

点击蓝字,关注我们

01
概述
02
环境准备
-
dolphinscheduler集群 >= 3.1.5 -
dolphinscheduler3.1.5版本源码 -
Seatunnel集群 >= 2.3.3
03
配置文件修改
Dolphinscheduler的配置文件修改
$DOLPHINSCHEDULER_HOME/bin/env/dolphinscheduler_env.sh。
SEATUNNEL_HOME的访问目录,将SEATUNNEL_HOME设置为你自己的SeaTunnel安装目录。
export SEATUNNEL_HOME=${SEATUNNEL_HOME:-/opt/software/seatunnel-2.3.5}Dolphinscheduler部分源码修改
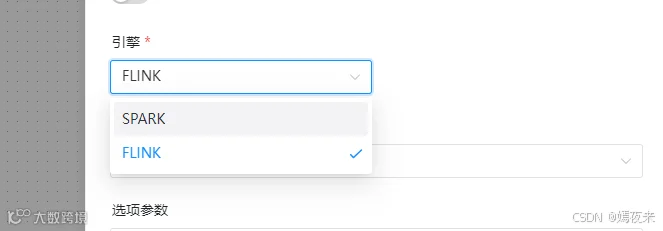
因为我这里使用的Seatunnel的版本是2.3.5,使用的引擎不是Seatunnel的默认引擎, 用的是Spark引擎, Spark我用的版本是2.4.5, 所有我最后在命令执行的命令如下:
$SEATUNNEL_HOME/bin/start-seatunnel-spark-2-connector-v2.sh --master local[4] --deploy-mode client --config /opt/software/seatunnel-2.3.5/config/app-config/v2.batch.config.template
$SEATUNNEL_HOME/bin/start-seatunnel-spark-3-connector-v2.sh --master local[4] --deploy-mode client --config /opt/software/seatunnel-2.3.5/config/app-config/v2.batch.config.template
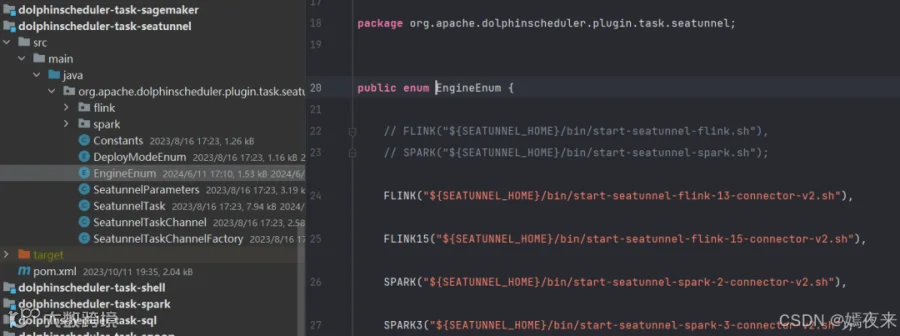
public enum EngineEnum {
// FLINK("${SEATUNNEL_HOME}/bin/start-seatunnel-flink.sh"),
// SPARK("${SEATUNNEL_HOME}/bin/start-seatunnel-spark.sh");
FLINK("${SEATUNNEL_HOME}/bin/start-seatunnel-flink-13-connector-v2.sh"),
FLINK15("${SEATUNNEL_HOME}/bin/start-seatunnel-flink-15-connector-v2.sh"),
SPARK("${SEATUNNEL_HOME}/bin/start-seatunnel-spark-2-connector-v2.sh"),
SPARK3("${SEATUNNEL_HOME}/bin/start-seatunnel-spark-3-connector-v2.sh");
private String command;
EngineEnum(String command) {
this.command = command;
}
public String getCommand() {
return command;
}
}
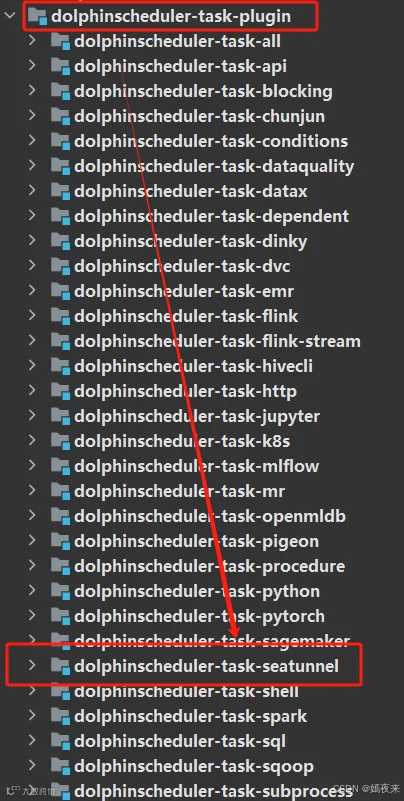
更新Dolphinscheduler集群中的SeaTunnel任务插件
olphinscheduler-task-seatunnel工程下的target目录下的dolphinscheduler-task-seatunnel-3.1.5.jar包, 上传到你的dolphinscheduler集群的主节点。
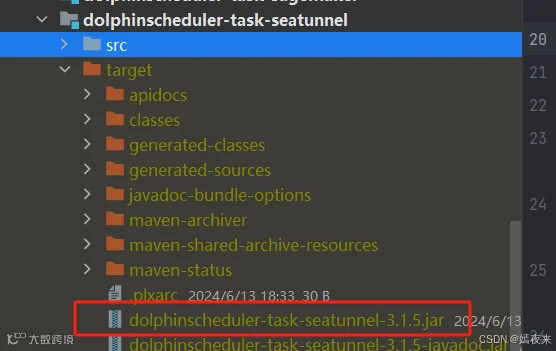
api-server/libs、master-server/libs、worker-server/libs、alert-server/libs目录(其实这里可以只替换woker-server/libs目录)下的dolphinscheduler-task-seatunnel-3.1.5.jar重命名为dolphinscheduler-task-seatunnel-3.1.5.jar.20240606(带上日期方便知道变更时间)。

dolphinscheduler-task-seatunnel-3.1.5.jar拷贝到这几个目录(api-server/libs、master-server/libs、worker-server/libs、alert-server/libs目录,确认一下是不是所有目录下都有这个dolphinscheduler-task-seatunnel-3.1.5.jar,没有的目录就直接略过)下。
api-server/libs、master-server/libs、worker-server/libs、alert-server/libs的修改同步到其他的DS节点上,分发完成之后,检查一下分发是否成功。
04
测试验证
-
Source: https://seatunnel.incubator.apache.org/zh-CN/docs/category/source-v2 -
Transform: https://seatunnel.incubator.apache.org/zh-CN/docs/category/transform-v2 -
Sink: https://seatunnel.incubator.apache.org/zh-CN/docs/category/sink-v2/
Source输入源配置定义说明
简单任务示例
# Defining the runtime environment
env {
parallelism = 4
job.mode = "BATCH"
}
source{
Jdbc {
url = "jdbc:oracle:thin:@datasource01:1523:xe"
driver = "oracle.jdbc.OracleDriver"
user = "root"
password = "123456"
query = "SELECT * FROM TEST_TABLE"
}
}
transform {}
sink {
Console {}
}
按分区列并行任务示例
env {
parallelism = 4
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:oracle:thin:@datasource01:1523:xe"
driver = "oracle.jdbc.OracleDriver"
connection_check_timeout_sec = 100
user = "root"
password = "123456"
# 根据需要定义查询逻辑
query = "SELECT * FROM TEST_TABLE"
# 设置并行分片读取字段
partition_column = "ID"
# 分区切片数量
partition_num = 10
properties {
database.oracle.jdbc.timezoneAsRegion = "false"
}
}
}
sink {
Console {}
}
按主键或唯一索引并行任务示例
env {
parallelism = 4
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:oracle:thin:@datasource01:1523:xe"
driver = "oracle.jdbc.OracleDriver"
connection_check_timeout_sec = 100
user = "root"
password = "123456"
table_path = "DA.SCHEMA1.TABLE1"
query = "select * from SCHEMA1.TABLE1"
split.size = 10000
}
}
sink {
Console {}
}
并行上下限任务示例
source {
Jdbc {
url = "jdbc:oracle:thin:@datasource01:1523:xe"
driver = "oracle.jdbc.OracleDriver"
connection_check_timeout_sec = 100
user = "root"
password = "123456"
# Define query logic as required
query = "SELECT * FROM TEST_TABLE"
partition_column = "ID"
# Read start boundary
partition_lower_bound = 1
# Read end boundary
partition_upper_bound = 500
partition_num = 10
}
}
多表读取任务示例
env {
job.mode = "BATCH"
parallelism = 4
}
source {
Jdbc {
url = "jdbc:oracle:thin:@datasource01:1523:xe"
driver = "oracle.jdbc.OracleDriver"
connection_check_timeout_sec = 100
user = "root"
password = "123456"
"table_list"=[
{
"table_path"="XE.TEST.USER_INFO"
},
{
"table_path"="XE.TEST.YOURTABLENAME"
}
]
#where_condition= "where id > 100"
split.size = 10000
#split.even-distribution.factor.upper-bound = 100
#split.even-distribution.factor.lower-bound = 0.05
#split.sample-sharding.threshold = 1000
#split.inverse-sampling.rate = 1000
}
}
sink {
Console {}
}
Sink输出源配置定义说明
简单任务示例
env {
parallelism = 1
job.mode = "BATCH"
}
source {
FakeSource {
parallelism = 1
result_table_name = "fake"
row.num = 16
schema = {
fields {
name = "string"
age = "int"
}
}
}
}
transform {}
sink {
jdbc {
url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "123456"
query = "insert into test_table(name,age) values(?,?)"
}
}
生成输出SQL任务示例
sink {
jdbc {
url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "123456"
# 根据数据库表名自动生成sql语句
generate_sink_sql = true
database = test
table = test_table
}
}
精确任务示例
sink {
jdbc {
url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
max_retries = 0
user = "root"
password = "123456"
query = "insert into test_table(name,age) values(?,?)"
is_exactly_once = "true"
xa_data_source_class_name = "com.mysql.cj.jdbc.MysqlXADataSource"
}
}
CDC(变更数据捕获)事件
sink {
jdbc {
url = "jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
user = "root"
password = "123456"
generate_sink_sql = true
# You need to configure both database and table
database = test
table = sink_table
primary_keys = ["id","name"]
field_ide = UPPERCASE
schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"
data_save_mode="APPEND_DATA"
}
}
完整测试脚本配置文件
env {
parallelism = 4
job.mode = "BATCH"
}
source{
Jdbc {
url = "jdbc:oracle:thin:@192.168.11.101:15210:YLAPP"
driver = "oracle.jdbc.OracleDriver"
user = "appuser001"
password = "appuser001"
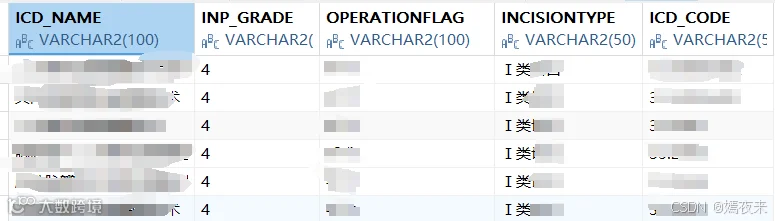
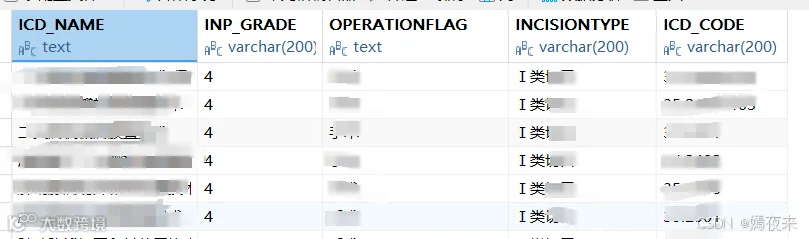
query = "SELECT * FROM YL_APP.MET_COM_ICDOPERATION_LS"
}
}
transform {}
sink {
jdbc {
url = "jdbc:mysql://192.168.10.210:13306/yl-app-new?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true"
driver = "com.mysql.cj.jdbc.Driver"
user = "appuser001"
password = "appuser001"
generate_sink_sql = "true"
database = "hive"
table = "met_com_icdoperation_ls"
schema_save_mode = "CREATE_SCHEMA_WHEN_NOT_EXIST"
data_save_mode="APPEND_DATA"
}
}

参与Apache DolphinScheduler 社区有非常多的参与贡献的方式,包括:


球分享

球点赞

球在看