
点击关注

已关注公众号


2026年,具身智能赛道正经历一场从实验室炫技到产业落地的剧烈蜕变。当资本潮水褪去,真正能穿越周期的,从来不是会跑会跳的人形外壳,而是藏在躯壳之下、能理解物理世界、适配万千场景的通用具身大模型。
就在行业聚焦 “谁能率先破局泛化性难题” 时,RoboScience机器科学悄然完成10亿元A轮融资,投资方集结国内外产业巨头与一线财务机构,新一轮融资亦接近收官,互联网资本、国家队基金、顶级财务机构悉数入局。这笔重磅融资,没有投向花哨的整机演示,而是全部压注VLOA大模型技术深耕与自研机器人本体工程化量产,直指具身智能规模化落地的核心命门。

在2026年国内具身智能融资突破500亿元、单笔10亿元以上融资达18起的热潮中,RoboScience的10亿融资格外特殊 —— 它不是对 “机器人概念” 的盲目追捧,而是对“模型 + 本体 + 数据” 全栈技术闭环的确定性下注。当行业还在为 “一机一策” 的工业自动化路径内卷时,这家公司已经用VLOA大模型,走出了一条跨物体、跨任务、跨场景、跨机器人的通用具身智能新路径。
具身智能规模化的“最后一公里”为何难破?
过去五年,具身智能走过了从概念到原型的全过程。机器人能完成分拣、装配、导航等单一任务,在实验室里呈现出近乎完美的表现,但一旦进入真实世界,立刻陷入 “水土不服” 的窘境。
行业普遍面临三大死穴:
第一,场景适配能力极差。仓库里能用的机器人,换到零售货架就失灵;能抓规则箱体的手,碰到柔性包装袋就束手无策,传统 “定制化编程 + 专用模型” 的模式,根本扛不住动态复杂环境的考验。
第二,本体绑定严重。一家企业往往要为不同机械臂、不同灵巧手开发多套控制算法,模型无法跨硬件迁移,研发成本呈指数级上升,量产遥遥无期。
第三,数据与训练闭环缺失。互联网视频数据海量却难落地,物理仿真数据稀缺且质量参差不齐,机器人难以从海量真实交互中学习通用物理规律,只能依赖有限场景的反复调试。
赛迪研究院报告直言,2026年具身智能已彻底告别 “讲故事” 时代,进入商业化验证期。泛化性不足成为制约行业从 “单点演示” 走向 “规模化量产” 的最大枷锁 —— 传统接近工业自动化的 “一机一策”,只能应对固定场景、固定任务,无法适配物理世界的无限变化。
这正是RoboScience切入赛道的核心契机。团队没有跟风做整机集成,而是直击具身智能的本质:机器人与物理世界的交互能力,用一套全新的大模型架构,破解 “通用操作” 这一行业终极难题。
VLOA大模型凭什么成为通用具身智能的“最优解”?
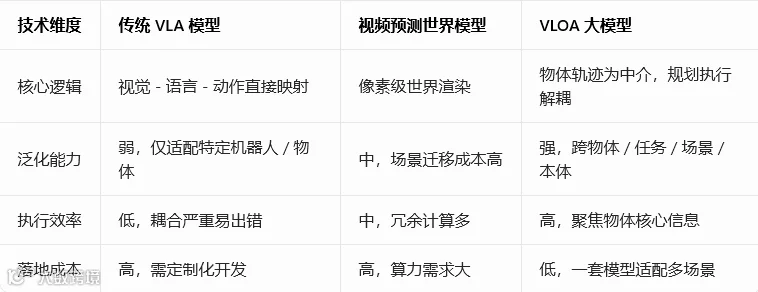
在具身智能大模型赛道,主流路线分为两派:一派是端到端VLA模型,直接将视觉、语言映射为动作;另一派是视频预测为中心的世界模型,试图渲染完整物理场景。而RoboScience的VLOA(Vision-Language-Object-Action)大模型,走出了第三条路 —— 以物体为中心、规划与执行解耦、世界模型与操作模型深度融合。
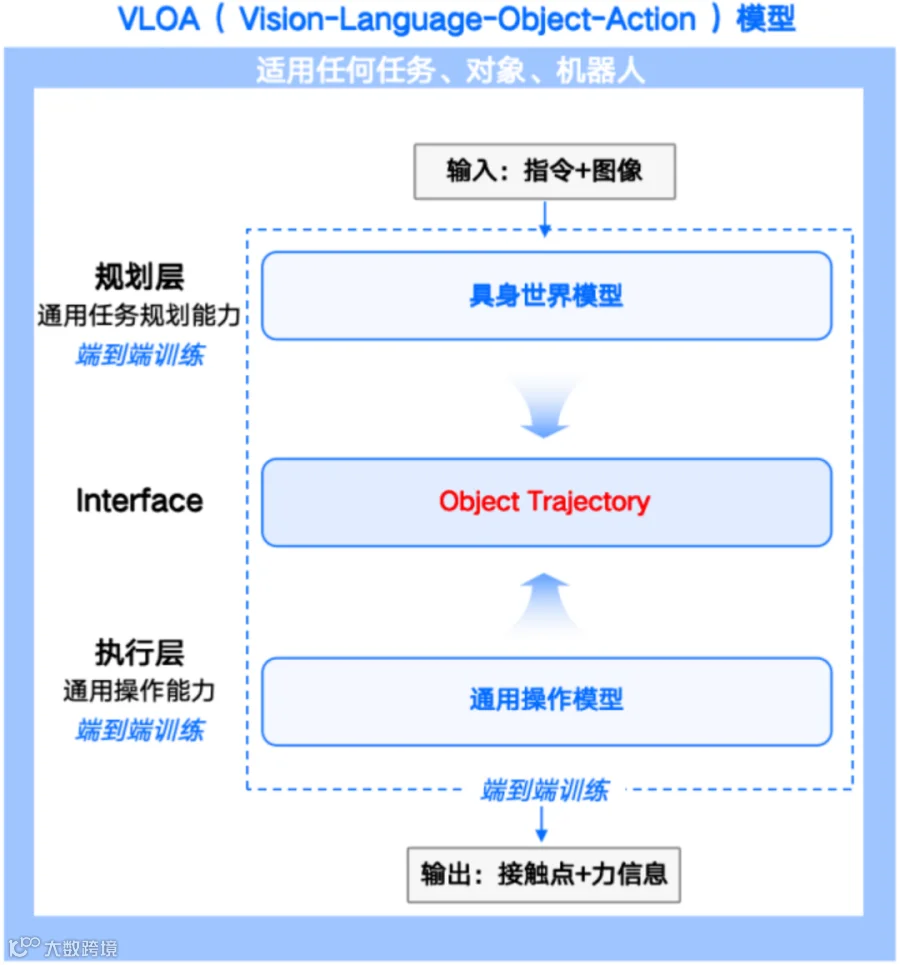
这套架构的核心创新,是把 “物体轨迹” 作为连接认知与执行的关键桥梁,彻底解决高层语义与底层控制脱节的行业痛点。
1. 中介接口革命:Object Trajectory如何打通认知与执行?
传统VLA模型直接把语言指令、视觉信号转化为机器人关节角度,看似简洁,却藏着巨大缺陷:高层任务规划与底层物理控制强耦合,换一个机器人、换一个物体,模型就必须重新训练,泛化性几乎为零。
VLOA大模型创新性引入Object Trajectory(物体轨迹)作为中介接口,用连续 3D 点云轨迹表征物体的运动状态,把复杂的机器人操作拆解为两层逻辑:
- · 上层:具身世界模型 —— 负责 “想清楚”。不渲染像素级画面,不构建宏大虚拟场景,只聚焦具身操作必需的物体状态、三维轨迹、接触关系、物理因果,提前预演物体在物理世界的运动规律,完成通用任务规划。
- · 下层:通用操作模型 —— 负责 “做到位”。接收世界模型输出的物体轨迹,转化为不同机器人的物理控制信号,适配各类机械臂、灵巧手与末端执行器,实现精准物理交互。
这种 “规划 - 执行” 解耦架构,相当于给机器人装上了“通用大脑 + 精准小脑”:大脑负责理解任务、推演物理规律,小脑负责适配硬件、执行精细操作,两者独立训练又深度协同,既保留了认知层面的泛化能力,又保证了执行层面的控制精度。
对比视频预测类世界模型,VLOA的优势直击本质:机器人不需要 “看懂” 整个世界,只需要 “掌控” 操作物体的物理变化。放弃冗余的像素渲染,聚焦物体级核心信息,让模型更轻量化、更适配真实执行,跨物体、跨任务、跨场景、跨本体的通用能力,成为与生俱来的基因。
2. 数据壁垒:千万小时视频 + 万亿次仿真,构筑行业护城河
大模型的竞争,本质是数据的竞争。具身智能模型想要通用,必须靠海量多模态数据 “喂饱”,而数据的规模、质量、闭环效率,直接决定模型上限。
RoboScience构建了“互联网视频 + 物理仿真” 双轮数据驱动体系,为VLOA大模型打造了行业稀缺的数据壁垒:
- · 具身世界模型数据底座:通过全自动标注与清洗pipeline,积累数百万小时以物体为中心的高维多模态操作数据,涵盖数千万视频片段,且以每周数十万小时的速度扩容,2026年目标打造千万小时级全球领先数据集。这些数据不是随机视频,而是聚焦 “物体交互” 的核心素材,让模型快速学习人类操作物体的通用逻辑。
- · 通用操作模型数据底座:依托自研多模态物理引擎,积累数百亿次高质量操作轨迹数据,2026年目标突破1万亿次全空间物体操作轨迹。仿真数据覆盖刚体、铰链体、1D/2D/3D可形变体等所有物体类型,让模型在虚拟世界中完成海量试错,掌握不同材质、不同形状物体的物理操控规律。
更关键的是,这套数据体系形成了高效闭环:互联网视频数据训练认知能力,仿真数据训练操作能力,两者通过Object Trajectory接口无缝衔接,让VLOA大模型同时具备 “理解世界” 和 “改造世界” 的能力,这是单一数据来源的模型无法比拟的。
3. 学术硬核实力:顶会最佳论文背书,刷新全球SOTA
RoboScience首席科学家邵林团队,已经用两项世界级成果,为 VLOA 通用操作模型奠定了不可撼动的技术基础。
2025年,团队研发的通用灵巧抓取框架 D (R,O) Grasp,荣获ICRA 2025 机器人操作与运动最佳论文奖 —— 这是近5年亚洲机构首次以第一单位斩获该奖项,含金量拉满。该框架创新性构建机器人与物体的交互统一表示,用同一个AI模型支持多种不同灵巧手的抓取操作,模拟环境抓取成功率87.53%,真实环境达89%,单次推理耗时不足1秒,彻底打破 “特定机器人适配特定物体” 的行业桎梏。
2026年,团队最新研究T(R,O)Grasp入围ICRA 2026,参数量超10亿的操作大模型,实现5 FPS实时动态交互,跨智能体平均抓取成功率高达94.83%,直接刷新全球跨智能体灵巧抓取SOTA(最先进水平)。
从D (R,O) Grasp到T (R,O) Grasp,两项成果层层递进,完美验证了VLOA大模型 “跨本体通用、精细操作稳定” 的核心能力 —— 这不是实验室里的纸面数据,而是能直接落地到工业、物流、零售场景的硬核技术。
VLOA能否定义下一代具身智能标准?
2026年,具身智能市场规模将突破1万亿元,资本、技术、场景三重共振,行业迎来历史性拐点。但繁荣之下,分化正在加剧:缺乏核心技术、依赖集成组装的企业将快速出局,掌握通用大模型、核心数据、自研本体三大壁垒的企业,将主导行业未来。
RoboScience的VLOA大模型,正在重新定义具身智能的技术标准:
-
· 不再追求 “人形外壳”,而是聚焦物理交互本质; -
· 不再依赖 “定制化编程”,而是打造通用模型架构; -
· 不再局限 “单一场景”,而是实现跨域全域适配。 -
对比行业主流路线,VLOA的差异化优势一目了然:
在零售场景,VLOA大模型能让机器人自主完成货架理货、商品抓取、库存盘点,适配不同尺寸、材质的商品;在物流场景,能快速适配分拣、码垛、装卸等全流程,兼容不同类型的机械臂与包裹;在工业场景,能应对柔性生产、非标装配等复杂任务,大幅降低产线改造周期。
更重要的是,VLOA大模型的拓展性几乎无限:随着数据持续积累、模型不断迭代,它能适配家庭、医疗、特种作业等更多场景,真正成为 “适用于任何任务、任何对象、任何机器人” 的通用具身智能系统。
具身智能的终局,是 “通用大脑” 的胜利
当机器人不再是只能执行固定指令的自动化设备,而是能理解物理世界、自主完成复杂任务的智能体,具身智能才真正实现了它的价值。而这一切的核心,是能突破泛化性困局的通用大模型。
RoboScience拿到的10亿融资,不仅是一笔资本注入,更是行业对 “通用具身智能” 路线的集体认可。在无数企业纠结 “做硬件还是做算法” 时,这家公司已经用VLOA 大模型 + 自研本体的全栈布局,抢占了行业制高点。

2026年,是具身智能商业化验证的元年,也是通用大模型决胜的元年。当资本回归理性、产业聚焦落地,那些真正掌握核心技术、打通商业闭环的企业,将成为穿越周期的领跑者。
VLOA大模型已经证明,具身智能的终局,从来不是 “比谁更像人”,而是谁能更高效、更通用、更稳定地与物理世界交互。RoboScience用10亿融资、顶尖学术成果、全栈技术闭环,给出了自己的答案 —— 通用具身大模型,才是机器人产业的终极未来。
未来已来,物理世界的智能化变革,正由VLOA这样的通用大脑,悄然开启。
往期推荐

融资10亿!上海国资重仓AMD前员工

吴夏青是谁?为什么离职英伟达创业?
点赞鼓励一下


图片来源:网络
本文不作为投资建议