
💡 本系列文章是 DolphinScheduler 由浅入深的教程,涵盖搭建、二开迭代、核心原理解读、运维和管理等一系列内容。适用于想对 DolphinScheduler了解或想要加深理解的读者。
祝开卷有益。
大家好,我是小陶,DolphinScheduler 运行一段时间之后,会积累大量的历史运行记录,这些记录主要包括:
-
工作流实例记录(MySQL) -
任务实例记录(MySQL) -
任务日志(本地磁盘)
其中 MySQL 的记录越来越多,会影响页面分页查询的速度,进而影响用户使用体验和 MySQL 服务。
所以,需要清理以上历史记录,保证页面影响速度和 MySQL 服务。
本文的内容也比较简单,先是说明 API 的逻辑、存在的bug和修复方法,最后再介绍如何使用一个 Python 脚本来调用 API 删除历史实例。
API 逻辑介绍
DolphinScheduler 本身提供了批量删除工作流实例的接口,process-instances/batch-delete,接口逻辑这里简单描述一下就是,找到工作流下面的任务实例,依次删除任务日志和 Mysql 记录。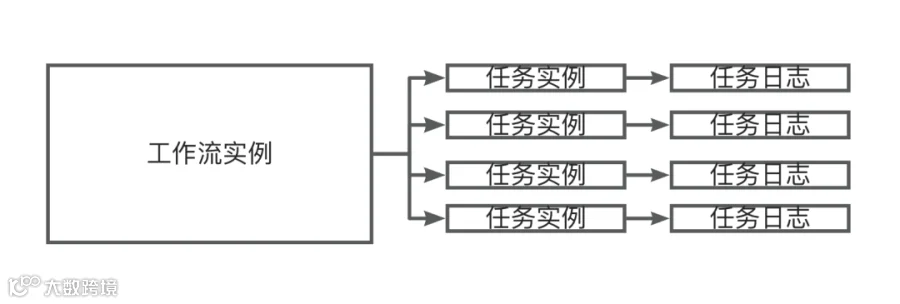
API bug说明和修复
但是这里需要注意的是,海豚调度 3.2.0(不包含)以前的版本,这里有一个 bug,在查询工作流实例下面的任务实例的时候,只查询了 flag =1 的任务实例,所以就导致了在清理日志和记录的时候,漏掉了一部分。
ProcessServiceImpl.java 中的 removeTaskLogFile 方法,在查询任务实例集合的时候,引用了 findValidTaskListByProcessId(processInstanceId); 而 findValidTaskListByProcessId 中仅查询了 Flag.YES 也就是 flag = 1 的记录。如下图所示: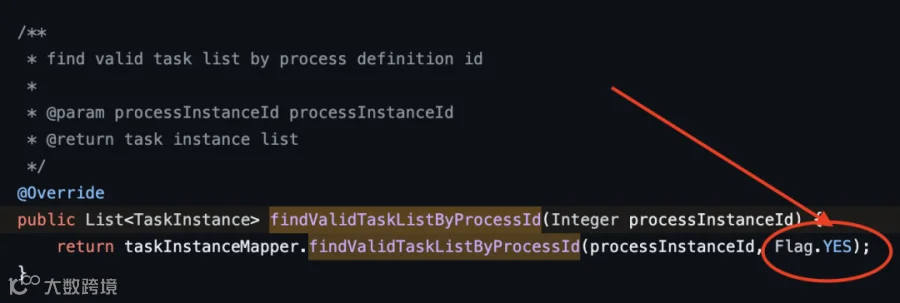
这里解释一下 flag = 1 是标识该任务的最新的运行记录,表示任务多次重试之后,最新的运行记录。如果任务第一次失败了,第二次重试之后成功了,那么这个任务就会有两条运行记录,flag = 0 和 falg = 1,flag =1 的则标识最新的运行记录。
所以,如果你在使用海豚调度 3.2.0(不包含)以前的版本的时候,需要自行修复一下,或者升级到 3.2.0 。
修复的方式,也比较简单,新增 findAllTaskListByProcessId 方法,把工作流实例所有的运行实例都拿出来,不要加 flag 这个过滤条件。
使用 Python 脚本调用API
Python脚本的逻辑比较简单,使用了三个API,按照顺序是:
1.获取项目列表
2.获取工作流列表
3.批量删除工作流实例
入参是:日期
具体的代码如下:
#!/usr/bin/python
# -*- coding: utf8 -*-
## 定时清理调度工作流记录,入参是日期
import io
import subprocess
import requests
import json
import time
import datetime
from optparse import OptionParser
from optparse import OptionGroup
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(module)s : %(message)s', level=logging.INFO,
stream=sys.stdout)
logger = logging.getLogger(__name__)
# 配置信息: ip 端口 token自行修改
base_url = 'http://IP:端口'
token = 'xxxxxxxxxxxxx'
# get args
def get_option_parser(params):
usage = "usage: %prog [options] json-url"
parser = OptionParser(usage=usage)
prodEnvOptionGroup = OptionGroup(parser, "Product Env Options",
"Normal user use these options to set jvm parameters, job runtime mode etc. "
"Make sure these options can be used in Product Env.")
for k in params:
prodEnvOptionGroup.add_option("--" + k, metavar="<" + k + ">", dest=k, action="store", default="",
help="" + params[k])
parser.add_option_group(prodEnvOptionGroup)
return parser
# 获取项目列表
def get_project_list():
url = "{base_url}/dolphinscheduler/projects?pageSize=100&pageNo=1&searchVal=&_t=0.3741042528841678".format(base_url=base_url)
payload={}
headers = {
'Connection': 'keep-alive',
'Accept': 'application/json, text/plain, */*',
'language': 'zh_CN',
'sessionId': '680b2a0e-624c-4804-9e9e-58c7d4a0b44c',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'Referer': "{base_url}/dolphinscheduler/ui/".format(base_url=base_url),
'Accept-Language': 'zh-CN,zh;q=0.9,pt;q=0.8,en;q=0.7',
'token':token
}
response = requests.request("GET", url, headers=headers, data=payload)
response_data = json.loads(response.text)
totalList = response_data['data']['totalList']
return totalList
def get_page_detail(code,dt):
url = "{base_url}/dolphinscheduler/projects/{code}/process-instances?searchVal=&pageSize=50&pageNo=1&host=&stateType=&startDate=2000-01-01 00:00:00&endDate={dt} 23:59:59&executorName=".format(code=code,dt=dt,base_url=base_url)
payload={}
headers = {
'Connection': 'keep-alive',
'Accept': 'application/json, text/plain, */*',
'language': 'zh_CN',
'sessionId': '680b2a0e-624c-4804-9e9e-58c7d4a0b44c',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'Referer': "{base_url}/dolphinscheduler/ui/".format(base_url=base_url),
'Accept-Language': 'zh-CN,zh;q=0.9,pt;q=0.8,en;q=0.7',
'token':token
}
response = requests.request("GET", url, headers=headers, data=payload)
response_data = json.loads(response.text)
page = response_data['data']['totalList']
page_del = 'processInstanceIds='
if len(page) == 0:
print('列表为空,退出程序')
return '0'
for p in page:
page_del = page_del + str(p['id']) + ','
# print(page_del)
return page_del
def delete(project,ids):
print('即将删除如下工作流实例:')
print(project)
print(ids)
url = "{base_url}/dolphinscheduler/projects/{project}/process-instances/batch-delete".format(base_url=base_url,project = project)
# 'processInstanceIds=89767'
payload= ids
headers = {
'Connection': 'keep-alive',
'Accept': 'application/json, text/plain, */*',
'language': 'zh_CN',
'sessionId': '680b2a0e-624c-4804-9e9e-58c7d4a0b44c',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded',
'Referer': "{base_url}/dolphinscheduler/ui/".format(base_url=base_url),
'Accept-Language': 'zh-CN,zh;q=0.9,pt;q=0.8,en;q=0.7',
'token':token
}
response = requests.request("POST", url, headers=headers, data=payload)
print('执行结果如下:')
print(response.text)
if __name__ == '__main__':
#获取请求参数()
params = {"dt": "dt"};
parser = get_option_parser(params)
options, args = parser.parse_args(sys.argv[1:])
logger.info('开始执行删除任务实例...' + " ".join(sys.argv))
# 清理的日期
dt = options.dt
if dt == '' or len(dt) == 0:
logger.error('调度系统-运维任务:日期为空,请输入日期')
sys.exit(1)
today_91 = (datetime.datetime.now()+datetime.timedelta(days=-61)).strftime("%Y-%m-%d")
short_dt = dt.replace('-','')
short_today_91 = today_91.replace('-','')
if int(short_dt) > int(short_today_91):
logger.error('调度系统-运维任务:不能删除最近90天之内的任务实例')
sys.exit(1)
# # 需要处理的项目
projects = get_project_list()
# 依次处理项目
for project in projects:
code = project['code']
print('正在处理:'+ str(code))
while True:
page_del = get_page_detail(code,dt)
if page_del == '0':
break
delete(code,page_del)
time.sleep(1)
使用示例:dolphin_clean_process.py 是上面的脚本。
python dolphin_clean_process.py 2024-01-01
脚本在 GitHub 也维护了一份,欢迎 star 👇
https://github.com/aikuyun/dolphin_practices/blob/main/dolphin_clean_process.py
注意事项
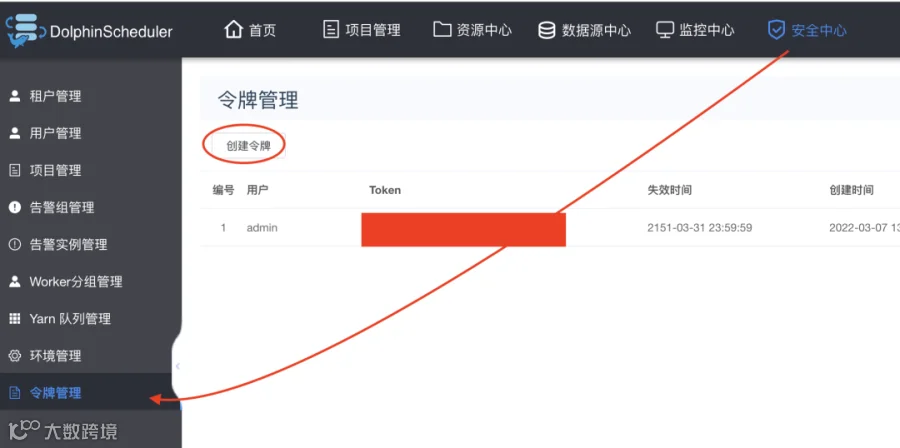
1.token 获取的方式
2.可以删除的工作流的状态是一定要是完成状态的。否则,接口就会报错,非完成状态的工作流是不可以删除的。可以通过下面的SQL查看某个日期之前是否存在非完成状态的工作流实例。
SELECT *
FROM t_ds_process_instance
where state not in (7 ,13 ,6 ,8 ,5 ,9 ,3)
and start_time < '2024-01-01'
以上就使用 API 轻松清理历史工作流实例以及日志文件的全部内容,如果有任何疑问,都可以与我交流,希望可以帮到你,下次见。
参与Apache DolphinScheduler 社区有非常多的参与贡献的方式,包括:
