
点亮 ⭐️ Star · 照亮开源之路
https://github.com/apache/dolphinscheduler

01
DolphinScheduler与机器学习环境
实用项目
git clone https://github.com/jieguangzhou/dolphinscheduler-ml-tutorial.git
git checkout dev
安装环境
Conda
mlflow, dvc 命令会安装到conda的bin目录下。
pip install mlflow==1.30.0 dvc
Java8环境
sudo apt-get update
sudo apt-get install openjdk-8-jdk
java -version
配置Java环境变量, ~/.bashrc 或者 ~/.zshrc
# 确认你的jdk的目录是否为这个,配置环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
Apache DolphinScheduler 3.1.0
# 进入以下目录(可以在其他目录安装,为了方便复现,本文在以下目录安装)
cd first-example/install_dolphinscheduler
## install DolphinScheduler
wget https://dlcdn.apache.org/dolphinscheduler/3.1.0/apache-dolphinscheduler-3.1.0-bin.tar.gz
tar -zxvf apache-dolphinscheduler-3.1.0-bin.tar.gz
rm apache-dolphinscheduler-3.1.0-bin.tar.gz
## 配置conda环境和默认python环境
cp common.properties apache-dolphinscheduler-3.1.0-bin/standalone-server/conf
echo "export PATH=$(which conda)/bin:\$PATH" >> apache-dolphinscheduler-3.1.0-bin/bin/env/dolphinscheduler_env.sh
echo "export PYTHON_HOME=$(dirname $(which conda))/python" >> apache-dolphinscheduler-3.1.0-bin/bin/env/dolphinscheduler_env.sh
-
dolphinscheduler-mlflow配置在使用MLFLOW组件时会引用Github上的dolphinscheduler-mlflow项目,如网络无法畅通链接,可以按一下步骤替换仓库源 首先执行 git clone https://github.com/apache/dolphinscheduler-mlflow.git然后修改common.properties中 ml.mlflow.preset_repository字段值为下载后的绝对路径即可
## start DolphinScheduler
cd apache-dolphinscheduler-3.1.0-bin
bash bin/dolphinscheduler-daemon.sh start standalone-server
## 可以通过以下命令查看日志
# tail -500f standalone-server/logs/dolphinscheduler-standalone.log
admin,密码:dolphinscheduler123
MLflow
docker run --name mlflow -p 5000:5000 -d jalonzjg/mlflow:latest 启动即可
first-example/docker-mlflow/Dockerfile
02
组件介绍
Shell组件
SHELL组件用于运行shell类型任务。
Python组件
Conditions组件
MLFLOW组件
dolphinscheduler-mlflow库实现针对分类场景的预置算法和AutoML功能,部署MLflow tracking server上的模型。
DVC组件
-
SHELL组件和PYTHON组件为基础组件,可以运行广泛的任务; -
CONDITIONS为逻辑组件,可以动态控制工作流的运行逻辑; -
MLFLOW组件和DVC组件为机器学习类型组件,可以用于方便在工作流上方便使用机器学习场景特性能力。
03
机器学习Workflow
-
第一部分为前置的一些准备,比如数据下载,数据版本管理仓库建立等,为一次性准备工作; -
第二部分为训练模型工作流:包含数据预处理,训练模型和模型评估; -
第三部分为部署流程工作流:包含模型部署,接口测试。
前置准备工作流
mkdir /tmp/ds-ml-example
dolphinscheduler-ml-tutorial/first-example目录下运行
pydolphinscheduler 提交工作流,所以安装一下 pip install apache-dolphinscheduler==3.1.0
Workflow(download-data): 下载实验数据
pydolphinscheduler yaml -f pyds/download_data.yaml
-
install-dependencies: 安装下载脚本中需要的python依赖包 -
download-data: 下载数据集到/tmp/ds-ml-example/raw
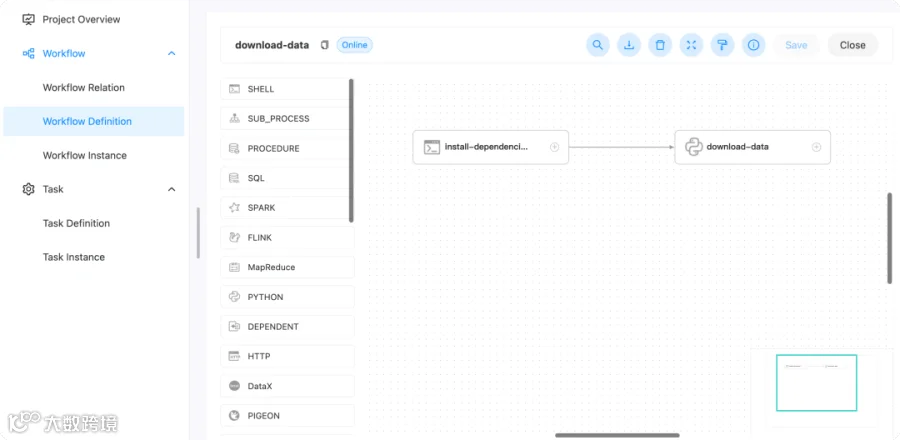
Workflow(dvc_init_local): 初始化DVC数据版本管理仓库
pydolphinscheduler yaml -f pyds/init_dvc_repo.yaml
-
create_git_repo: 本地创建一个空的git仓库 -
init_dvc: 将仓库转为dvc类型仓库,用于进行数据版本管理 -
condition: 判断init_dvc任务执行情况,若成功则执行report_success_message,否则执行report_error_message
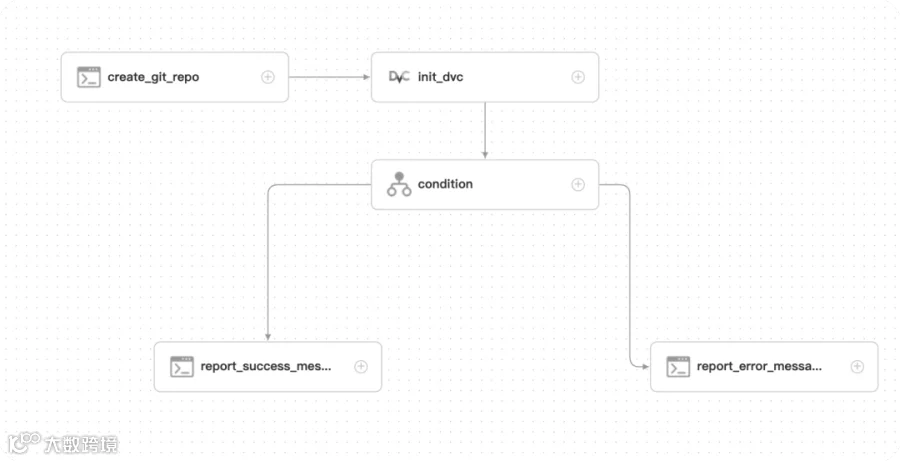
训练模型工作流
Workflow(download-data): 数据预处理
pydolphinscheduler yaml -f pyds/prepare_data.yaml
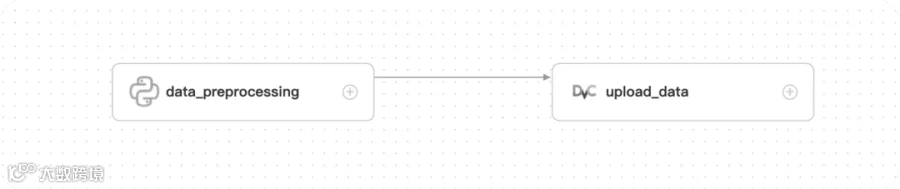
-
data_preprocessing: 进行数据预处理,这里为了演示,只做了简单的截断处理 -
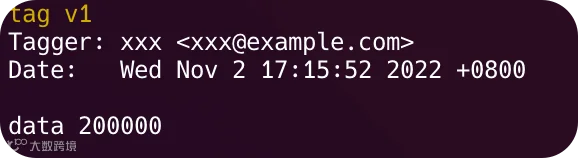
upload_data: 上传数据到仓库中,并注册为特定版本好 v1
Workflow(train_model): 训练模型
pydolphinscheduler yaml -f pyds/train_model.yaml
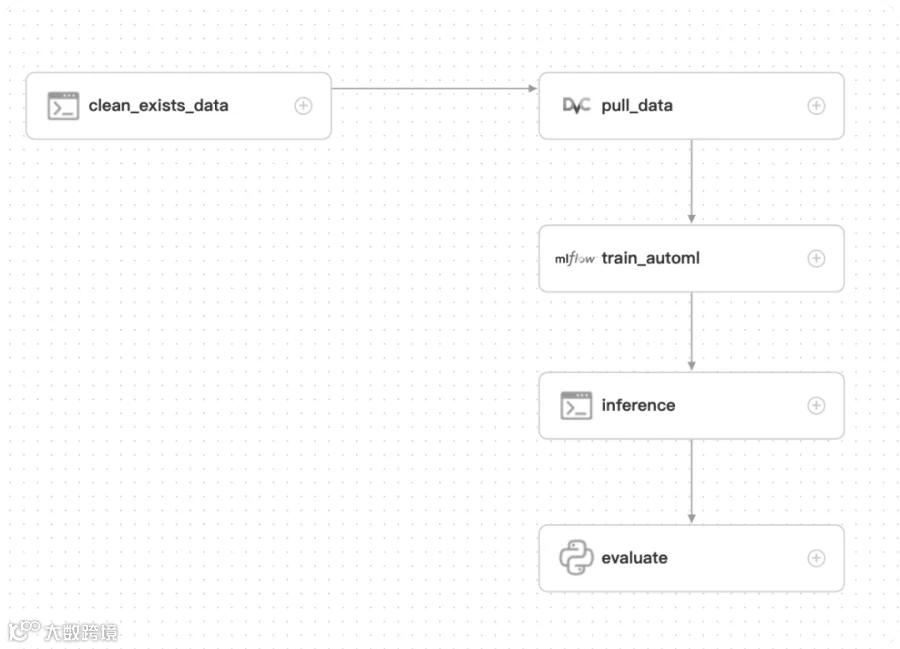
-
clean_exists_data: 删除可能重复实验时产生的历史数据/tmp/ds-ml-example/train_data -
pull_data: 拉取v1版本的数据到/tmp/ds-ml-example/train_data -
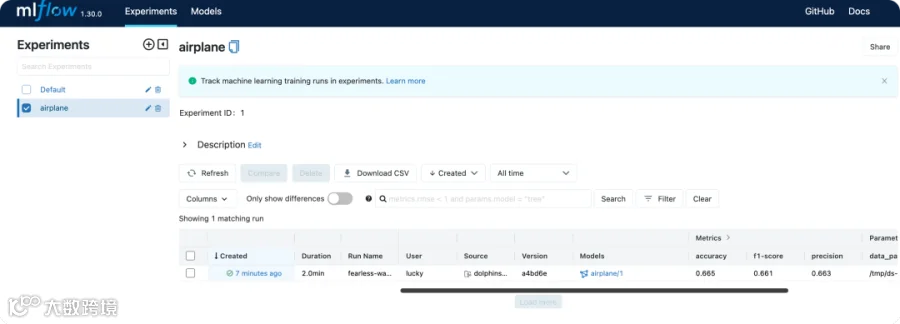
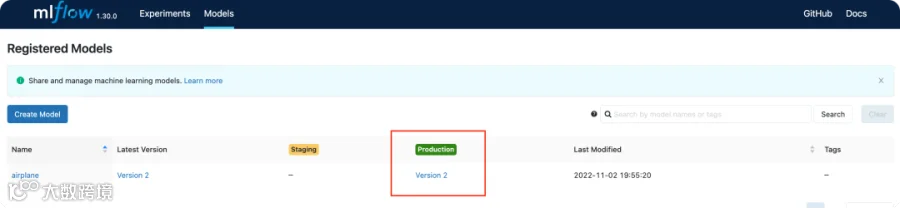
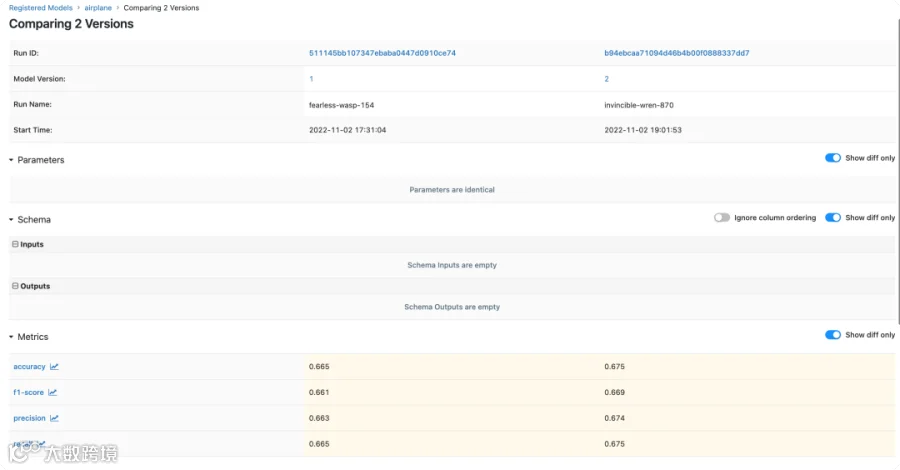
train_automl: 使用MLFLOW组件的AutoML功能训练分类模型,并注册到MLflow Tracking Server中,若当前模型版本F1为最高,则注册为Production版本。 -
inference: 传入要批量推理的小部分数据,使用mlflowCLI 进行批量推理 -
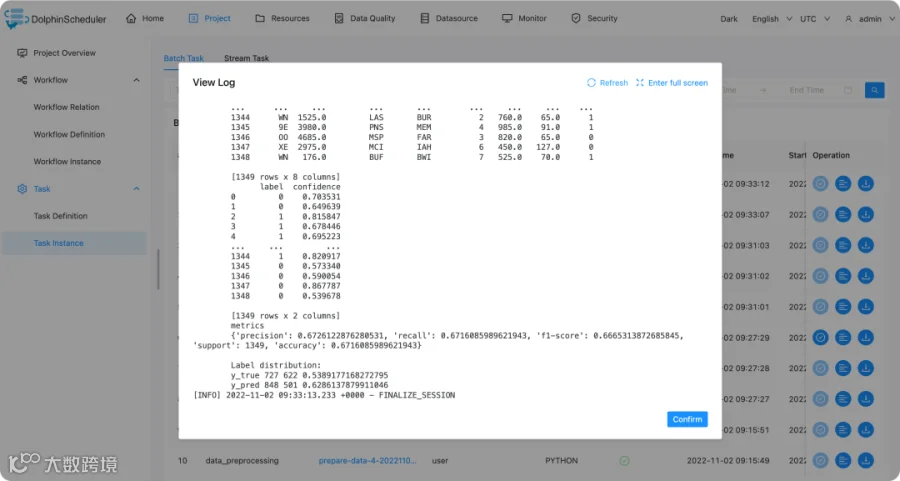
evaluate: 获取inference推理的结果,对模型再次进行简单的评估,包括新数据的指标,预测的label分布等。
部署工作流
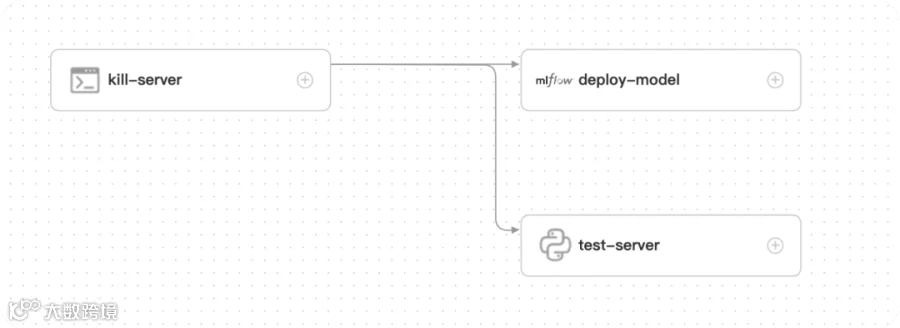
Workflow(deploy_model): 部署模型
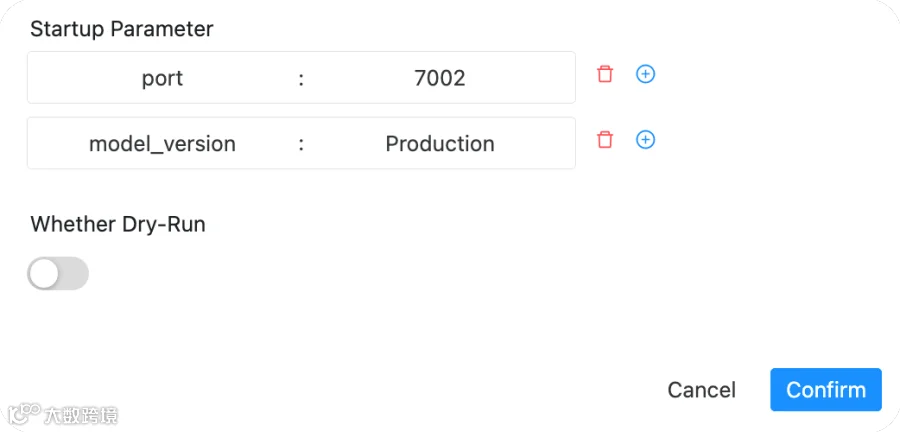
pydolphinscheduler yaml -f pyds/deploy.yaml
-
kill-server: 关闭之前的服务 -
deploy-model: 部署模型 -
test-server: 测试服务
整合工作流
git checkout first-example-production
-
多了一个train_and_deploy.yaml 的工作流定义,用于串联各个工作流 -
修改预处理脚本得到v2版本数据 -
将每个子工作流的定义中,是否运行的flag改为 false,由train_and_deploy.yaml统一运行.
pydolphinscheduler yaml -f pyds/train_and_deploy.yaml

04
总结
-
了解如果构建Apache DolphinScheduler, Conda, MLflow 服务环境; -
能够快速运行一个机器学习工作流。

海豚调度&Linkis强强结合
探索计算治理难题的终极密码
 扫码报名
扫码报名

添加小助手入交流群
