

Hot Chips 是芯片领域最受关注,也最受重视的行业会议。各家芯片公司习惯于在这个会议上展示自己产品上最新的进展,因此它既是一个芯片技术发展的“剧透”大会,也是一个观察今天最重要芯片公司都在把研究重点投放到哪些方向的绝佳机会。
2024 年的 Hot Chips 刚刚在斯坦福大学落幕,英伟达等大厂展示了其产品细节,在大模型刺激下诞生的新公司们也借机秀了肌肉。我们邀请了参加了会议的资深硅谷芯片研发工程师,和我们分享了他的十点观察。
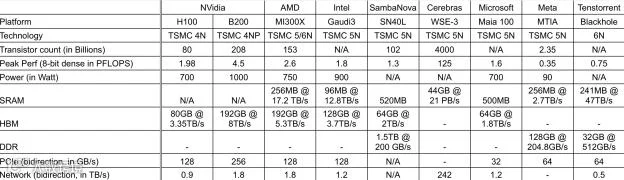
展示的 AI 加速器的芯⽚硬件能⼒总结在表格中。需要注意的是 ,一些能⼒已经进行了标准化处理 ,以便更公平地进行⽐较。例如 ,峰值性能显⽰了 8 位密集计算能⼒, PCIe/⽹络带宽为聚合的双向带宽。
由于⽣成式 AI 应用程序受到内存限制问题的影响 ,内存分层以及缓存和内存的大小至关重要。所有⼚商都尝试选择不同的优化点。
· 最直接的方法是增加最先进的 HBM 的容量。英伟达 (NVidia)、AMD、英特尔(Intel)、微软 (Microsoft)以及SambaNova 都采⽤了这种⽅法。NVidia 的 B200 和 AMD 的 MI300x 都通过在单⼀封装中提供令⼈惊叹的 192GB HBM。 · AMD 还引⼊了⼀个额外的内存层——256MB 的 Infinity Cache ,以进⼀步提升性能。 · SambaNova 拥有三层内存分层架构。尽管在 HBM 上有所⽋缺 ,但 520MB 的 SRAM 和 1.5TB 的 DDR 可能提供有趣的优化点。 · Meta 和Tenstorrent 基于SRAM和DRAM。⽽ Cerebras完全基于SRAM。
来自不同厂商的加速器架构相⽐之下更多相似点⽽⾮不同点。⼤多数架构包含专门处 理单元的阵列 ,并通过片上网络 (NoC) 进⾏扩展。很多架构引入不同粒度的Dataflow用于加速。
SambaNova 和 Cerebras 都明确强调了它们能够提供⾼性能推理 ,尽管他们的平台 ⼀开始是瞄准训练市场进行的设计。对于 Llama 3.1 70B ,Cerebras 可以以 450tokens/s 的速度运⾏,⽽ SambaNova 可以达到 380 tokens/s。不过,SambaNova 可以以 114 tokens/s 的速度运⾏ Llama 3 405B ,而 Cerebras 还在研发中。
英伟达 (NVidia) vs AMD :英伟达仍然是唯⼀⼀家提供涵盖 CPU、GPU、NVswitch、 DPU、 NIC、以太⽹和 IB 交换机的全栈平台的公司 ,并且具备强⼤的软 件⽀持和丰富的⽣态系统。然而,AMD 的 Instinct MI300X 在硬件能力上非常令人印象深刻。ROCm 和系统级扩展将是 AMD 追赶英伟达的关键。
特斯拉 (Tesla) 推出了 DumpNIC ,这是⼀种基于专有协议 TTPoE (Tesla Transport Protocol over Ethernet) 的 RDMA 卡 ,运⾏在纯 L2 层 ,完全由硬件驱动。假设网络存在丢包现象 ,DumpNIC 使⽤选择性重传来提供传输保证。
⼀家名为 Enfabrica的初创公司也宣布了他们的新型 SuperNIC ,它本质上是⼀种高阶路由器 ,集成了纵向扩展和横向扩展网络。每个纵向扩展端口是 PCIe ,每个横向 扩展端⼝是 RDMA, 通过内置的Switch进行All-to-all链接。通过合并endpoint和switch来提⾼密度 ,缩⼩footprint. idea⾮常独特 ,但很期待看到更多细节。
AMD、英特尔 (Intel)、⾼通 (Qualcomm)、 IBM 也展⽰了他们最新的CPU/SoC/FPGA。 除了扩展频率、寄存器、缓存和 I/O 之外 ,许多 CPU 还开始增加小型 AI 加速器 ,并⽀持特殊指令来采⽤数据流 ,以提⾼性能并降低功耗。
· IBM:Spyre CPU · AMD:Strix Point SoC and Granite Ridge SoC are based on Zen5 core.Versal AIEdge Series Gen2 SoC for automotive andvisionmarket. · Intel :Lunar Lake SoC · Qualcomm: Oryon CPU 英伟达 (Nvidia) 和新思科技 (Synopsys) 也展示了他们在芯片设计和制造过程中使⽤ AI 的⼀些最新进展。主要的使用案例包括 :
· 分析 利用卷积神经⽹络 (CNN) 的模式识别能⼒ ,在物理设计过程中进⾏ IR drop 估 计 ,以加快分析速度。 利⽤图神经⽹络 (GNN) 的图探索能⼒ ,根据电路图预测布局寄⽣参数。 · 优化 使⽤强化学习 (RL) 进⾏设计空间探索。 提⾼设计验证 (DV) 覆盖率。 电路和布局优化。 使⽤贝叶斯优化进⾏宏单元布局。 加快时序收敛。 修复设计规则检查 (DRC) 违规。 ⽣成优化的门尺⼨以提⾼性能、功耗和⾯积 (PPA)。 自动⽣成硅⽚测试模式 (ATPG) 以检测硅片缺陷。 · 辅助 工程知识库聊天机器⼈。 Bug 报告分析和 RTL 代码调试。 时序报告分析。 OpenAI 在主题演讲中再次强调了 AI 模型遵循可预测的扩展规律。假设模型架构足够优秀 ,数据量及其训练方式将决定模型的能⼒ 。因此 ,模型将会不断增⻓。
OpenAI 还强调 ,行业需要提供更强大且可靠的平台 ,以⽀持⼤规模 AI 基础设施的建设。(文章仅代表个人观点 不代表公司立场)
