

点亮⭐️
https://github.com/apache/dolphinscheduler
在生产环境中,调度平台的性能问题从来不是单点瓶颈,而是调度决策、任务执行、元数据存储、协调机制等多层因素叠加的结果。以 Apache DolphinScheduler 为例,如果你只盯着某一个组件(比如 Master 或 Worker),往往会误判问题根因。
这篇文章从真实生产实践出发,系统拆解调度平台的性能瓶颈,并给出可落地的优化策略。
一、从整体架构上,
瓶颈到底在哪一层?
DolphinScheduler 的核心链路可以抽象为:
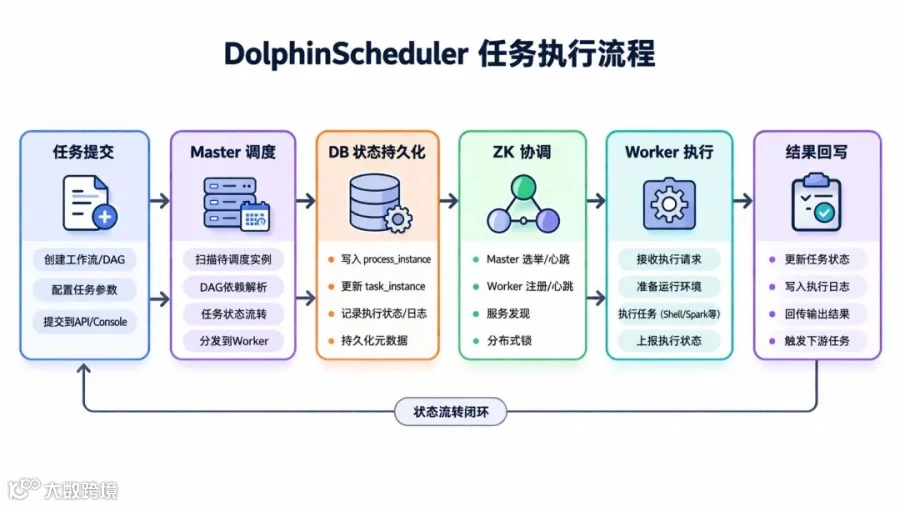
任何一个环节都可能成为瓶颈,但最常见的性能问题集中在四个点:
-
Master 调度吞吐不足 -
Worker 执行能力不匹配 -
数据库(MySQL/PostgreSQL)压力过大 -
ZooKeeper(协调层)延迟或抖动
二、Master调度的瓶颈
不是CPU,而是“调度模型”
二、Master调度的瓶颈
不是CPU,而是“调度模型”
很多人第一反应是:Master CPU 打满了。但实际生产中更常见的是:
👉 调度线程模型 + DB IO 才是核心瓶颈
1. 调度机制本质
Master 的核心逻辑是:
-
扫描待调度任务(DB) -
DAG 解析 -
任务状态流转 -
分发到 Worker
关键代码路径(简化):
// MasterSchedulerService.javawhile (true) {List<ProcessInstance> instances = processService.findNeedScheduleProcessInstances();for (ProcessInstance instance : instances) {submitProcessInstance(instance);}}
问题在于:
👉 这是一个“轮询 + DB驱动”的模型,这个模型的问题不在于它不能工作,而在于它把‘调度能力’绑定在了‘数据库吞吐能力’上。
2. 典型瓶颈表现
(1)调度延迟高
-
任务已 ready,但延迟几十秒才执行 -
Master CPU 不高,但 DB QPS 很高
(2)吞吐上不去
-
每分钟只能调度几百个 task -
扩容 Master 效果有限
3. 优化策略
✅ 减少 DB 扫描压力
核心 SQL(示意):
SELECT * FROM t_ds_process_instanceWHERE state = 'READY'LIMIT 100;
优化方式:
-
建立组合索引:
CREATE INDEX idx_state_priority_timeON t_ds_process_instance(state, priority, create_time);
-
控制扫描批次(避免 full scan) -
调整调度间隔(避免高频轮询)
✅ 提升调度并发
配置项(关键):
master:exec-threads: 100dispatch-task-number: 50
实践建议:
-
exec-threads ≈ CPU * 2 ~ 4 -
dispatch-task-number 不宜过大(避免 Worker 被压垮)
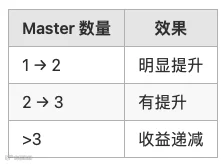
✅ 多 Master 扩展
DolphinScheduler 支持多 Master:
👉 但注意:不是线性扩展
原因:
-
DB 是共享瓶颈 -
ZK 需要协调 leader
实践经验:
三、Worker估算不是越多越好
很多团队在任务变慢时,第一反应就是加 Worker。但其实这是一个误区,因为盲目加 Worker 的结果很可能是:
❌ DB 被打爆
❌ 任务排队更严重
我们来看看这是为什么。
1. Worker 本质
Worker 本质上既负责真正执行任务的计算单元(执行容器),又作为资源分配与隔离的边界(资源隔离单位)。简单来说,就是任务在哪跑、占多少资源、彼此会不会互相影响,都是由 Worker 决定的。
Worker 关键参数:
worker:
exec-threads: 50
2. 如何估算 Worker 数量?
估算要用多少 Worker的 核心公式是(经验模型):
Worker数量 ≈ 总并发任务数 / 单Worker并发能力
进一步细化:
单Worker并发能力 ≈ CPU核心数 * 2 ~ 4
3. 示例
假设我们有:
-
1000 个并发任务 -
每个 Worker 16 核
则:
单 Worker ≈ 32 ~ 64 并发
需要 Worker ≈ 1000 / 50 = 20 台
4. 更关键的是任务类型
决定 Worker 数量更关键的是任务类型,因为短任务消耗的是调度能力,长任务占用的是执行资源,不同类型决定了系统瓶颈所在。
🔹 短任务(<5秒)
问题:
-
调度开销 > 执行时间 -
Master 成为瓶颈
策略:
-
合并任务(task batching) -
减少 DAG 节点数
🔹 长任务(>10分钟)
问题:
-
Worker 资源被长期占用
策略:
-
使用队列隔离(tenant + queue) -
控制并发
四、短任务和长任务的调度策略差异
四、短任务和长任务的调度策略差异
这是生产中最容易被忽略,但影响最大的点。
1. 短任务优化
典型场景:
-
SQL 查询 -
API 调用
优化策略:
✅ 合并任务
-- 原来:10个小SQL
SELECT * FROM table WHERE id = 1;
...
-- 优化:批量执行
SELECT * FROM table WHERE id IN (1,2,3,...);
✅ 减少调度层参与
-
使用脚本内部循环 -
避免 DAG 过细
2. 长任务优化
典型场景:
-
Spark / Flink 作业
关键点:
👉 调度系统不是瓶颈,资源系统才是
策略:
-
绑定 Yarn Queue / K8s Namespace -
限流
五、数据库瓶颈:
最容易被低估
五、数据库瓶颈:
最容易被低估
经过调研我们发现,在所有生产案例中,80% 的性能问题,最终都落在 DB 上。
1. 常见问题
-
慢 SQL(状态查询) -
行锁竞争(update 状态) -
连接数打满
2. 典型 SQL
UPDATE t_ds_task_instanceSET state = 'RUNNING'WHERE id = ?;
高并发更新同一批记录时,数据库需要对行加锁,导致事务相互等待,从而拖慢整体吞吐。
3. 优化策略
针对数据库瓶颈,需要从访问模式、写入频率和架构层面入手,系统性地进行优化与治理。
✅ 分库 / 读写分离
-
Master 写 -
API / 查询走从库
✅ 减少状态更新频率
错误方式:
RUNNING → RUNNING → RUNNING(频繁心跳)
优化:
👉 降低心跳频率
✅ 批量更新
// 批量提交状态
updateBatch(taskInstances);
六、ZooKeeper的隐形瓶颈
六、ZooKeeper的隐形瓶颈
ZooKeeper 在 DolphinScheduler 中承担的是分布式协调层的角色,主要负责 Master 选举、Worker 注册以及节点心跳维持,是整个调度系统稳定运行的基础组件。
一旦这一协调链路出现波动,往往不会直接报错,而是以调度抖动、节点异常等“隐性问题”的形式体现出来。
1. 常见问题表现
调度抖动
在高负载或网络不稳定时,任务调度会出现间歇性延迟,表现为任务触发时间不稳定,整体调度节奏被打乱。
Worker “假死”
Worker 实际仍在运行任务,但由于心跳未及时上报,被 Master 判定为失效节点,从而触发任务重试或转移。
Master 频繁切换
ZooKeeper 会触发 Leader 重新选举,导致 Master 节点频繁变更,进而影响调度连续性和系统稳定性。
2. 根因分析
ZooKeeper 出现这些问题的原因可能有以下几点:
session timeout 设置不合理
如果 session timeout 过短,轻微的网络抖动或 GC 停顿就可能导致节点被误判为失联,从而触发不必要的节点切换。
节点数量与连接压力过大
随着 Worker 和 Master 数量增加,ZooKeeper 需要维护大量临时节点和连接,容易成为性能瓶颈。
网络抖动或延迟
ZooKeeper 对网络稳定性非常敏感,一旦出现抖动或延迟升高,就可能影响心跳、选举和节点状态同步。
3. 优化
在明确了问题表现和根因之后,ZooKeeper 的优化重点不在“调参数本身”,而在于提升整体协调链路的稳定性和容错能力。换句话说,我们需要让系统对短暂抖动“不敏感”,而不是一有波动就触发连锁反应。
首先可以从基础参数入手,对 ZooKeeper 的时序控制进行合理调整,例如:
tickTime=2000
initLimit=10
syncLimit=5
在此基础上,更关键的是对 session 超时时间的把控。在生产环境中,应适当拉长 sessionTimeout(通常建议不低于 20 秒),以避免因瞬时网络抖动或 JVM Stop-The-World 导致节点被误判下线,从而引发不必要的 Master 切换或 Worker 失效。
同时,从架构层面来看,ZooKeeper 集群应尽量独立部署,避免与数据库、大数据组件或调度节点混部。这样可以减少资源争抢带来的不确定性,确保协调服务本身的稳定性,从根源上降低调度系统的抖动风险。
七、真实性能优化案例
前面从架构和原理层面分析了各类性能瓶颈及其优化思路,但这些结论只有落到实际生产环境中才真正有意义。下面结合一个典型的线上案例,来看这些问题是如何暴露出来的,以及优化策略是如何一步步落地并产生效果的。
背景
-
任务数:每日 20 万 -
DAG 数:3 万 -
Master:2 台 -
Worker:30 台
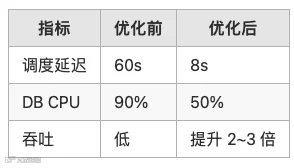
问题
-
高峰期调度延迟 > 1 分钟 -
DB CPU 90%
优化过程
1️⃣ DB 索引优化
→ 延迟下降 40%
2️⃣ 减少短任务
→ DAG 数减少 30%
3️⃣ 调整 Master 参数
exec-threads: 50 → 120
→ 吞吐提升 2 倍
最终效果
八、总结:调度平台
性能优化的本质
经过前面的拆解可以看到,无论是 Master、Worker,还是数据库和 ZooKeeper,看似分散的问题背后其实有一条共同主线。与其逐点优化、头痛医头,不如从整体视角重新审视调度系统的运行机制,才能真正理解性能瓶颈的本质所在。
总结起来,调度系统的性能问题,本质是:
“调度能力 × 执行能力 × 存储能力 × 协调能力” 的平衡问题
优化的关键不在于只盯某一个点做局部改进,而在于根据不同瓶颈特征进行有针对性的整体调优:
-
Master:控制调度节奏 -
Worker:匹配执行能力 -
DB:避免成为中心瓶颈 -
ZK:保证稳定协调
最后一句经验
调度系统的极限,不取决于你能调度多少任务,而取决于你的数据库能撑多久。
前文回顾:
第 1 篇 | 调度系统,不只是一个“定时器”
第 2 篇|Apache DolphinScheduler 的核心抽象模型
第 3 篇|调度是如何“跑起来”的?
第 4 篇|状态机:调度系统真正的灵魂
第 5 篇 | 任务失败怎么办?一文讲透 Apache DolphinScheduler 的重试与补数机制
第 6 篇 | 你不知道的DolphinScheduler企业级多租户资源隔离技巧下篇预告:
DolphinScheduler 与 Flink / Spark / SeaTunnel 的边界
END

用户案例

迁移实战

最新发版消息

加入社区
关注社区的方式有很多:
-
GitHub: https://github.com/apache/dolphinscheduler -
官网:https://dolphinscheduler.apache.org/en-us -
订阅开发者邮件:dev@dolphinscheduler@apache.org(向邮箱发送任意内容,收到邮件后回复同意订阅即可) -
X.com:@DolphinSchedule -
YouTube:https://www.youtube.com/@apachedolphinscheduler -
Slack:https://join.slack.com/t/asf-dolphinscheduler/shared_invite/zt-1cmrxsio1-nJHxRJa44jfkrNL_Nsy9Qg
同样地,参与Apache DolphinScheduler 有非常多的参与贡献的方式,主要分为代码方式和非代码方式两种。
📂非代码方式包括:
完善文档、翻译文档;翻译技术性、实践性文章;投稿实践性、原理性文章;成为布道师;社区管理、答疑;会议分享;测试反馈;用户反馈等。
👩💻代码方式包括:
查找Bug;编写修复代码;开发新功能;提交代码贡献;参与代码审查等。

你的好友小海豚拍了拍你
并请你帮她点一下“分享”