


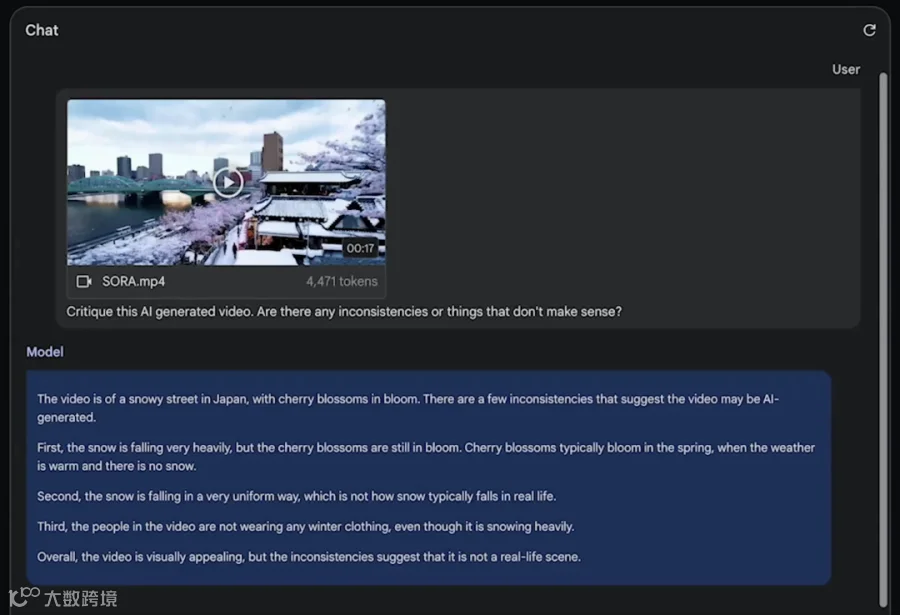
 图片来源 https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
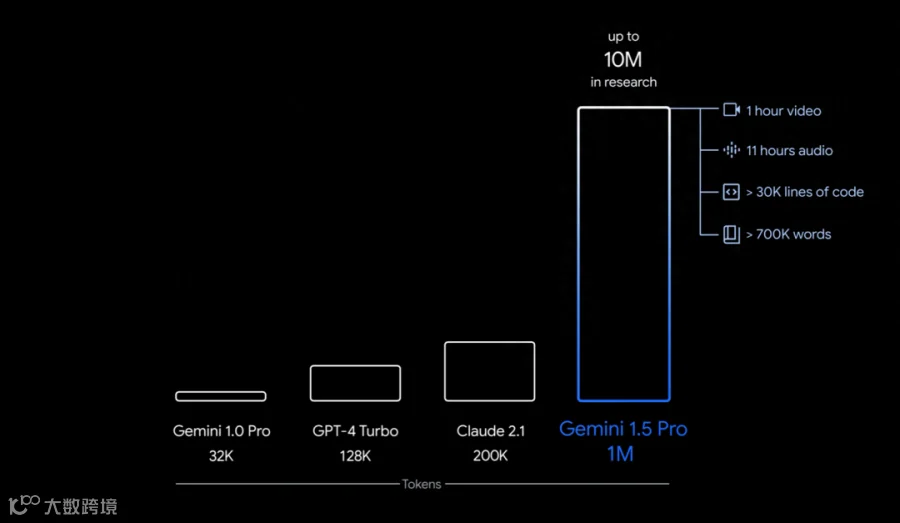
图片来源 https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf

根据目前的测试反馈,Gemini在回答36万个上下文时需要约30秒,并且查询时间随着token数量呈非线性上升。尽管我们对算力和模型的发展都持乐观态度,但要使长上下文实现秒级响应对于基于transformer的大型模型仍然是一个极具挑战性的目标。

尽管长下文的大模型生成结果具有很高的质量,但是推理成本依然是落地的阻碍。例如,如果将上下文的窗口设定为1M,按照当前0.0015美元/1000 token的收费标准,一次请求就要花掉1.5美元。这样高昂的成本显然是无法实现日常使用的。
1000万token相对于当前庞大的非结构化数据体量而言,依然是九牛一毛。目前还没有方式把整个Google搜索的索引数据扔进大模型。
实际的落地场景中,不仅仅包含了长文本,图片等非结构化数据,更包含了复杂的结构化数据,比如时间序列数据,图数据,代码的变更历史等等,处理这些数据依然需要足够高效的数据结构和检索算法。
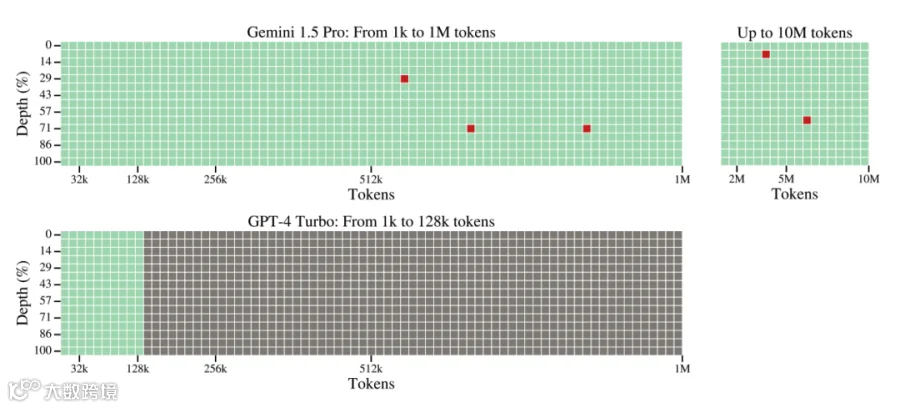
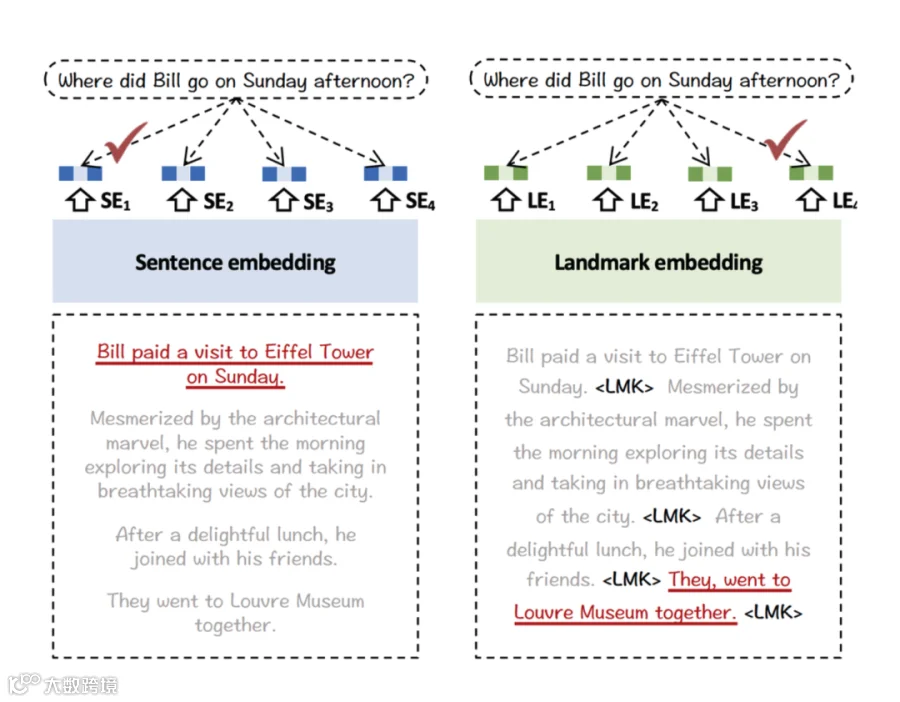 图片来源 https://arxiv.org/abs/2402.11573
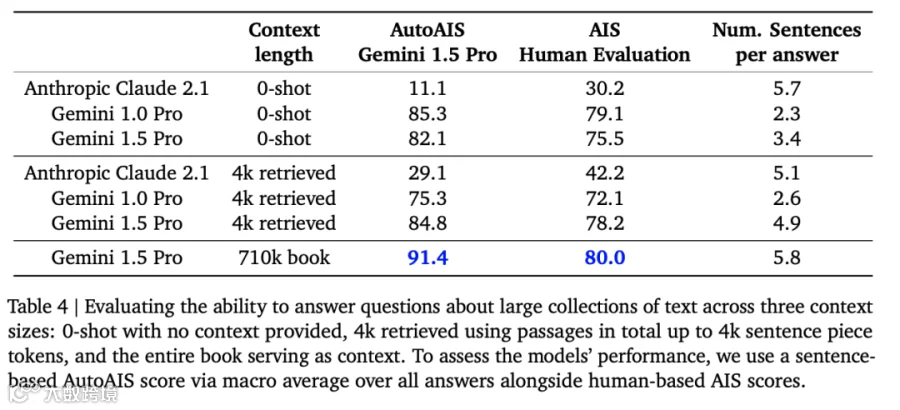
图片来源 https://arxiv.org/abs/2402.11573

🔗 欢迎扫海报底部二维码报名,现金大奖等你来拿!
