
点击上方  蓝字关注我们
蓝字关注我们

我们为什么使用海豚调度,
带来了什么价值,遇到了什么问题
-
多源数据连接和接入,技术领域绝大多数常见的数据源都可以接入,加入新的数据源也无需太多的改动; -
多元化+专业化+海量数据任务管理,真正地围绕大数据(hadoop family,flink 等)的任务调度,与传统调度器有显著的不同; -
图形化任务编排,超级的用户体验,可以和商用产品直接对标,并且多数国外的开源产品并不能直接拖拉拽生成数据任务; -
任务明细,原子任务丰富的查看、日志查看,时间运行轴显示,满足开发人员对数据任务的精细化管理,快速定位慢sql,性能瓶颈; -
多种分布式文件系统的支持,丰富用户对非结构化数据的选择; -
天然的多租户管理,满足大型组织下数据任务管理和隔离要求; -
全自动的分布式调度算法,均衡所有调度任务; -
自带集群监控功能,监控 cpu,内存,连接数,zookeeper 状态,适合中小企业一站式运维; -
自带任务告警功能,最大程度减少了任务运行风险; -
强大的社区化运营,倾听客户真正的声音,不断新增功能,持续优化客户体验;
-
如何用更少的人力资源去部署海豚调度,是否可以实现全自动的集群化安装部署模式? -
如何标准化技术组件实施规范? -
是否可以进行无人监管,系统自愈? -
网络安全管控要求下,如何实现air-gap模式的安装和更新? -
能否无感的自动扩容? -
监控体系如何搭建和融合?
Kubernetes 技术体系
给海豚调度带来的技术新特性
-
各类独立部署项目,快速建立开发环境和生产环境,全部实现了一键部署,一键升级的实施模式; -
全面支持无互联网的离线安装,切安装速度更快; -
尽可能统一的安装配置的信息,减少多个项目配置的异常,所有的配置项,可以基于不同的项目通过企业内部git管理; -
与对象存储技术的结合,统一非结构化数据的技术; -
便捷的监控体系,与现有 prometheus 监控体系集成; -
多种调度器的混合使用; -
全自动的资源调整能力; -
快速的自愈能力,自动异常重启,以及基于探针模式的重启;
基于 Helm 工具的自动化高效部署方式

image:
repository: "apache/dolphinscheduler"
tag: "1.3.9"
pullPolicy: "IfNotPresent"
docker pull apache/dolphinscheduler:1.3.9
dock tag apache/dolphinscheduler:1.3.9 harbor.abc.com/apache/dolphinscheduler:1.3.9
docker push apache/dolphinscheduler:1.3.9
image:
repository: "harbor.abc.com/apache/dolphinscheduler"
tag: "1.3.9"
pullPolicy: "Always"把 https://github.com/apache/dolphinscheduler/tree/1.3.9-release/docker/kubernetes/dolphinscheduler 整个目录 copy 到可以执行 helm 命令的主机,然后按照官网执行 kubectl create ns ds139
helm install dolphinscheduler . -n ds139
-
集成 datax、mysql、oracle 客户端组件,首先下载以下组件 https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.49/mysql-connector-java-5.1.49.jar https://repo1.maven.org/maven2/com/oracle/database/jdbc/ojdbc8/ https://github.com/alibaba/DataX/blob/master/userGuid.md 根据提示进行编译构建,文件包位于 {DataX_source_code_home}/target/datax/datax/ 基于以上 plugin 组件新建 dockerfile,基础镜像可以使用已经 push 到私仓的镜像。 FROM harbor.abc.com/apache/dolphinscheduler:1.3.9
COPY *.jar /opt/dolphinscheduler/lib/
RUN mkdir -p /opt/soft/datax
COPY datax /opt/soft/datax保存 dockerfile,执行 shell 命令 docker build -t harbor.abc.com/apache/dolphinscheduler:1.3.9-mysql-oracle-datax . #不要忘记最后一个点
docker push harbor.abc.com/apache/dolphinscheduler:1.3.9-mysql-oracle-datax修改 value 文件 image:
repository: "harbor.abc.com/apache/dolphinscheduler"
tag: "1.3.9-mysql-oracle-datax"
pullPolicy: "Always"执行 helm install dolphinscheduler . -n ds139,或者执行 helm upgrade dolphinscheduler -n ds139,也可以先 helm uninstall dolphinscheduler -n ds139,再执行 helm install dolphinscheduler . -n ds139。 -
通常生产环境建议使用独立外置 postgresql 作为管理数据库,并且使用独立安装的 zookeeper 环境(本案例使用了zookeeper operator https://github.com/pravega/zookeeper-operator,与海豚调度在同一个 kubernetes 集群中)。我们发现,使用外置数据库后,对海豚调度在 kubernetes 中进行完全删除操作,然后重新部署海豚调度后,任务数据、租户数据、用户数据等等都有保留,这再次验证了系统的高可用性和数据完整性。(如果删除了 pvc ,会丢失历史的作业日志) ## If not exists external database, by default, Dolphinscheduler's database will use it.
postgresql:
enabled: false
postgresqlUsername: "root"
postgresqlPassword: "root"
postgresqlDatabase: "dolphinscheduler"
persistence:
enabled: false
size: "20Gi"
storageClass: "-"
## If exists external database, and set postgresql.enable value to false.
## external database will be used, otherwise Dolphinscheduler's database will be used.
externalDatabase:
type: "postgresql"
driver: "org.postgresql.Driver"
host: "192.168.1.100"
port: "5432"
username: "admin"
password: "password"
database: "dolphinscheduler"
params: "characterEncoding=utf8"
## If not exists external zookeeper, by default, Dolphinscheduler's zookeeper will use it.
zookeeper:
enabled: false
fourlwCommandsWhitelist: "srvr,ruok,wchs,cons"
persistence:
enabled: false
size: "20Gi"
storageClass: "storage-nfs"
zookeeperRoot: "/dolphinscheduler"
## If exists external zookeeper, and set zookeeper.enable value to false.
## If zookeeper.enable is false, Dolphinscheduler's zookeeper will use it.
externalZookeeper:
zookeeperQuorum: "zookeeper-0.zookeeper-headless.zookeeper.svc.cluster.local:2181,zookeeper-1.zookeeper-headless.zookeeper.svc.cluster.local:2181,zookeeper-2.zookeeper-headless.zookeeper.svc.cluster.local:2181"
zookeeperRoot: "/dolphinscheduler"
基于 argo-cd 的 gitops 部署方式

-
图形化安装集群化的软件,一键安装; -
git 记录全发版流程,一键回滚; -
便捷的海豚工具日志查看;
-
从github 上下载海豚调度源码,修改 value 文件,参考上个章节 helm 安装需要修改的内容; -
把修改后的源码目录新建git项目,并且 push 到公司内部的 gitlab 中,github源码的目录名为docker/kubernetes/dolphinscheduler; -
在 argo-cd 中配置 gitlab 信息,我们使用 https 的模式;
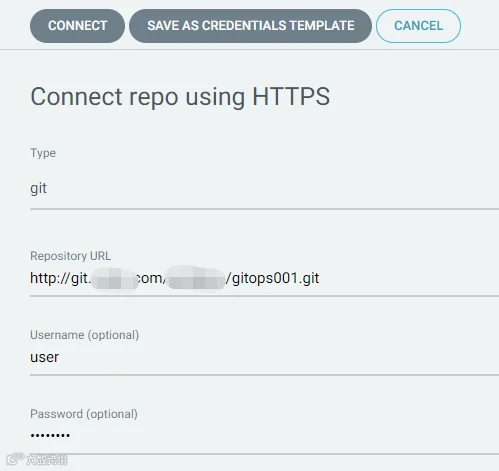
-
argo-cd 新建部署工程,填写相关信息
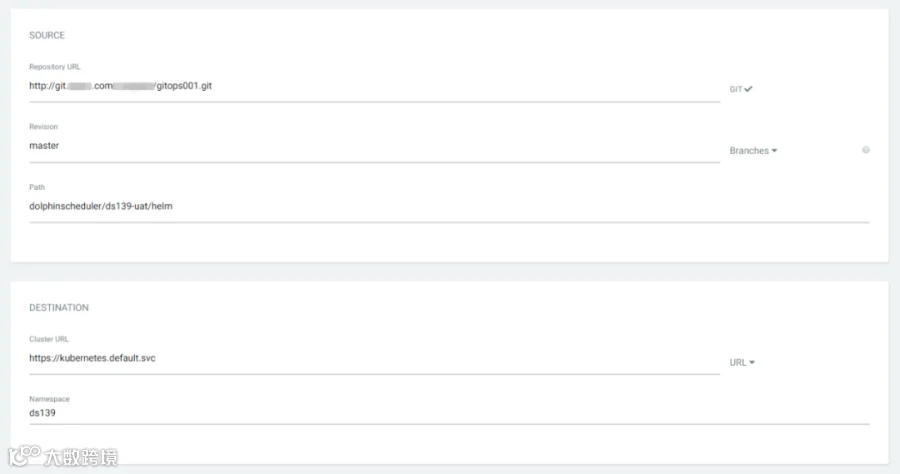
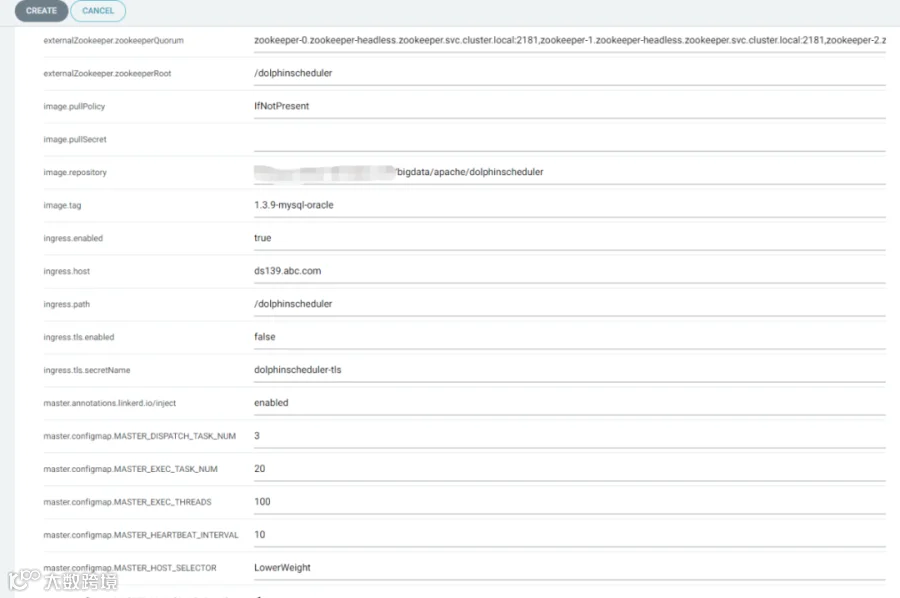
对git中的部署信息进行刷新和拉取,实现最后的部署工作。可以看到 pod,configmap,secret,service,ingress 等等资源全自动拉起,并且 argo-cd 显示了之前 git push 使用的 commit 信息和提交人用户名,这样就完整记录了所有的发版事件信息。同时也可以一键回滚到历史版本。
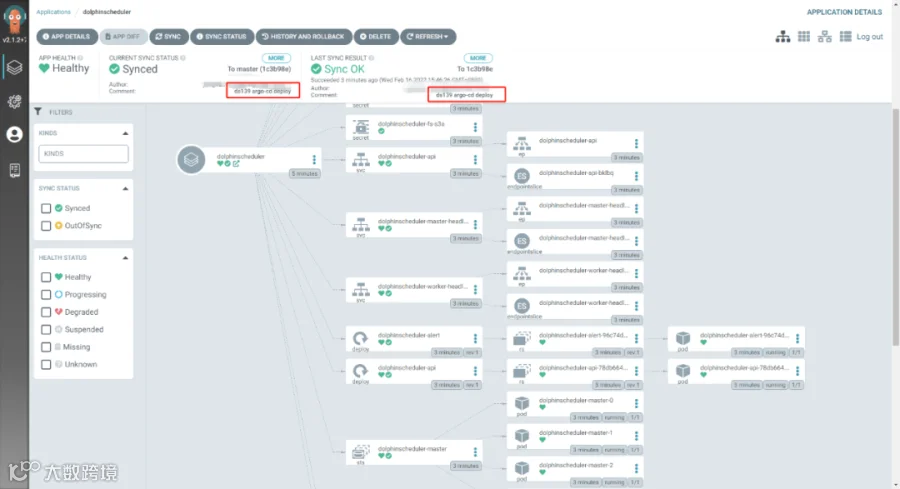
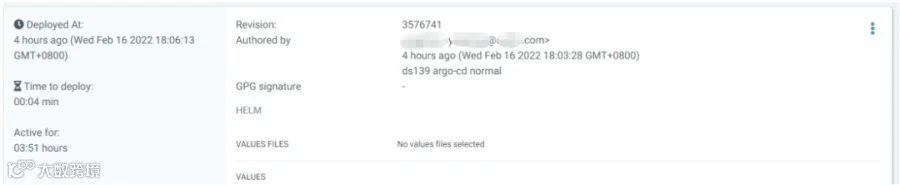
-
通过 kubectl 命令可以看到相关资源信息; [root@tpk8s-master01 ~]# kubectl get po -n ds139
NAME READY STATUS RESTARTS AGE
dolphinscheduler-alert-96c74dc84-72cc9 1/1 Running 0 22m
dolphinscheduler-api-78db664b7b-gsltq 1/1 Running 0 22m
dolphinscheduler-master-0 1/1 Running 0 22m
dolphinscheduler-master-1 1/1 Running 0 22m
dolphinscheduler-master-2 1/1 Running 0 22m
dolphinscheduler-worker-0 1/1 Running 0 22m
dolphinscheduler-worker-1 1/1 Running 0 22m
dolphinscheduler-worker-2 1/1 Running 0 22m
[root@tpk8s-master01 ~]# kubectl get statefulset -n ds139
NAME READY AGE
dolphinscheduler-master 3/3 22m
dolphinscheduler-worker 3/3 22m
[root@tpk8s-master01 ~]# kubectl get cm -n ds139
NAME DATA AGE
dolphinscheduler-alert 15 23m
dolphinscheduler-api 1 23m
dolphinscheduler-common 29 23m
dolphinscheduler-master 10 23m
dolphinscheduler-worker 7 23m
[root@tpk8s-master01 ~]# kubectl get service -n ds139
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dolphinscheduler-api ClusterIP 10.43.238.5 <none> 12345/TCP 23m
dolphinscheduler-master-headless ClusterIP None <none> 5678/TCP 23m
dolphinscheduler-worker-headless ClusterIP None <none> 1234/TCP,50051/TCP 23m
[root@tpk8s-master01 ~]# kubectl get ingress -n ds139
NAME CLASS HOSTS ADDRESS
dolphinscheduler <none> ds139.abc.com
-
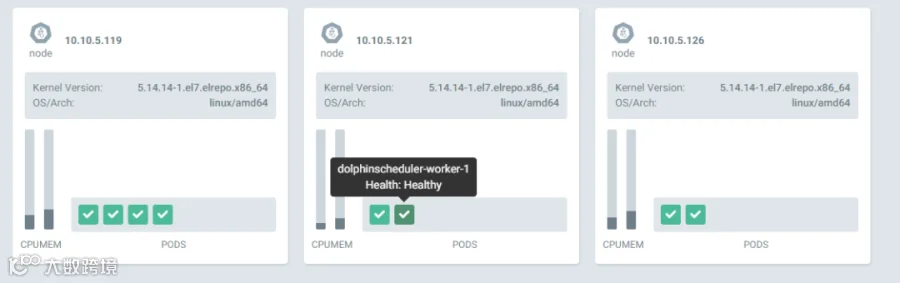
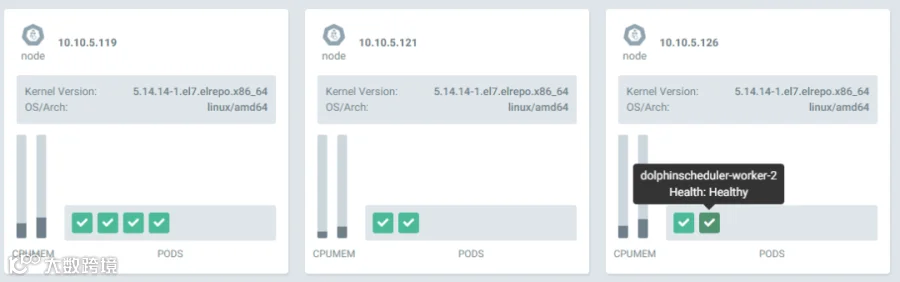
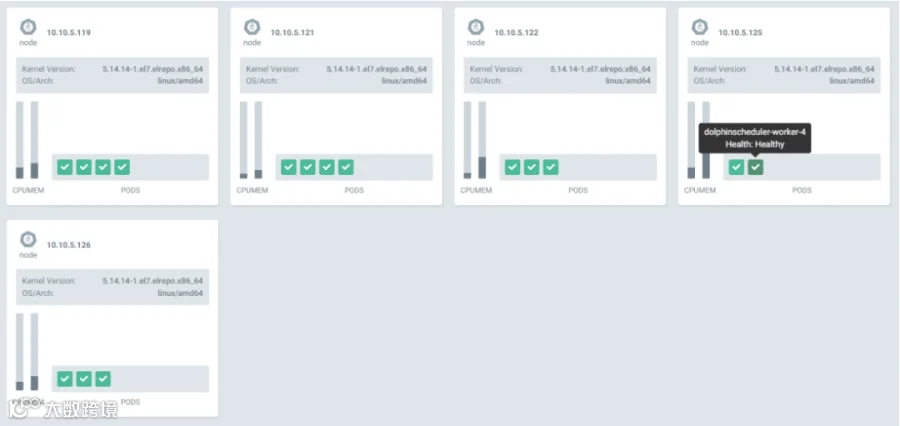
可以看到所有的 pod 都分散在 kubernetes 集群中不同的 host 上,例如worker 1 和 2 都在不同的节点上。
我们配置了 ingress,公司内部配置了泛域名就可以方便的使用域名进行访问; 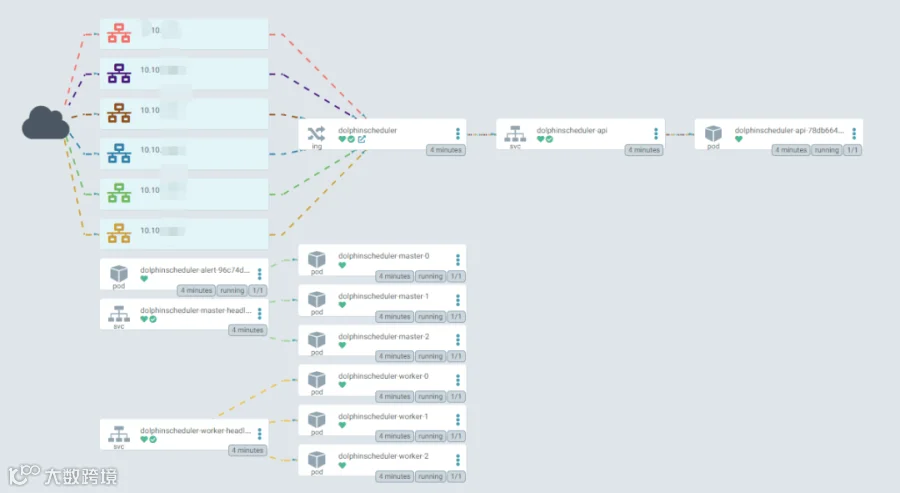
可以登录域名进行访问。 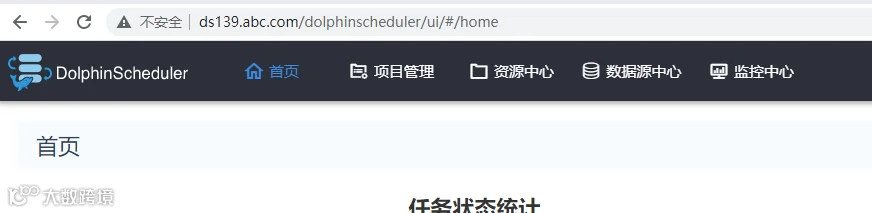
-
具体配置可以修改 value 文件中的内容: ingress:
enabled: true
host: "ds139.abc.com"
path: "/dolphinscheduler"
tls:
enabled: false
secretName: "dolphinscheduler-tls"
-
方便查看海豚调度各个组件的内部日志:
-
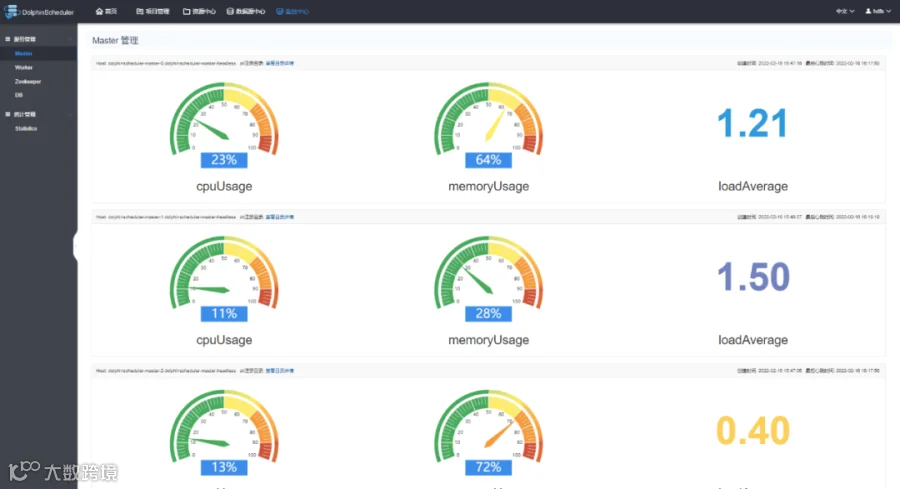
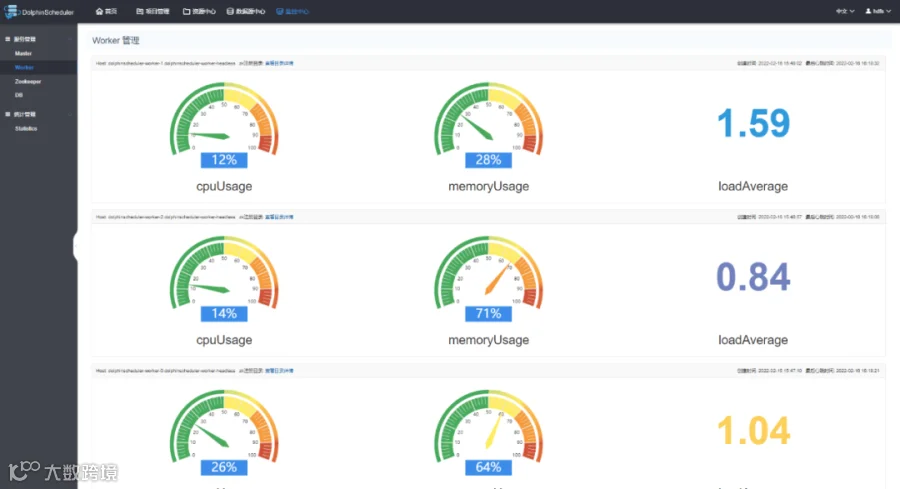
对部署好的系统进行检查,3个 master,3个 worker,zookeeper 都配置正常;

-
使用 argo-cd 可以非常方便的进行修改 master,worker,api,alert 等组件的副本数量,海豚的 helm 配置也预留了 cpu 和内存的设置信息。这里我们修改 value 中的副本值。修改后,git pish 到公司内部 gitlab。 master:
## PodManagementPolicy controls how pods are created during initial scale up, when replacing pods on nodes, or when scaling down.
podManagementPolicy: "Parallel"
## Replicas is the desired number of replicas of the given Template.
replicas: "5"
worker:
## PodManagementPolicy controls how pods are created during initial scale up, when replacing pods on nodes, or when scaling down.
podManagementPolicy: "Parallel"
## Replicas is the desired number of replicas of the given Template.
replicas: "5"
alert:
## Number of desired pods. This is a pointer to distinguish between explicit zero and not specified. Defaults to 1.
replicas: "3"
api:
## Number of desired pods. This is a pointer to distinguish between explicit zero and not specified. Defaults to 1.
replicas: "3"
只需要在 argo-cd 点击 sync 同步,对应的 pods 都按照需求进行了增加
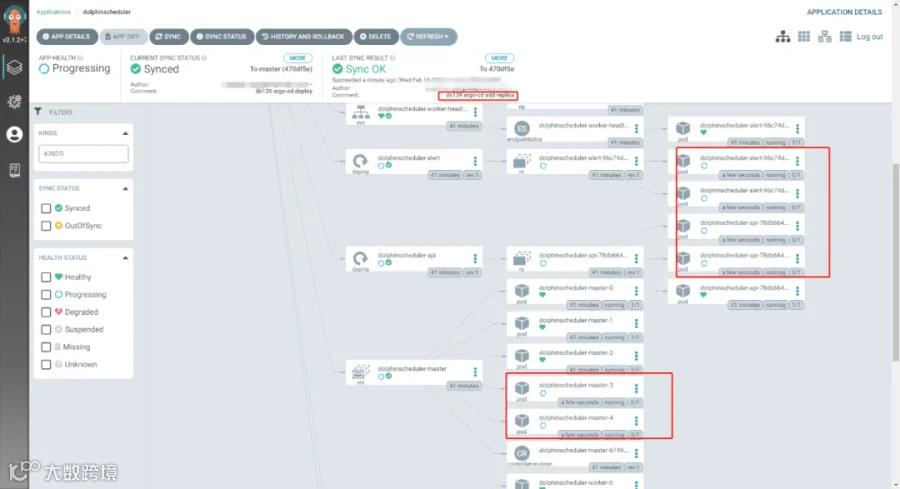
[root@tpk8s-master01 ~]# kubectl get po -n ds139
NAME READY STATUS RESTARTS AGE
dolphinscheduler-alert-96c74dc84-72cc9 1/1 Running 0 43m
dolphinscheduler-alert-96c74dc84-j6zdh 1/1 Running 0 2m27s
dolphinscheduler-alert-96c74dc84-rn9wb 1/1 Running 0 2m27s
dolphinscheduler-api-78db664b7b-6j8rj 1/1 Running 0 2m27s
dolphinscheduler-api-78db664b7b-bsdgv 1/1 Running 0 2m27s
dolphinscheduler-api-78db664b7b-gsltq 1/1 Running 0 43m
dolphinscheduler-master-0 1/1 Running 0 43m
dolphinscheduler-master-1 1/1 Running 0 43m
dolphinscheduler-master-2 1/1 Running 0 43m
dolphinscheduler-master-3 1/1 Running 0 2m27s
dolphinscheduler-master-4 1/1 Running 0 2m27s
dolphinscheduler-worker-0 1/1 Running 0 43m
dolphinscheduler-worker-1 1/1 Running 0 43m
dolphinscheduler-worker-2 1/1 Running 0 43m
dolphinscheduler-worker-3 1/1 Running 0 2m27s
dolphinscheduler-worker-4 1/1 Running 0 2m27s
海豚调度与 S3 对象存储技术集成
许多同学在海豚的社区中提问,如何配置 s3 minio 的集成。这里给出基于kubernetes 的 helm 配置。
-
修改 value 中 s3 的部分,建议使用 ip+端口指向 minio 服务器。 common:
## Configmap
configmap:
DOLPHINSCHEDULER_OPTS: ""
DATA_BASEDIR_PATH: "/tmp/dolphinscheduler"
RESOURCE_STORAGE_TYPE: "S3"
RESOURCE_UPLOAD_PATH: "/dolphinscheduler"
FS_DEFAULT_FS: "s3a://dfs"
FS_S3A_ENDPOINT: "http://192.168.1.100:9000"
FS_S3A_ACCESS_KEY: "admin"
FS_S3A_SECRET_KEY: "password" -
minio 中存放海豚文件的 bucket 名字是 dolphinscheduler,这里新建文件夹和文件进行测试。minio 的目录在上传操作的租户下。


海豚调度与 Kube-prometheus 的技术集成
-
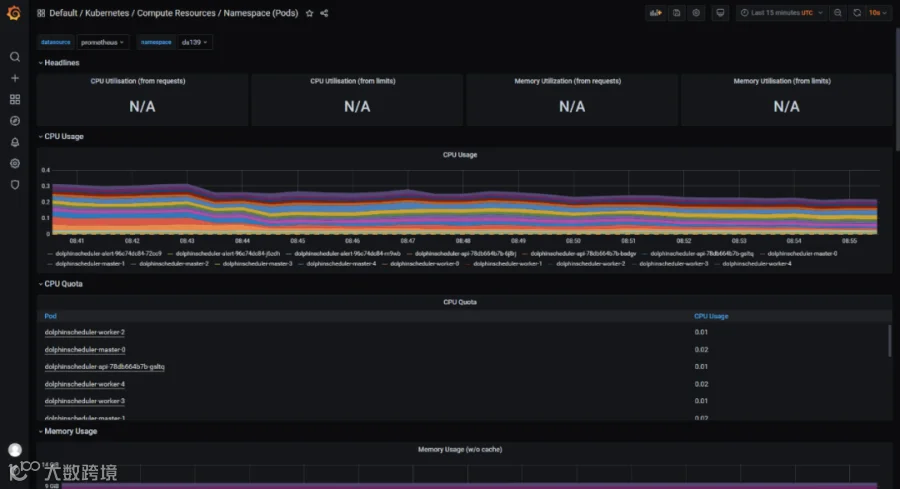
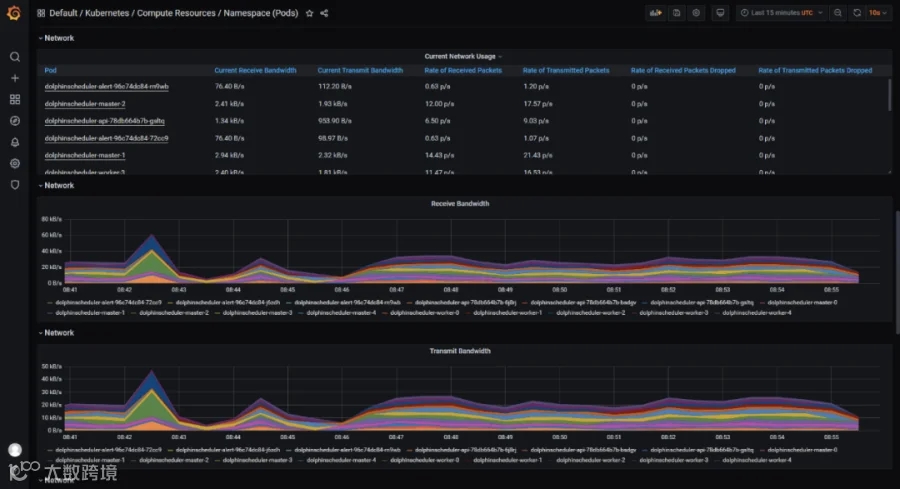
我们在 kubernetes 使用 kube-prometheus operator技术,在部署海豚后,自动实现了对海豚各个组件的资源监控。 -
请注意 kube-prometheus 的版本,需要对应 kubernetes 主版本。https://github.com/prometheus-operator/kube-prometheus
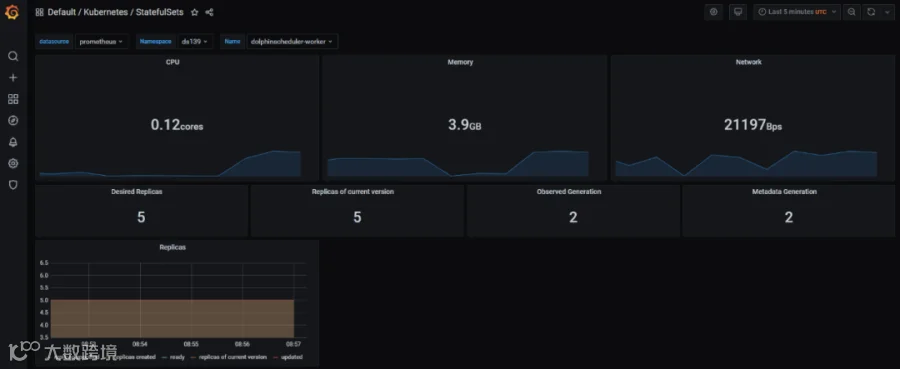
海豚调度与 Service Mesh 的技术集成
-
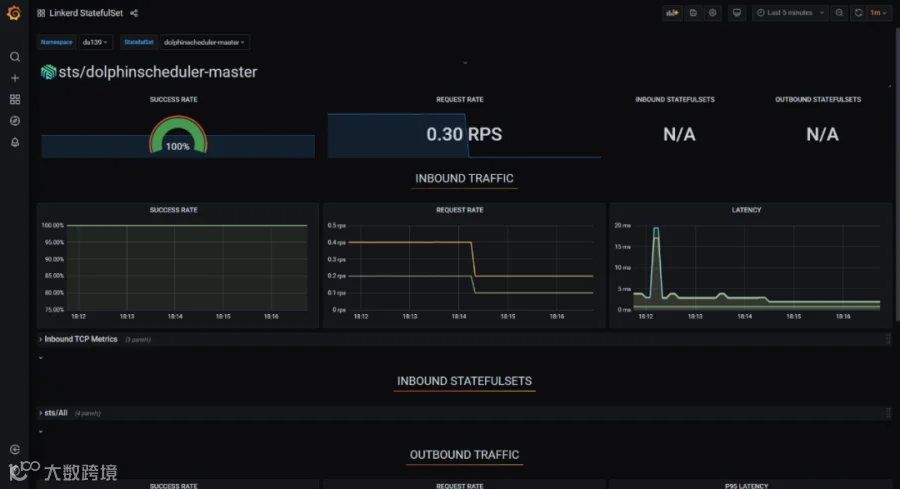
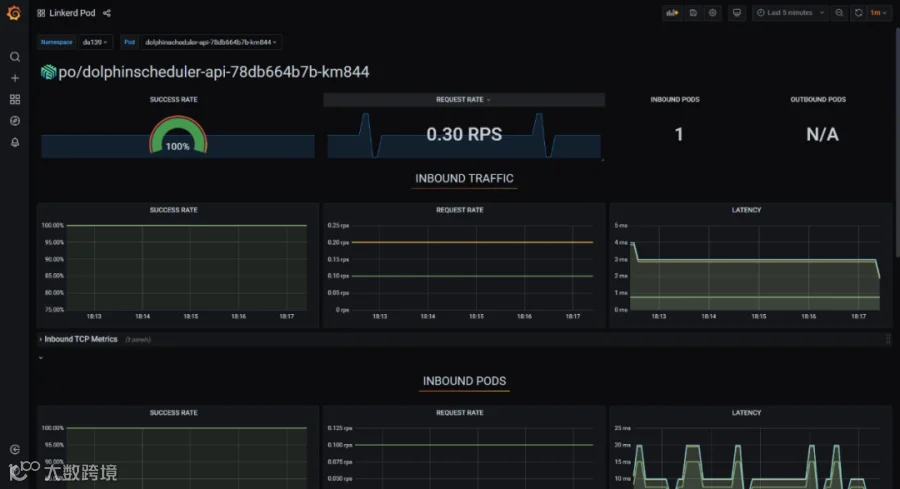
通过 service mesh 技术可以实现对海豚内部的服务调用,以及海豚 api 外部调用的可观测性分析,以实现海豚调度产品的自身服务优化。 我们使用 linkerd 作为 service mesh 的产品进行集成,linkerd 也是 cncf 优秀的毕业项目之一。

只需要在海豚 helm 的 value 文件中修改 annotations,重新部署,就可以快速实现 mesh proxy sidecar 的注入。可以对 master,worker,api,alert 等组件都注入。 annotations: #{}
linkerd.io/inject: enabled
可以观察组件之间的服务通信质量,每秒请求的次数等等。
未来海豚调度基于云原生技术的展望
-
和 argo-workflow 的集成,可以通过 api,cli 等方式在海豚调度中调用argo-workflow 单个作业,dag 作业,以及周期性作业; -
使用 hpa 的方式,自动扩缩容 worker,实现无人干预的水平扩展方式; -
集成 kubernetes 的 spark operator 和 flink operator 工具,全面的云原生化; -
实现多云和多集群的分布式作业调度,强化 serverless+faas 类的架构属性; -
采用 sidecar 实现定期删除 worker 作业日志,进一步实现无忧运维;
最后,强力推荐大家使用slack进行海豚社区交流,官方推荐!
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手
微信(Leonard-ds) 手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
https://dolphinscheduler.apache.org/


