

点击蓝字 关注我们

在数字化转型浪潮席卷全球的今天,智能制造已成为制造业高质量发展的核心引擎。然而,在迈向智能化的道路上,企业面临着诸多挑战:多系统数据孤岛、复杂的调度依赖、监控告警滞后等问题层出不穷。
在近期的 Apache DolphinScheduler 线上用户交流会上,社区邀请到了深圳某大型智能制造企业高级软件工程师 邱忠标,现场为大家带来一场关于 Apache DolphinScheduler 在该企业智能制造业务场景中的应用实践分享。现将活动演讲核心内容整理成为,深入探讨这家企业是如何通过 Apache DolphinScheduler 实现企业调度平台质的飞跃。
关于
作者
PROFILE
邱忠标
深圳某大型智能制造企业 高级软件工程师,专注于智能制造领域的数据技术研究与实践,致力于推动制造业数字化转型。

智能制造的
时代背景
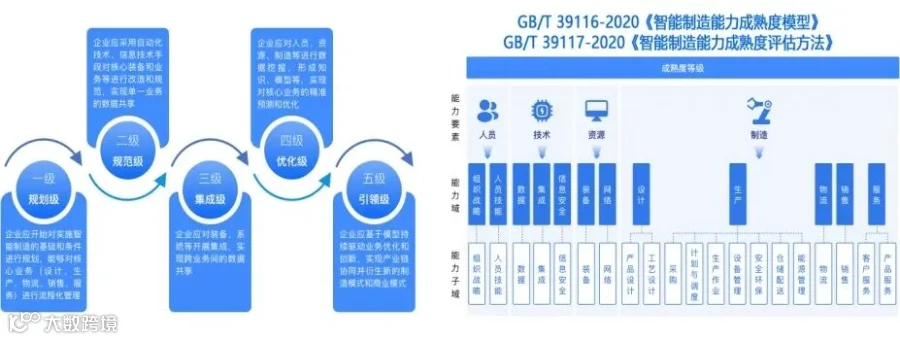
随着工业4.0的深入推进,智能制造已成为各国制造业竞争的焦点。智能制造成熟度模型从低到高分为多个层级,企业需要逐步提升自动化、数字化、网络化水平,最终实现智能化生产。在这一进程中,数据成为核心生产要素,如何高效、稳定地采集、处理和调度这些数据,成为摆在每个制造企业面前的难题。
现代制造企业的数据环境日益复杂。一方面,企业拥有众多业务系统:MES生产执行系统、ERP企业资源管理、WMS仓库管理、WCS仓库控制、CRM客户关系管理、QMS质量管理系统、PLM产品生命周期管理、SCM供应链管理、APS高级计划排程等。这些系统之间的数据交互往往采用编码方式实现,导致系统间关系错综复杂,维护成本高昂,扩展性差,故障排查困难。
另一方面,企业还面临着复杂的网络环境,包括集团生产网络、工厂内部网络、国际国内专线网络,不同网络环境下的数据采集、传输和调度需求各异,如何实现统一管理和任务隔离成为一大挑战。
传统数据处理
方式的困境
传统数据处理
方式的困境
在智能制造行业推进数据化的过程中,企业正面临多维度的痛点。

首先是数据多样化带来的基础壁垒:设备协议类型繁杂,涵盖PLM/S7等专用协议与MQTT等通用协议,数据格式又包含二进制、半结构化等多种类型,再加上供应商与产线的差异,导致数据标准难以统一。
在此基础上,跨系统与跨工厂的数据协同难度突出:链路涉及设备、多系统与异地工厂等多个环节,网络环境混杂着内网、专线与外网,而排产、产能计算等业务又对数据实时性要求极高,进一步加剧了协同的复杂性。
同时,数据的可视化与追溯能力不足:传统系统无法直观呈现数据流转节点,日志分散存储导致异常排查低效,完整追溯体系的搭建还需投入大量人力。
最后,数据采集质量缺乏保障:网络、设备等多类异常频发,且异常检测滞后、人工恢复效率低,多系统交互时的故障定位还依赖对全链路的熟悉,进一步影响了数据的可靠性。
DolphinScheduler
的解决方案
面对上述痛点,Apache DolphinSchedule 提供了完整的解决方案。作为一款分布式、易扩展的可视化工作流调度平台,它在制造业的实践中展现出强大的能力。
Worker 节点分组:多网络环境适配方案
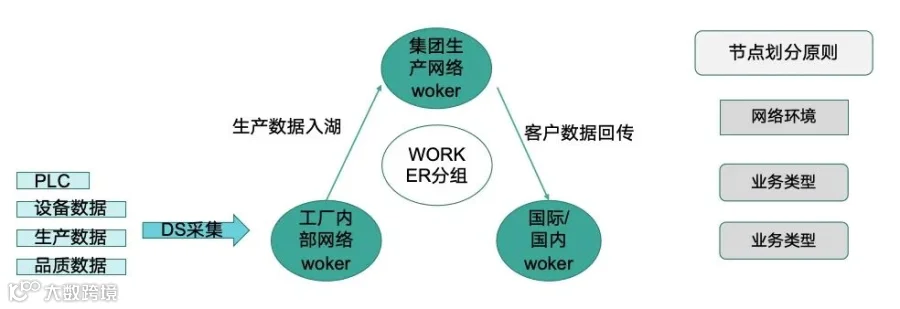
在Worker节点分组方面,Apache DolphinScheduler针对制造企业的复杂网络环境设计了灵活的隔离策略。通过将Worker节点按照网络环境划分为集团生产网络Worker、工厂内部网络Worker、国际/国内专线Worker,并按照业务类型划分为PLC设备数据采集、生产数据处理、品质数据分析等不同组别,实现了不同网络环境、不同业务场景的任务隔离,确保数据采集的安全性和可靠性。
这一方案有效支持了生产数据入湖、客户数据回传、跨网络数据同步等关键应用场景。
数据采集
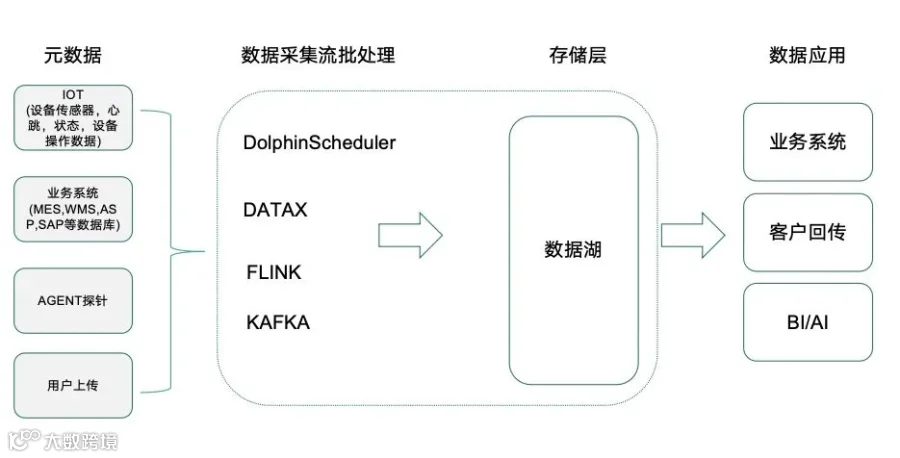
在数据采集方面,Apache DolphinScheduler构建了完整的数据处理链路。数据源层涵盖了IoT设备(包括设备传感器、心跳数据、状态监控、设备操作数据)、业务系统(MES、WMS、ASP、SAP等数据库)、AGENT探针以及用户上传数据。处理引擎采用DataX进行离线数据同步、Flink进行实时流处理、Kafka作为消息队列缓冲,最终统一入湖,支持BI分析和AI应用。通过Apache DolphinScheduler的统一调度,企业可以实现从数据采集、处理到应用的全链路管理。
数据交互
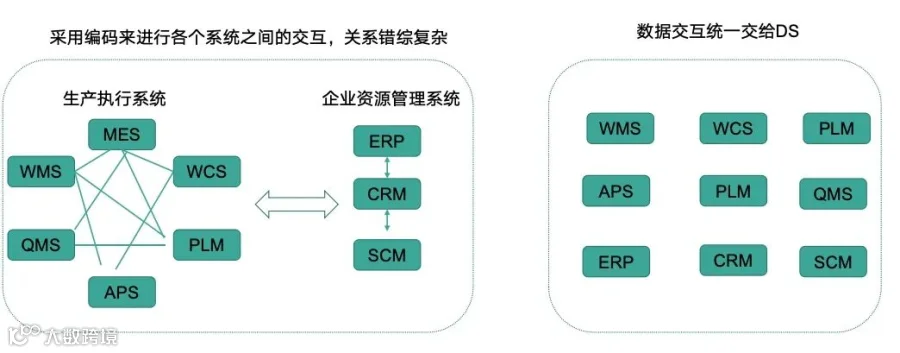
传统模式下,各系统之间点对点交互,关系错综复杂。引入 Apache DolphinScheduler 后,所有数据交互统一通过调度中心进行,实现了集中管理所有数据交互任务、可视化监控任务运行状态、统一异常处理和告警机制,同时降低了系统间耦合度,提高了数据交互的可靠性。
多工厂模板化数据采集与分发
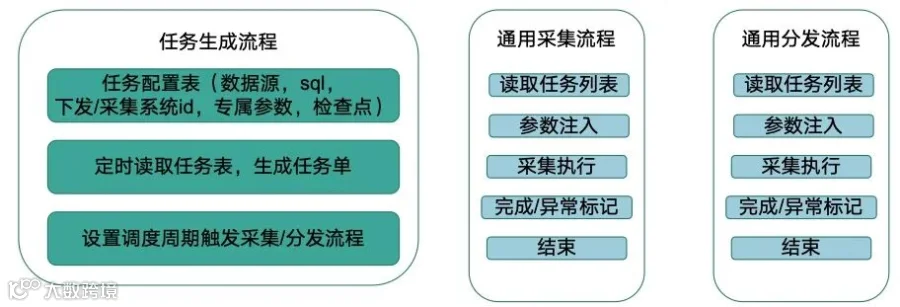
对于拥有多工厂的制造企业,Apache DolphinScheduler 提供了模板化解决方案。同质化的系统(如统一MES/WMS、同类型PLC设备)如何实现快速部署?通过将核心流程(读取任务列表、参数注入、采集/分发执行、完成/异常标记)固化为通用模板,再结合任务配置表(包括数据源配置、SQL语句、下发/采集系统ID、专属参数、检查点设置),实现了"模板通用 + 参数个性化"的灵活模式。
这种模板化方案带来了显著优势:
-
参数化配置使得核心流程固化为模板,工厂专属参数(IP、账号、路径)单独配置。 -
批量部署能力让企业能够在1天内完成数十个工厂部署,大幅提升效率。 -
统一迭代机制确保模板修改后,工厂自动同步更新,无需逐厂调整。 -
灵活扩展特性支持模板版本管理,可基于基础模板衍生不同工厂的定制化模板(如部分工厂需额外数据字段)。 -
跨场景支持既适配"多工厂数据采集至总部",也支持"总部数据分发至多工厂"(如统一生产计划下发)。
质的飞跃:
工业化流水线形成
质的飞跃:
工业化流水线形成
引入 Apache DolphinScheduler 后,企业在数据处理方面实现了质的飞跃。
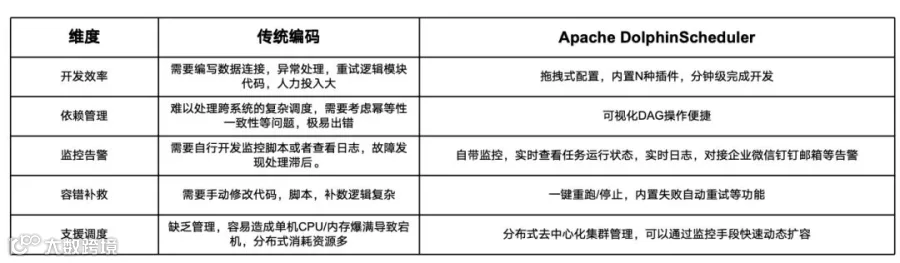
传统编码方式需要编写数据连接、异常处理、重试逻辑模块代码,人力投入大;而Apache DolphinScheduler采用拖拽式配置,内置N种插件,分钟级即可完成开发。在依赖管理方面,传统方式难以处理跨系统的复杂调度,需要考虑幂等性一致性等问题,极易出错;而Apache DolphinScheduler的可视化DAG操作便捷直观。
监控告警能力的提升尤为明显。传统方式需要自行开发监控脚本或查看日志,故障发现处理滞后;而 Apache DolphinScheduler 自带监控,支持实时查看任务运行状态和实时日志,并可对接企业微信、钉钉、邮箱等多种告警渠道。在容错补救方面,传统方式需要手动修改代码、脚本,补数逻辑复杂;而 Apache DolphinScheduler 提供一键重跑/停止功能,内置失败自动重试等机制。
资源调度能力的提升也不容忽视。传统方式缺乏统一管理,容易造成单机CPU/内存爆满导致宕机,分布式消耗资源多;而Apache DolphinScheduler采用分布式去中心化集群管理,可以通过监控手段快速动态扩容,实现资源的精细化管理。
这些改进为不同层面带来了实实在在的价值。

在开发层面,拖拉拽的开发方式降低了技术门槛,参数自动化提高了开发效率,日志秒级定位缩短了故障排查时间,运维成本显著降低。
在业务层面,可视化监控让任务状态一目了然,多渠道告警保障确保问题及时响应,灵活的补数策略应对各种异常情况,跨系统协调统一管理数据流,同时减少了对开发人员的过度依赖。
在决策层面,去个人化的特点让知识沉淀为组织资产,不会因为人员流动而流失;完整的操作审计记录满足了合规要求;数据库配置集中管理降低了安全风险;流程透明化便于管理和优化;资源使用情况量化支持了精细化决策。这些价值共同构成了企业数字化转型的坚实基础。
实践成果
与未来展望
通过 Apache DolphinScheduler 的实践应用,这家智能制造企业在多个维度实现了显著提升,包括开发效率提升,部署周期缩短,运维成本和人力投入大幅减少,任务成功率大幅提升,而且支持快速扩张,新增工厂 1 天内即可完成部署,实现了流程标准化、管理透明化、决策数据化。
展望未来,随着智能制造的深入推进,数据调度将扮演越来越重要的角色。Apache DolphinScheduler 作为开源项目,将在多个方向持续演进。AI 赋能方面,将引入 AI 能力实现智能调度和预测性维护;云原生方面,将深度适配云原生架构,提升弹性伸缩能力;生态扩展方面,将丰富插件生态,覆盖更多业务场景。
结
语
在智能制造的征程上,数据调度不是终点,而是起点。Apache DolphinScheduler 帮助企业解决了数据处理的"最后一公里"问题,让企业能够更专注于业务创新和价值创造。数字化转型,道阻且长,但行则将至。愿更多的制造企业能够借助开源力量,实现从"制造"到"智造"的华丽转身!


用户案例

迁移实战

发版消息

加入社区
关注社区的方式有很多:
-
GitHub: https://github.com/apache/dolphinscheduler -
官网:https://dolphinscheduler.apache.org/en-us -
订阅开发者邮件:dev@dolphinscheduler@apache.org(向邮箱发送任意内容,收到邮件后回复同意订阅即可) -
X.com:@DolphinSchedule -
YouTube:https://www.youtube.com/@apachedolphinscheduler -
Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
📂非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
👩💻代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。

你的好友秀秀子拍了拍你
并请你帮她点一下“分享”