

点击蓝字,关注我们

作者 | 师彬杰,Zoom 数据平台工程师
整理 | Apache DolphinScheduler 社区运营组
随着业务规模扩大和数据形态复杂化,Zoom 在调度系统上的需求也从传统的批处理调度扩展到了对流处理任务的统一管理。为此,Zoom 选择 Apache DolphinScheduler 作为底层调度框架,构建了一个支持批流一体的调度平台,并结合 Kubernetes、多云部署等现代化基础设施进行了深度定制与优化。本文将结合 Zoom 实际业务落地过程中的经验,深入解读这一系统的设计演进、关键问题应对与未来规划。
1
背景与挑战:从批处理向流处理拓展
在早期阶段,Zoom 的数据平台以 Spark SQL 批处理任务为主,调度任务通过 DolphinScheduler 的标准插件运行于 AWS EMR 上。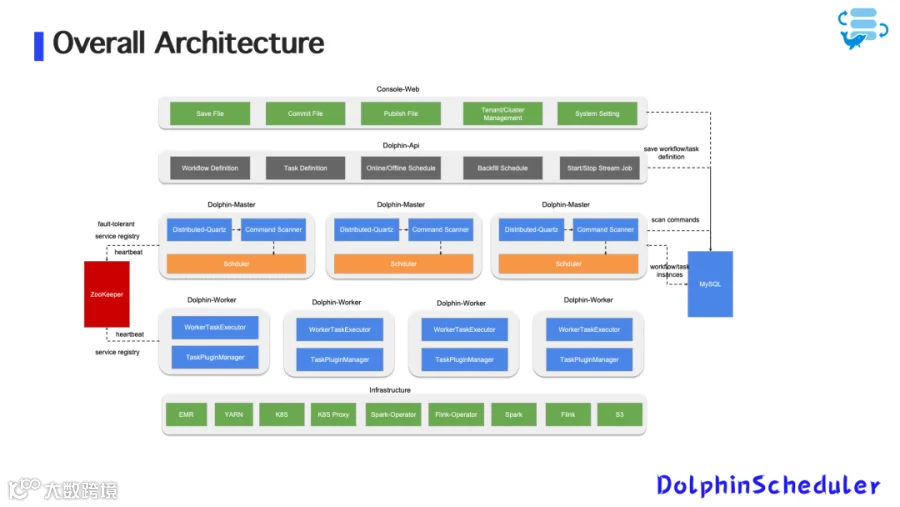
图1:早期整体架构
但随着业务需求的变化,大量实时计算需求涌现,例如:
-
Flink SQL 实时指标计算; -
Spark Structured Streaming 用于日志与事件数据处理; -
实时任务需要支持长时间运行、状态跟踪、异常恢复等能力。
这对 DolphinScheduler 提出了全新的挑战:如何让流任务像批任务一样“被调度”与“被管理”?
2
初始架构的限制与问题暴露
原始做法
在最初的流任务集成方案中,Zoom 使用 DolphinScheduler 的 Shell 任务插件,调用 AWS EMR API 启动流任务(如 Spark/Flink)。
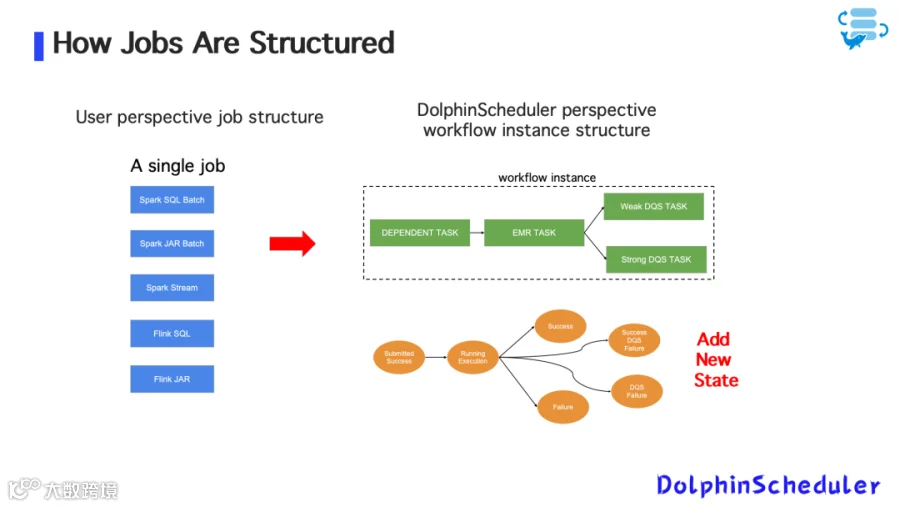
图2:早期任务结构
执行逻辑简单,但很快暴露出多个问题:
- 无状态控制:任务提交后即退出,不跟踪运行状态,导致重复提交或误判失败;
- 无任务实例与调度日志:运维排障困难,缺少日志与监控链路;
- 代码逻辑割裂:流任务与批任务使用不同逻辑,难以统一维护与演进。

图3:早期挑战
这些问题逐步暴露出构建“批流统一调度架构”的迫切需求。
3
系统演进:引入流任务状态机机制
3
系统演进:引入流任务状态机机制
为了实现流任务的有状态调度管理,Zoom 基于 DolphinScheduler 的任务状态机能力,设计了针对流任务的双阶段任务模型:

图4
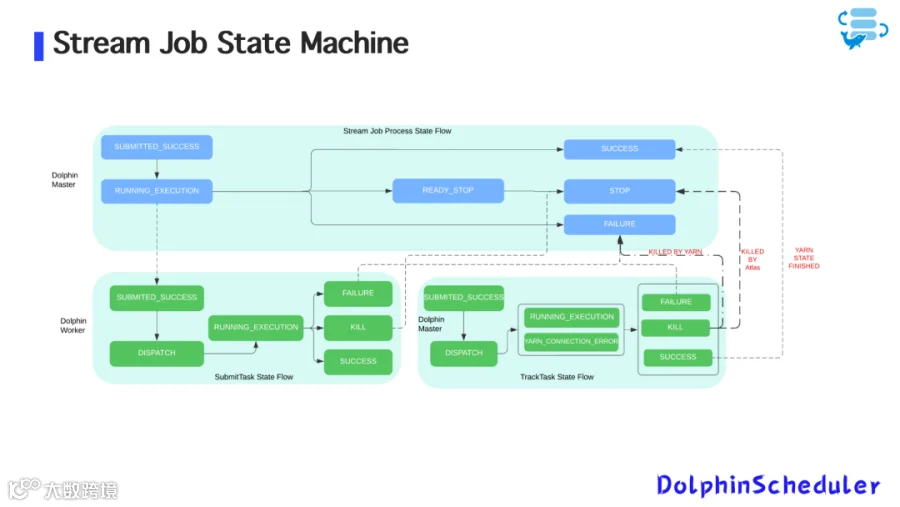
图5:状态机制设计
1. Submit Task - 提交阶段
-
在 Dolphin-Worker 上执行; -
主要作用是将 Flink/Spark Streaming 任务提交到 Yarn 或 Kubernetes; -
任务提交成功(即 YARN Application 进入 Running 状态)即视为成功; -
若提交失败,任务直接失败并结束调度。
2. Track Status Task - 状态追踪阶段
-
在 Dolphin-Master 上执行; -
周期性检查 Yarn 或 Kubernetes 上的流任务运行状态; -
模仿依赖任务实现方式,以“独立任务”存在于调度流中; -
实时更新任务状态到 Dolphin 的元数据中心。
这种双任务模型有效解决了以下关键问题:
-
避免重复提交; -
流任务纳入统一状态机与日志体系; -
架构与批处理任务保持一致,便于扩展与维护。
4
高可用机制:
应对 Master/Worker故障
在大规模生产环境下,调度系统的稳定性至关重要。Zoom 针对 DolphinScheduler 的 Master 和 Worker 故障场景做了充分考虑与处理。
1. Worker 故障恢复逻辑
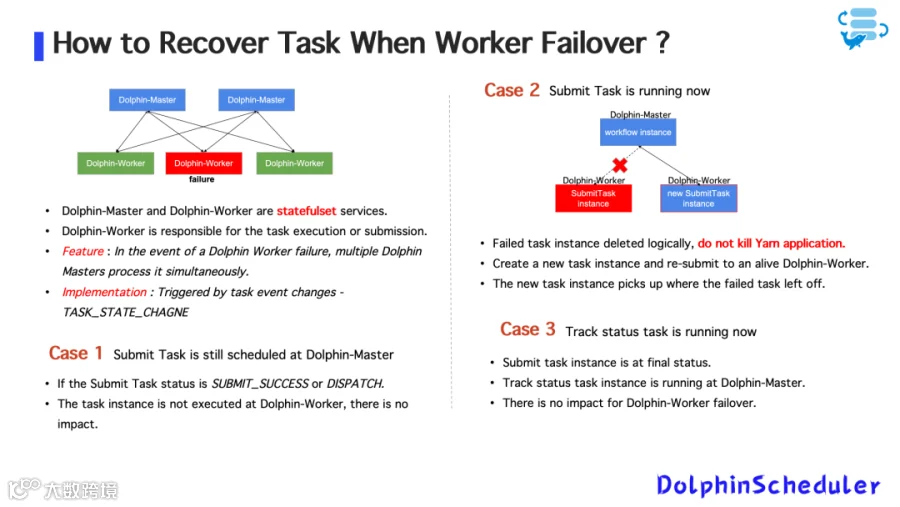
图6
若 Submit Task 正在运行,Worker 宕机:
-
原任务实例被逻辑删除; -
创建新的任务实例提交至存活 Worker; -
不强行 kill 已提交的 Yarn Application;
若 Track Status Task 正在运行:
-
无需重新调度; -
因任务本身在 Master 上执行,Worker 故障不影响任务状态追踪。
2. Master 故障恢复逻辑
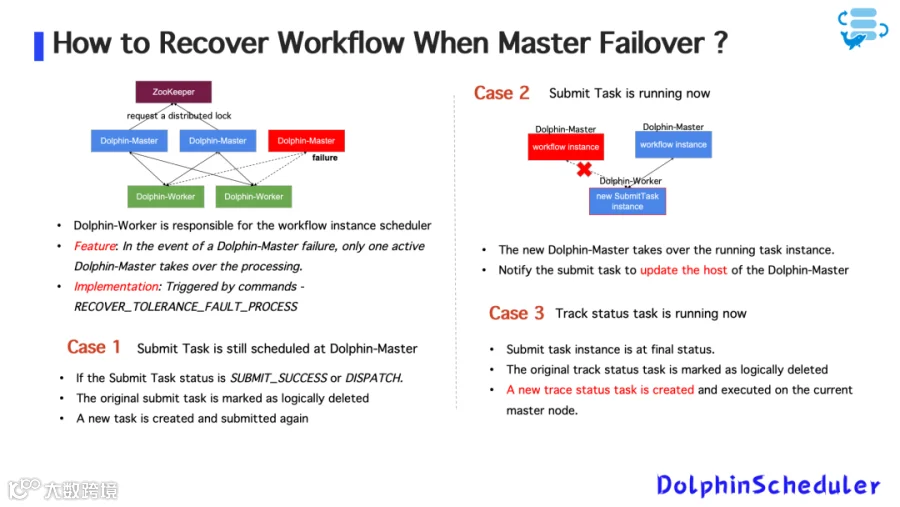
图7
使用 ZooKeeper + MySQL 的容错机制;
Dolphin-Master 多副本部署,使用分布式锁控制调度权;
Master 宕机时:
-
活跃节点切换; -
所有状态任务重新加载并恢复调度; -
防止重复执行任务的关键是任务状态的“幂等识别”与“逻辑删除”机制。
总结起来,这些处理实现了以下几点:
优势一:
-
更易于排查问题 -
流任务也具备了工作流与任务实例,纳入统一调度体系 -
支持日志检索,便于故障定位 -
优势二: -
充分利用了 DolphinScheduler 现有的工作流与任务状态机机制 -
成功避免了任务的重复提交问题 优势三:
-
架构实现了流任务与批处理任务的统一 -
提升了整体代码的可维护性和一致性
5
在Kubernetes上统一调度
Spark与Flink
Zoom 已逐步将批流任务迁移至 Kubernetes 上运行,使用 Spark Operator 与 Flink Operator 实现云原生任务调度:
架构组成
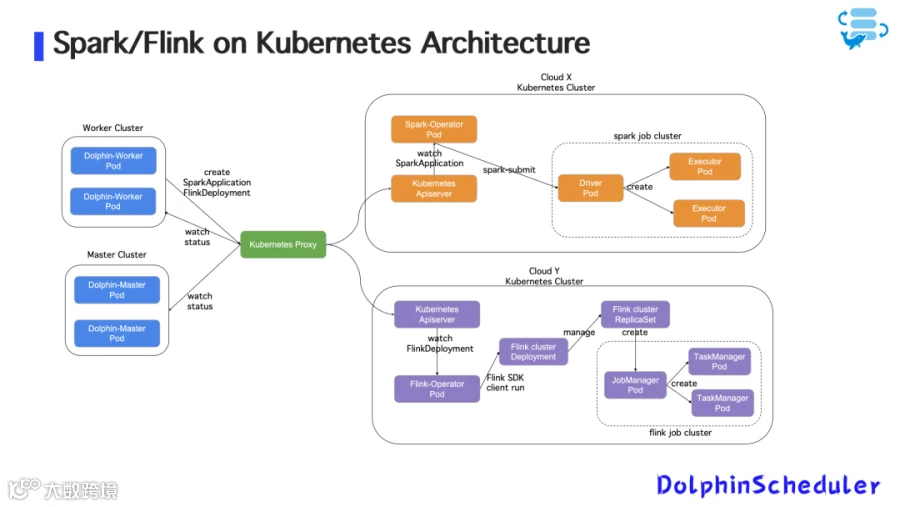
图8:k8S上Spark/Flink运行架构图
-
Spark/Flink Job 以 SparkApplication/FlinkDeploymentCRD 形式存在;
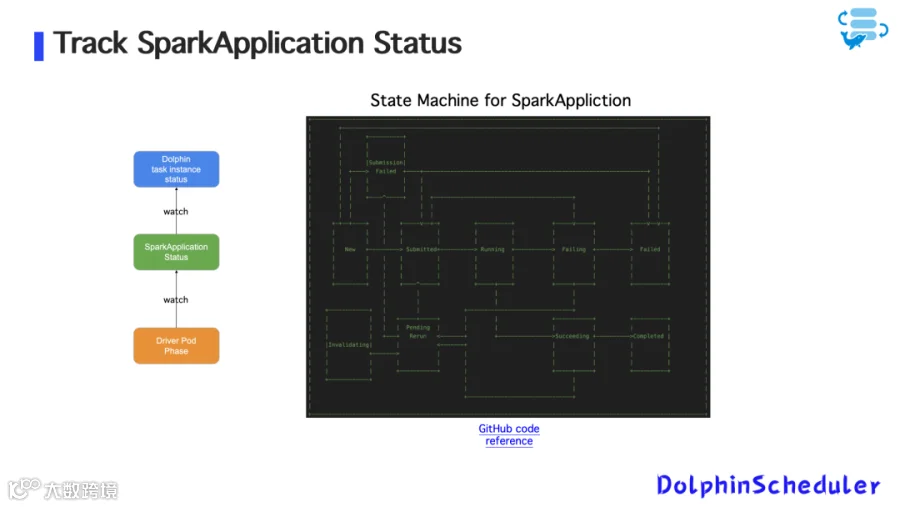
图9:追踪SparkApplication状态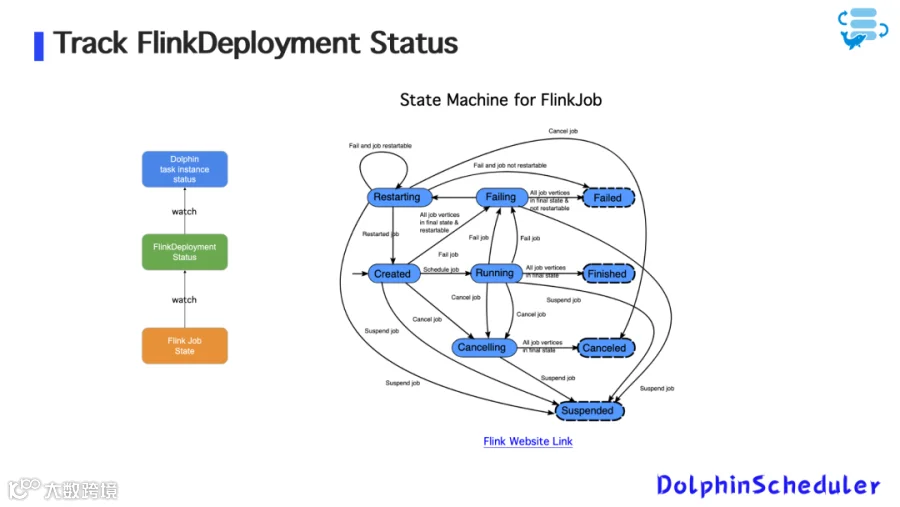
图10:追踪FlinkDeployment状态
-
DolphinScheduler 创建并管理这些 CR; -
任务状态通过 Operator 与 Kubernetes API Server 进行实时同步; -
Dolphin-Master & Worker Pod 通过状态机持续追踪 Pod 状态,映射为调度系统中的任务状态。
多云集群调度支持
-
支持同时调度多个云环境(如 Cloud X / Cloud Y)上的 Kubernetes 集群; -
跨集群部署调度逻辑与资源完全解耦; -
实现流批任务的“跨云运行、统一管理”。
6
线上问题与处理策略
6
线上问题与处理策略
问题一:Master 宕机导致任务重复执行
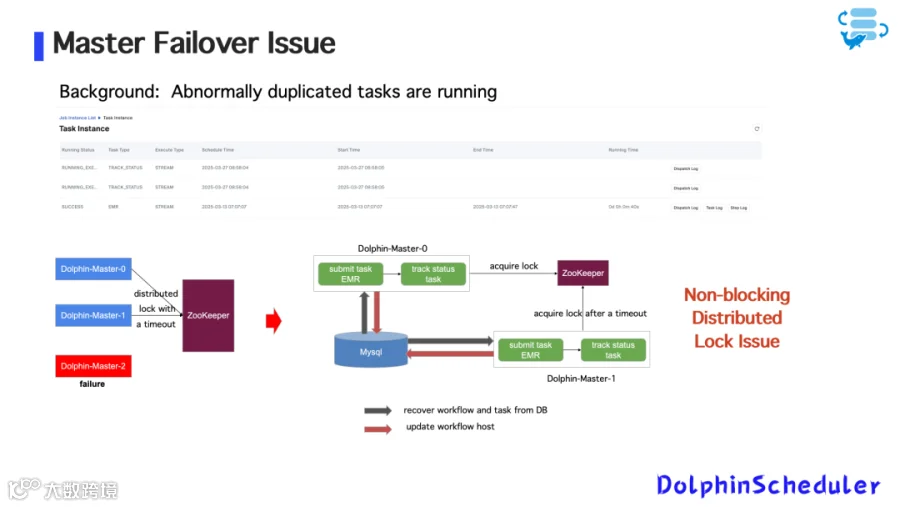
图11
由于 DolphinScheduler 分布式锁为非阻塞设计,存在竞争窗口;
解决方案:
-
增加锁获取超时机制; -
对 Submit Task 状态进行幂等控制(避免重复提交); -
从 MySQL 中恢复任务状态前先进行状态校验。
问题二:工作流卡在 READY_STOP 状态
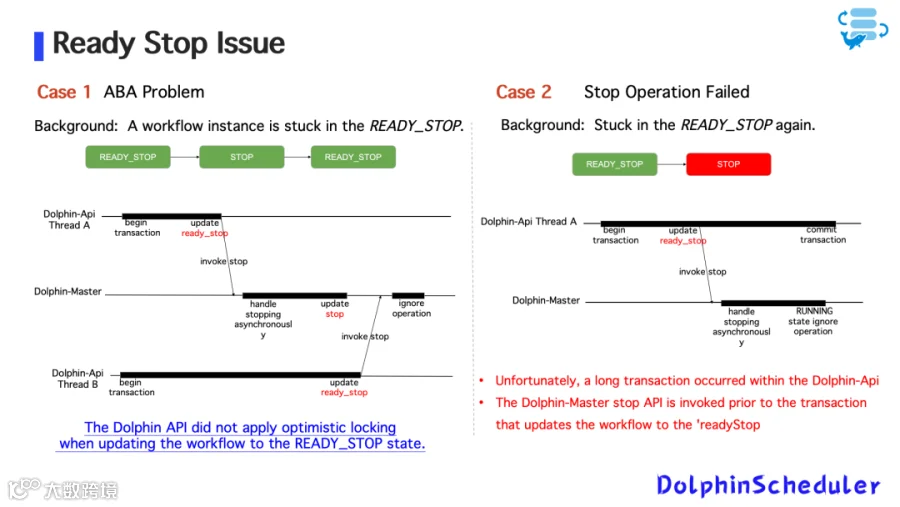
图12
原因:
-
Dolphin-API 调用停止工作流时未加乐观锁; -
多线程下状态修改存在竞争,导致无法进入 STOP 状态; 优化:
-
在 API 层引入乐观锁控制; -
拆解长事务逻辑; -
Master 处理任务状态变更时加多层校验。
7
未来规划
未来,Zoom 将基于 Apache DolphinScheduler 进行更多优化和改进,以适应越来越复杂的场景需求,这主要包括以下几个方面:
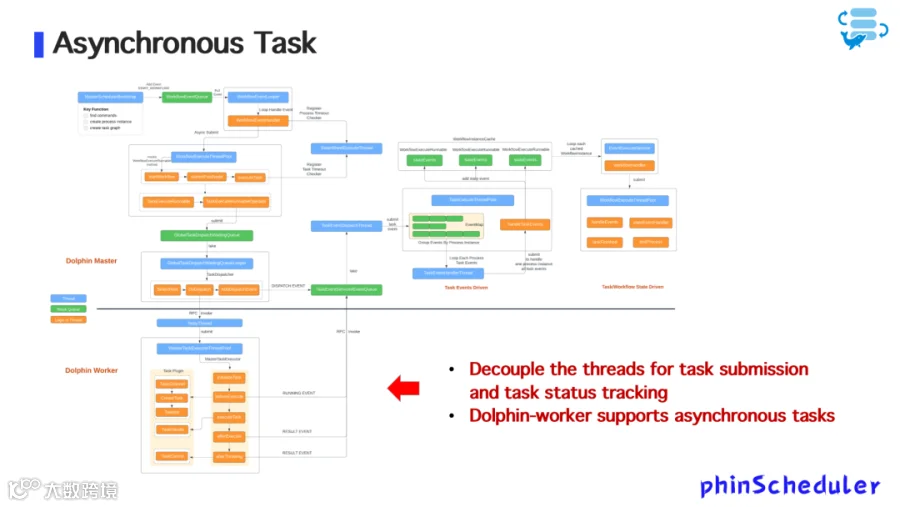
图13
1. 异步任务机制
-
提交任务与追踪状态逻辑完全解耦; -
Worker 支持异步执行,避免长时间阻塞资源; -
为未来支持更复杂的调度依赖、弹性调度等能力打下基础。
2. 批流统一调度平台升级
-
工作流模板支持混合任务类型; -
日志、状态、监控打通; -
云原生能力进一步加强,目标构建“支持大规模生产调度的分布式计算中枢”。
8
写在最后
Zoom 在 DolphinScheduler 上的深度实践验证了其作为企业级调度平台的可扩展性、稳定性与架构灵活性。尤其是在流批一体调度、Kubernetes 云原生部署、多集群容错等方面,Zoom 的方案为社区和其他企业用户提供了宝贵的参考。
📢 欢迎更多开发者加入 Apache DolphinScheduler 社区,将你们的宝贵经验分享出来,共同打造下一代开源调度引擎!
-
GitHub:https://github.com/apache/dolphinscheduler


用户案例

迁移实战

发版消息

加入社区
关注社区的方式有很多:
-
GitHub: https://github.com/apache/dolphinscheduler -
官网:https://dolphinscheduler.apache.org/en-us -
订阅开发者邮件:dev@dolphinscheduler@apache.org -
X.com:@DolphinSchedule -
YouTube:https://www.youtube.com/@apachedolphinscheduler -
Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
📂非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
👩💻代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。

你的好友秀秀子拍了拍你
并请你帮她点一下“分享”