
功能需求背景
由于信创(信息技术应用创新产业)改造要求,上个月已将从数据仓库推送下游官网系统的ORACLE数据库相关数据推送任务迁移到信创人大金仓临时数据库,整体任务完成切换上线并试运行稳定。
由于年底需要进行信创数据库的正式上线,目前需要将人大金仓临时数据库切换到生产环境的人大金仓正式数据库,两者的区别仅仅在于数据库的IP和端口不同。
因为推送信创官网的表数据相关任务分散在 Apache DolphinScheduler (以下简称海豚调度)系统各个工作流之中,如何找到所有的推送任务并进行切换,保证所有的推送任务都能够完整覆盖是本次功能实现的难点。
方案设计
本次功能实现的方案设计方案如下图所示:
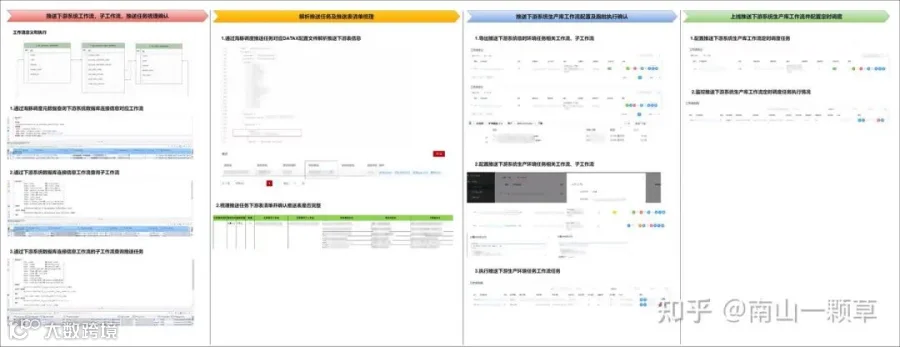
首先,通过海豚调度元数据中工作流定义相关表找到推送官网的相关工作流任务,梳理出相关工作流和子工作流,并通过工作流及子工作流找到对应的推送任务;
然后,通过解析DATAX推送任务JSON配置文件找到该任务对应推送目标表并整理出目标表清单,让下游系统(即官网系统)负责人确认梳理出的推送任务是否包括所有推送表;
接着,将之前完成配置并上线的工作流及子工作流导出并在开发环境进行配置,修改推送下游系统(即官网系统)的数据库连接信息,完成配置后上线并执行一次推送任务,当所有推送任务执行完成之后让下游系统负责人进行确认是否完成所有表的数据推送,每个表的推送数据量和属性字段是否正确;
最后,上线工作流任务并配置定时调度,并行运行信创人大金仓临时数据库和信创人大金仓生产数据库,待推送生产环境数据任务运行稳定后完成临时数据库下线。
工程实现
推送下游系统工作流、子工作流、推送任务梳理确认
针对以海豚调度系统构建数据仓库及采集推送任务而言,最重要的是如何设计及实施调度任务编排,同时,为了实现调度任务的整体管理,需要对工作流、子工作流及任务设置进行规范化构建。
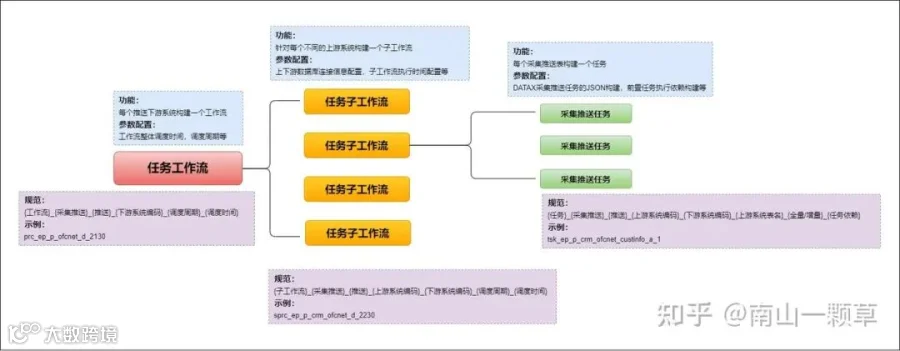
目前,调度任务编排主要由三部分组成
工作流配置:针对每个推送的下游系统配置一个调度工作流,工作流的参数设置主要包括调度时间及周期频率;
子工作流配置:根据不同的上游系统构建不同的子工作流,子工作流的参数设置主要包括上下游系统的连接信息配置,如果该子工作流的执行时间和工作流不一致,可以在子工作流之前设置执行开始时间;
调度任务配置:数据采集推送任务包括具体需要执行推送的表构建,属于子工作流,参数设置主要包括DATAX采集推送任务的JSON配置文件构建以及一些前置执行任务依赖构建等。
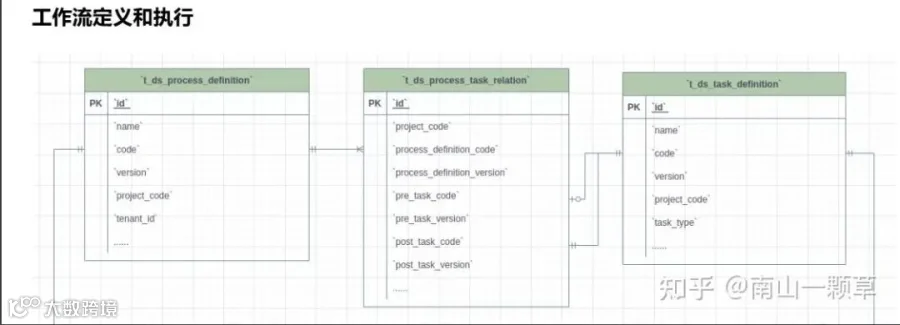
首先,需要通过海豚调度元数据中关于工作流定义、工作流任务依赖关系、执行任务相关表的关联关系筛选出下游系统的相关工作流及任务。
因为推送下游系统一般会对应唯一的数据库连接信息,通过筛选该连接信息将所有工作流及任务筛选出来。
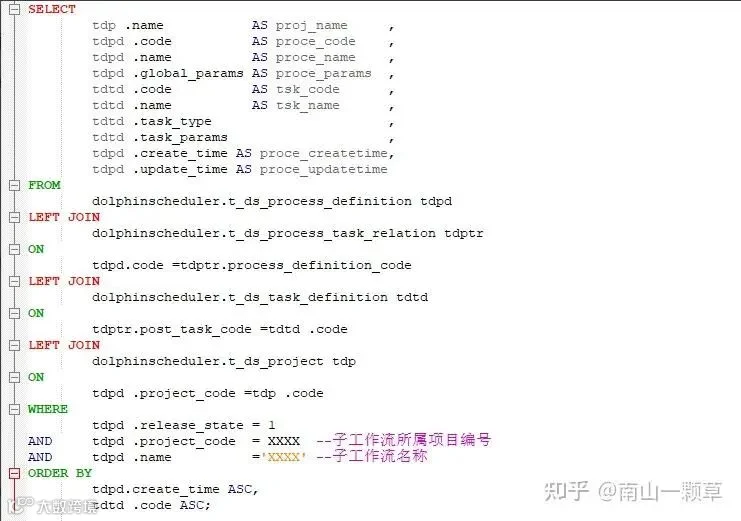
特别需要说明的是,子工作流既可作为工作流中的一个任务节点,同时自身也是一个工作流。海豚调度系统工作流定义、工作流任务关系、任务定义相关表依赖关系如下:
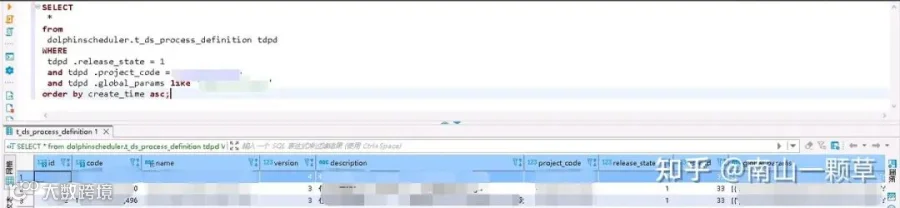
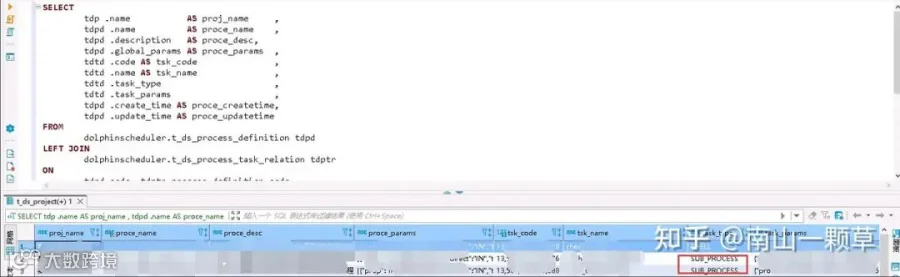
通过下游系统数据库连接信息筛选工作流及子工作流执行SQL示例如下,其中全局参数(global_params)配置格式为JSON,通过筛选下游系统数据库IP查询出相应对的工作流及子工作流:

通过筛选出来的工作流,即表dolphinscheduler.t\_ds\_process\_definition中的name属性后,通过筛选特定工作流的名称查询对应子工作流(task_type=SUB_PROCESS)。

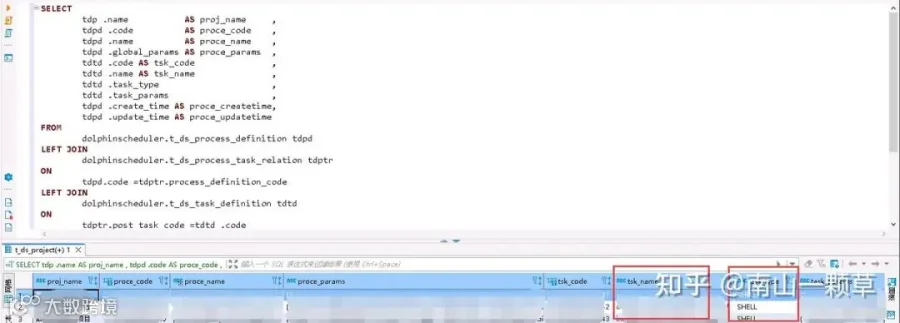
通过筛选出来的子工作流查询子工作流包含的数据推送任务,其中tsk\_name即为任务节点名称,tsk\_type=SHELL表明该数据推送任务是通过SHELL组件进行配置(通过调用DATAX配置JSON,并传参实现),也可以通过DATAX组件直接配置。
解析推送任务及推送表清单梳理
通过海豚调度元数据中工作流定义、工作流任务关系、任务定义表查询出推送下游系统表所属的工作流、子工作流和推送任务后,需要对每个表数据推送任务DATAX的JSON配置文件进行解析,提取下游系统目标表,该功能实现一般是用JSON解析工具包来完成。
数据推送配置任务,DATAX任务JSON配置,系统实现功能查询示例如下所示:
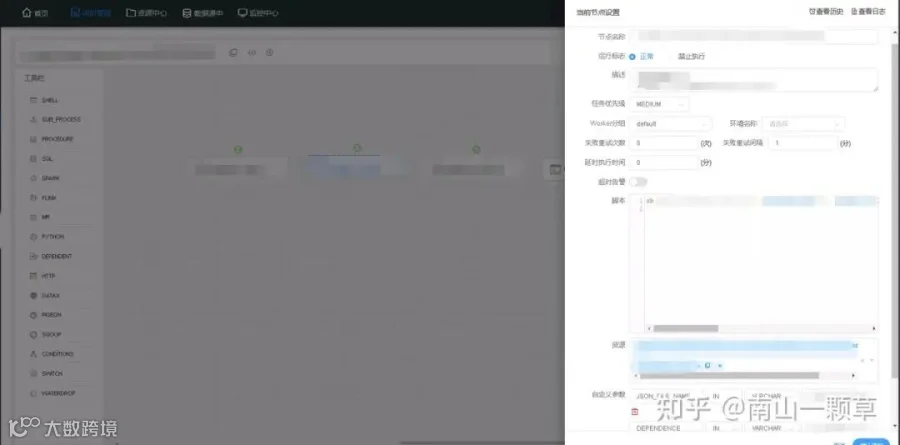
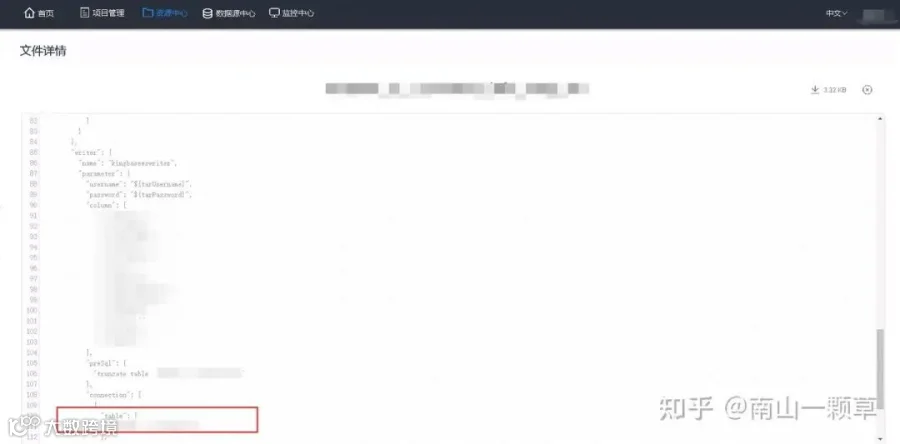

完成推送下游系统任务表梳理后,梳理出推送任务清单,并将该清单给到下游业务系统负责人,通过核对推送目标表来确认梳理出的推送任务是否完整。

推送下游系统生产库工作流配置及跑批执行确认
完成推送下游系统目标表核对并确认后,需要在预生产环境将梳理出来的海豚调度工作流、子工作流海豚进行配置,修改全局参数中下游数据库连接信息后,将工作流及子工作流上线并运行一次数据推送,确保推送信创官网生产环境数据库成功。
首先,导出已上线的推送下游系统的海豚调度工作流、子工作流。


然后,将导出后的工作流,子工作流在海豚调度预生产环境进行导入工作流,配置工作流、子工作流任务名称(例如在名称后加DEV,同时将导入工作流自动生成的“_import_20241220194957927”后缀去掉),配置工作流中“子工作流”节点并关联子工作流。



将配置好的工作流、子工作流上线,并手动执行一次推送任务。

上线推送下游系统生产库工作流并配置定时调度
在执行完所有推送下游系统工作流任务后,下游系统负责人对生产库中所有涉及到的表进行核对(括每个表的数据量核对,每个表属性字段核对),完成数据核对无误后,将所有工作流任务上线并设置定时调度任务。

在完成工作流配置后,需要定期监控相关工作流任务执行情况是否正常,同时,推送下游系统临时数据库及生产数据库同步运行一段时候后,确认没问题再将临时数据库进行下线。

本文完!
参与Apache DolphinScheduler 社区有非常多的参与贡献的方式,包括:
