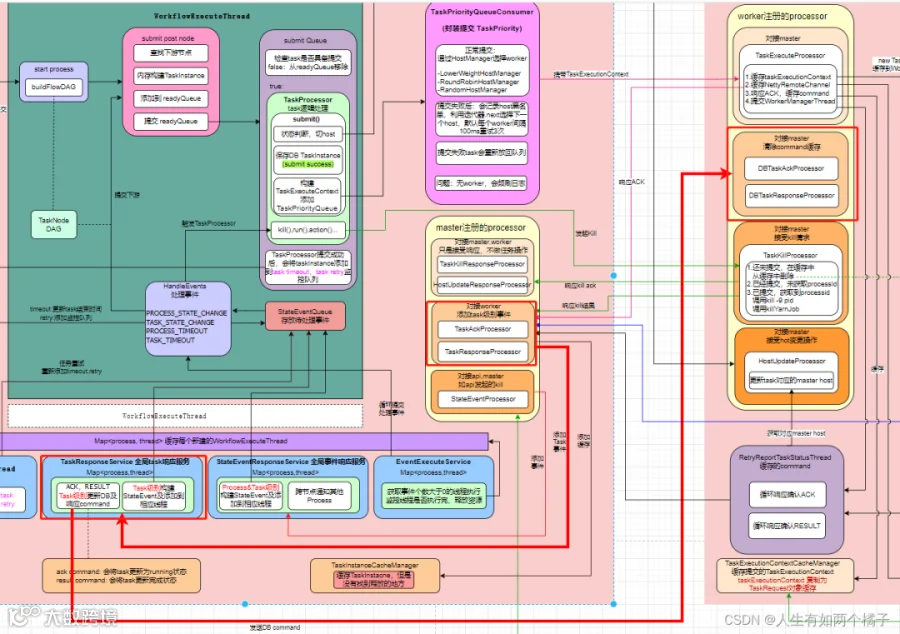
这里重点说 TaskAckProcessor 和 TaskResponseProcessor ,当 task 提交到 worker 后, task 在 worker 的执行情况主要靠这两个processor 来接受了。并且会触发操作DB,更新task。最终会响应 worker DBcommand (如图中两条粗红线所示)
TaskAckProcessor
当worker接收到到task后,会给master响应ack,TaskAckProcessor接受到会封装ack event添加到TaskResponseService 。
TaskResponseProcessor
当worker执行完task后,会给master响应result,TaskResponseProcessor 接受到会封装 result event添加到 TaskResponseService 。
TaskResponseService
如果是 ack 会更新 task 的 worker host,state为 running 状态,log 路径等,并响应给 worker 的 DBTaskAckProcessor ;
如果是 result 会更新 task 的 state(success或failed),endtime等,并响应给worker的DBTaskResponseProcessor ;
封装 TASK_STATE_CHANGE 的 event,添加到 process 线程,等待事件驱动执行;
思考1
任务如何按照优先级执行?
查看 TaskPriority 实现的 compareTo() 方法,大致是按照优先 process 级别,在 task 级别的优先级执行。
并且 taskPriorityQueue 队列是整个 master 服务级别的,添加进去的task是不区分租户和任务类型的,所以,有需求的同学需要二开 TaskPriorityQueueConsumer 的接受队列。
public int compareTo(TaskPriority other) {if (this.getProcessInstancePriority() > other.getProcessInstancePriority()) {return 1;}if (this.getProcessInstancePriority() < other.getProcessInstancePriority()) {return -1;}if (this.getProcessInstanceId() > other.getProcessInstanceId()) {return 1;}if (this.getProcessInstanceId() < other.getProcessInstanceId()) {return -1;}if (this.getTaskInstancePriority() > other.getTaskInstancePriority()) {return 1;}if (this.getTaskInstancePriority() < other.getTaskInstancePriority()) {return -1;}if (this.getTaskId() > other.getTaskId()) {return 1;}if (this.getTaskId() < other.getTaskId()) {return -1;}return this.getGroupName().compareTo(other.getGroupName());}
思考2
task 的 retry 是如何实现的?
首先理解下 StateWheelExecuteThread:
一个轮询线程,不断的扫描重试队列,判断task是否满足重试(task重试条件是失败,到达重试时间且有重试次数),当达到重试条件,会用 task 生成一个 TASK_STATE_CHANGE 的 event ,并添加到对应 process 的 WorkflowExecuteThread 线程,之后就等待事件驱动执行。
在 TaskProcessor 中,任务A1首次保存 DB 并提交到 taskPriorityQueue 队列后,就把 A1添加到重试队列。
当A1触发重试,会把 A1提交到 readyToSubmitTaskQueue ,一直到保存DB时,才会判断 task 进行重置属性处理生成新的task A2,提交成功后,又将A2添加到重试队列,往复如此。
核心逻辑如下代码
task 是失败状态;
将A1设置 flag = no;
生成新的 task A2,processInstance 状态不是RESDY_STOP和READY_PAUSE是前提;
由于重试间隔,在特定情况下,kill 时有一个 bug,会在 kill 逻辑中讲。
public TaskInstance submitTaskInstanceToDB(TaskInstance taskInstance, ProcessInstance processInstance) {ExecutionStatus processInstanceState = processInstance.getState();// 1. 判断task为失败if (taskInstance.getState().typeIsFailure()) {if (taskInstance.isSubProcess()) {taskInstance.setRetryTimes(taskInstance.getRetryTimes() + 1);} else {if (processInstanceState != ExecutionStatus.READY_STOP&& processInstanceState != ExecutionStatus.READY_PAUSE) {// 2. 将重试task置为不可用 notaskInstance.setFlag(Flag.NO);updateTaskInstance(taskInstance);// crate new task instanceif (taskInstance.getState() != ExecutionStatus.NEED_FAULT_TOLERANCE) {taskInstance.setRetryTimes(taskInstance.getRetryTimes() + 1);}// 3. 重置属性,生成新的task// 重置task一些属性,其余属性不变taskInstance.setSubmitTime(null);taskInstance.setLogPath(null);taskInstance.setExecutePath(null);taskInstance.setStartTime(null);taskInstance.setEndTime(null);taskInstance.setFlag(Flag.YES);taskInstance.setHost(null);// 设置id为0,保证新生成一条记录taskInstance.setId(0);}}}......}
3
可能的 PR 福利
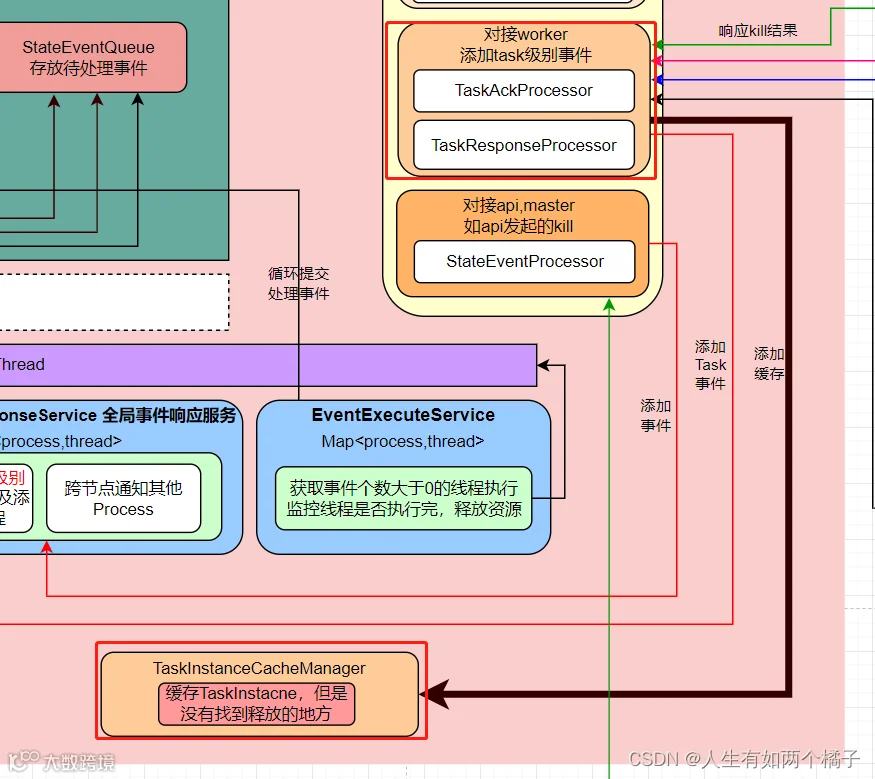
// master提交出去,收到响应,进行缓存taskInstanceCacheManager.cacheTaskInstance(taskAckCommand);
TaskAckProcessor 和 TaskResponseProcessor 都会在 TaskInstanceCacheManager 缓存taskInstance,但是没有找到释放的地方。
4
Worker 接受执行
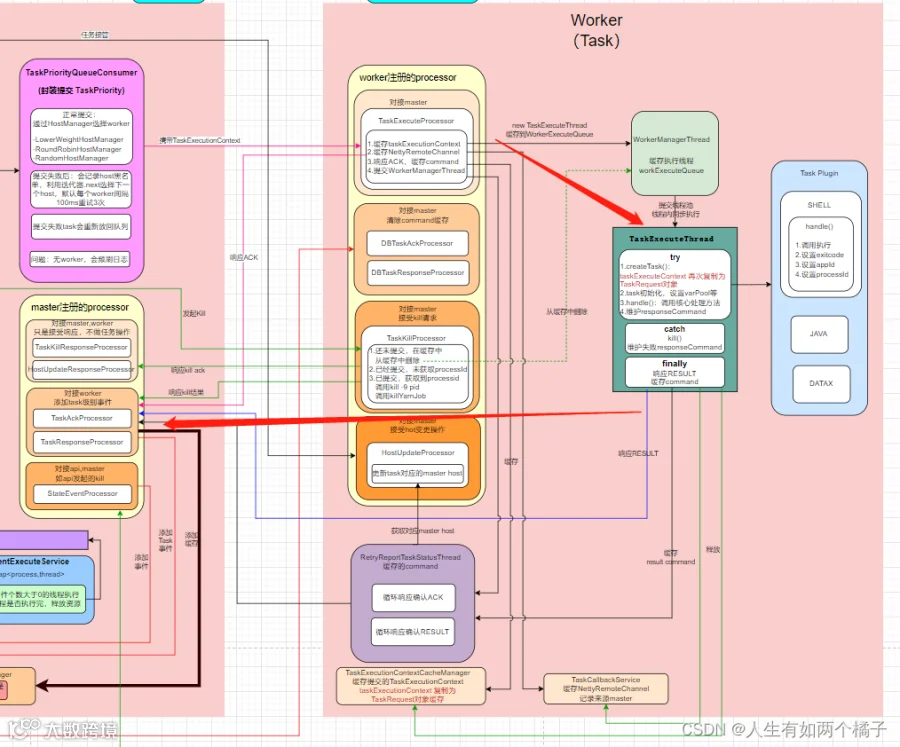
如红箭头所示,worker 大致从接受到 task,提交线程执行,最后响应结果结束。
TaskExecuteProcessor
worker 入口,接受 master 提交的 TaskExecutionContext 。
缓存 TaskExecutionContext 。特别注意,这里 TaskExecutionContext 第一次复制为 TaskRequest 对象(简称TR1),缓存到 TaskExecutionContextCacheManager ;
缓存 NettyRemoteChannel 到TaskCallbackService 中,后面于 master 通信都要用到;
响应 ACK command , command 里记录了task 得 worker host , state , log path , start time 。并且 worker 服务会缓存 ack command 到 RetryReportTaskStatusThread 。RetryReportTaskStatusThread 是个轮询线程,不断的重新发送 command ;
创建 TaskExecuteThread 线程(传入TaskExecutionContext对象),并添加到 WorkerManagerThread 里的队列中,等待真正提交执行;
WorkerManagerThread
主要有两个组成:
workerExecuteQueue 队列,用于接受缓存 TaskExecuteProcessor 提交的线程;
ExecutorService 线程池,用于提交 workerExecuteQueue 队列里的线程,该线程池可执行线程数可配置,也是设置 worker 的并发度;
工作原理:本质是个轮询线程,不断从workerExecuteQueue 队列获取 TaskExecuteThread 线程, 利用 ExecutorService 进行提交执行。
TaskExecuteThread
真正的执行线程。
传入 TaskExecutionContext 对象第二次复制为 TaskRequest 对象(简称TR2)
根据 task 类型,利用 TaskChannel 实例化一个真正的 task (传入TR2对象),比如 shell , java 等(继承 AbstractTask ),方法有 init(), handle(), cancelApplication() 等;
2) handle()是核心执行方法,执行中会生成processId (任务进程ID) , yarn applicationId ,执行状态结果等;
响应 responseCommand(result command) ,并缓存 result command 到 RetryReportTaskStatusThread ;
释放 task 缓存;
RetryReportTaskStatusThread
缓存 ack result command ,如果正常响应 command 失败,该轮询线程会持续发送,一直到收到 master 响应的 DBcommand 。
5
Worker注册的Processor
TaskExecuteProcessor: 不再赘述
DBTaskAckProcessor 和 DBTaskResponseProcessor
接受 master 发出的 DBcommand ;
清除 RetryReportTaskStatusThread 里缓存的ack result command ;
思考1
TaskExecutionContext 和 TaskRequest?
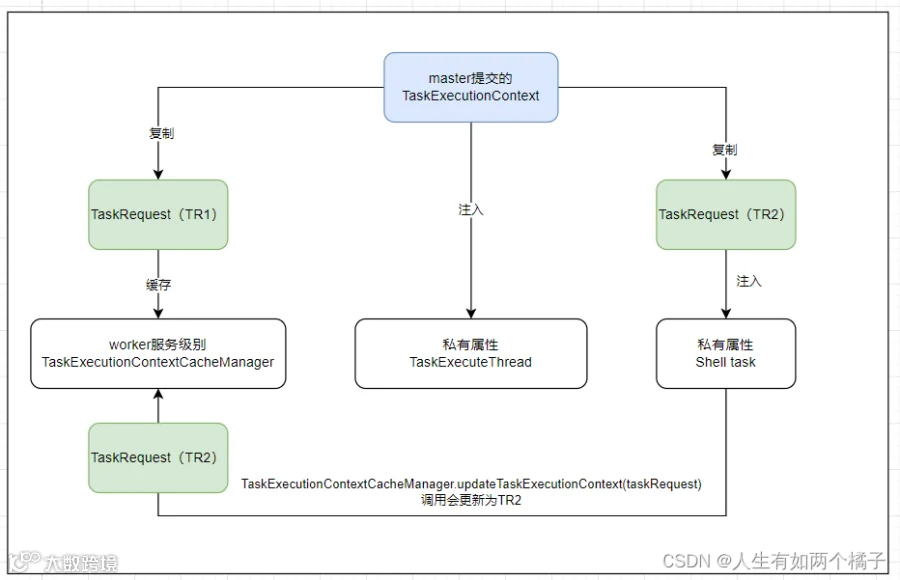
以 kill 为例,目前海豚 kill是从 TaskExecutionContextCacheManager 里获取TaskRequest(TR1),进而获取 processId 等信息进行 kill 操作。
从上图看,task 需要将这些重要信息同步到TR1,源码实现。
taskRequest.setProcessId(processId);boolean updateTaskExecutionContextStatus =TaskExecutionContextCacheManager.updateTaskExecutionContext(taskRequest);
在 task 内,使用TR2设置 processId ,然后更新 TaskExecutionContextCacheManager 为TR2。
下篇预告:Apache DolphinScheduler v2.0.1 Master 和 Worker 执行流程分析系列(三)
原文链接:https://blog.csdn.net/qq_37706484/article/details/126888912
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
☞DolphinScheduler 能用 Python 脚本编排工作流了!PyDolphinScheduler 简介与使用演示
☞Apache DolphinScheduler 2.0.7 发布,修复补数及容错故障问题
☞挑战海量数据:基于Apache DolphinScheduler对千亿级数据应用实践
☞金融科技数据中台基于 DolphinScheduler 的应用改造
