
点击上方卡片,关注「CloudPilot AI」
回复关键词【案例】
查看多邻国、Sonos等名企的云端降本实践

Tinybird 是一家专注于实时数据分析的开发者平台,服务对象包括 Vercel、Canvas 等知名科技公司。
本文来自其基础设施团队,详解他们在 EKS 上的架构优化实践,如何通过调度层调整实现显著的成本下降与性能提升。

01/
引言
在 Tinybird,我们始终致力于构建一个可扩展、可靠的平台,目的是让用户能够专注于开发和交付功能。
借助 EKS、Karpenter 和 Spot 实例,我们不仅成功让用户的弹性伸缩体验变得更加顺畅自然,还整体将 AWS 成本降低了 20%,其中 CI/CD 工作负载节省高达 90%。
此外,我们还摆脱了手动扩缩容和更新集群的繁琐流程:过去需要几天才能完成的操作,现在已经实现自动化处理,大幅提高运维效率。
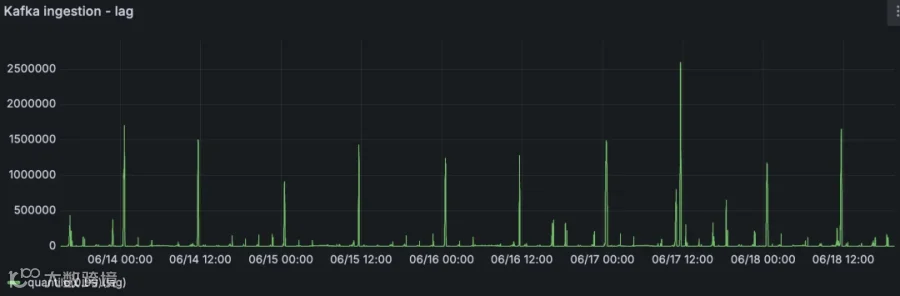
Kafka 消费者的弹性伸缩
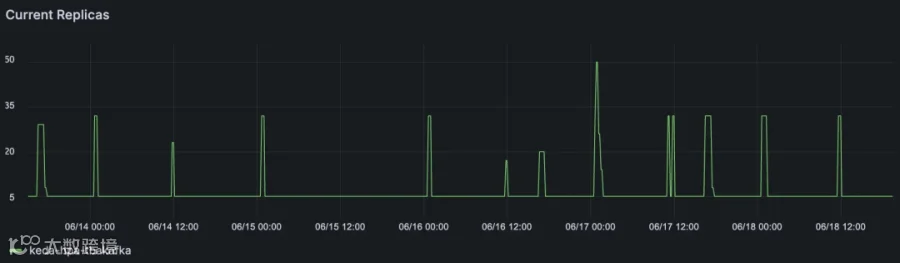
数据激增导致消费者 Lag 增加
本文将深入介绍 Tinybird 的架构设计、实践经验以及可借鉴的优化技巧,分享借助 Karpenter、Spot 实例和实时弹性伸缩成功大幅削减 AWS 成本的第一手实战经验。

02/
什么是 Karpenter?
Karpenter 作为一款开源的 Kubernetes 集群自动扩缩工具,专为优化性能和成本而设计,旨在以灵活、高性能和简洁的方式实现节点的弹性扩展,能够根据工作负载需求自动配置和管理计算资源。
Karpenter 不仅能够快速按需启动合适节点,从而提升应用可用性并降低基础设施成本,还会智能合并工作负载、用更高效的实例替代昂贵节点,并通过简洁的声明式配置(Declarative Configuration)减少运维成本。
Cluster Autoscaler 的痛点
Kubernetes 自带的 Cluster Autoscaler 在处理大规模集群时很快就会变成一场噩梦。
随着基础设施的增长,你不得不对每个区域(Region)、可用区(AZ)和实例类型的节点组进行精细化管理,本应“自动”的伸缩反而变成了手动且容易出错的操作。
举个例子,如果你想使用三种不同的实例类型,就得为每种类型创建一个单独的 NodeGroup。
如果你的工作负载使用了 EBS 卷(与特定的可用区绑定),你又得为每个可用区复制一套 NodeGroup。这样一来,3 种实例类型 × 2 个可用区,意味着有六个 NodeGroup 和六个 Auto Scaling Group 需要管理。
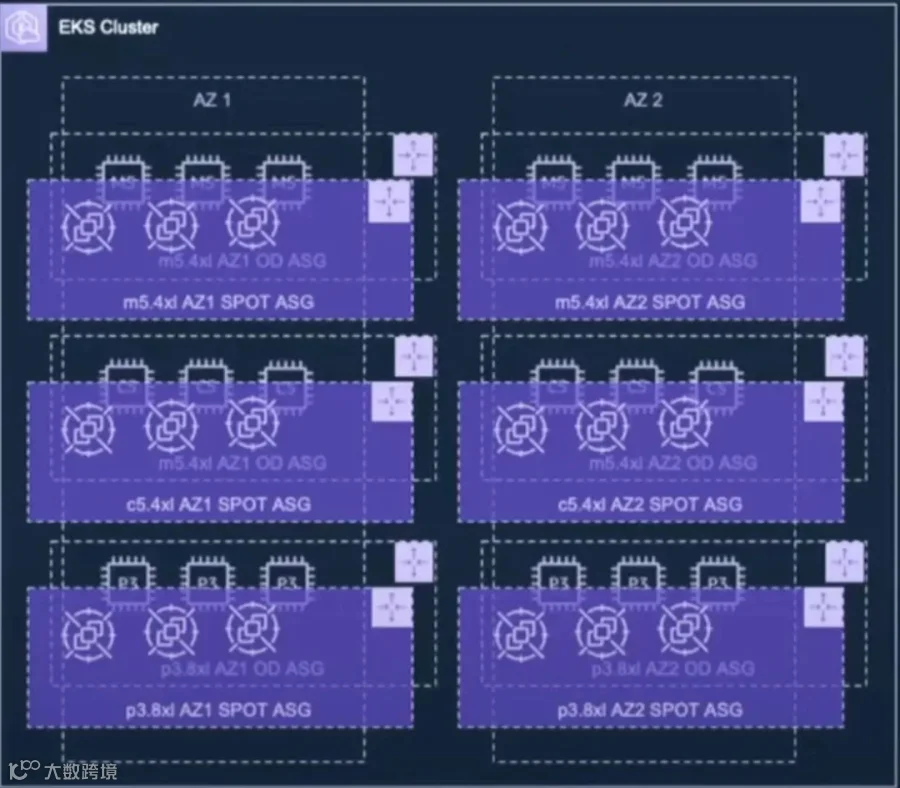
我们实际情况更复杂:
五六种实例类型、三个可用区、按需实例与 Spot 实例混用、工作负载同时跑在 x86 和 Graviton 处理器上、五个 AWS 区域部署,导致我们最终需要维护和更新上百个 NodeGroup。
这种手动管理不仅耗时、繁琐,而且根本没有扩展性。
Karpenter:告别节点管理
Karpenter 采用了一种与 Cluster Autoscaler 完全不同的方式。
Karpenter 不需要你为每一种可能的工作负载场景预先定义 NodeGroup,而是作为一个智能代理,根据简单、高层级的规则按需配置节点。
你只需要设定几条策略,例如:
允许使用 c、m、r 系列的任意实例类型
避免使用旧一代 CPU
优先选择 Spot 实例
然后你就可以无需再操心底层基础设施配置,而是专注于定义服务的资源需求——比如内存和 CPU 请求、首选的架构(ARM 还是 x86)、服务是否无状态以及是否可以运行在 Spot 实例上。
Karpenter 会在合适的时机迅速配置合适的基础设施,始终选择性价比最高的方案。
这就好比有一位 7×24 小时在线的平台工程师,持续为你的集群做最优配置,让你的团队可以专心开发和交付功能,而不是浪费时间在节点管理上。

03/
我们的 EKS 架构与优化实践
Karpenter 最大的优势之一是它支持统一管理节点池,这极大地简化了集群运维和节点管理的复杂度。
不过在实践中,为了清晰区分和成本优化,我们会从逻辑上将 NodePool 分为两类:
关键/有状态 NodePool
这类 NodePool 专门用于不能运行在 Spot 实例上的关键/有状态服务,全部使用按需实例。
虽然它也具备弹性伸缩能力,但整体容量相对稳定,几乎全部资源消耗都通过 AWS Savings Plan 覆盖。
在我们的配置中,关键/有状态 NodePool 会设置一个污点(taint),确保只有关键工作负载才能调度到这些节点上。包括如下类型的服务:
数据库等有状态服务;
无法中断的后台任务处理器;
所有必须始终高可用、且对中断极为敏感的 Kubernetes 核心控制器与组件,如 CoreDNS、Prometheus、EBS-CSI 和 ALB-controller 等。
这样的设计保障了系统的稳定性与关键服务的持续可用性。
无状态/Spot NodePool
这类节点池则专门用于运行所有无状态服务。它完全依托 Spot 实例运行,如果极少数情况下 Spot 容量不可用,会自动回退使用按需实例(不过截至目前,我们还从未遇到过回退的情况)。
这种设计能够让我们在不影响业务稳定性的前提下,最大化节省那些可容忍中断的工作负载的运行成本。
对于易扩展、可重启的服务来说,这是一种高效又划算的运行方式。
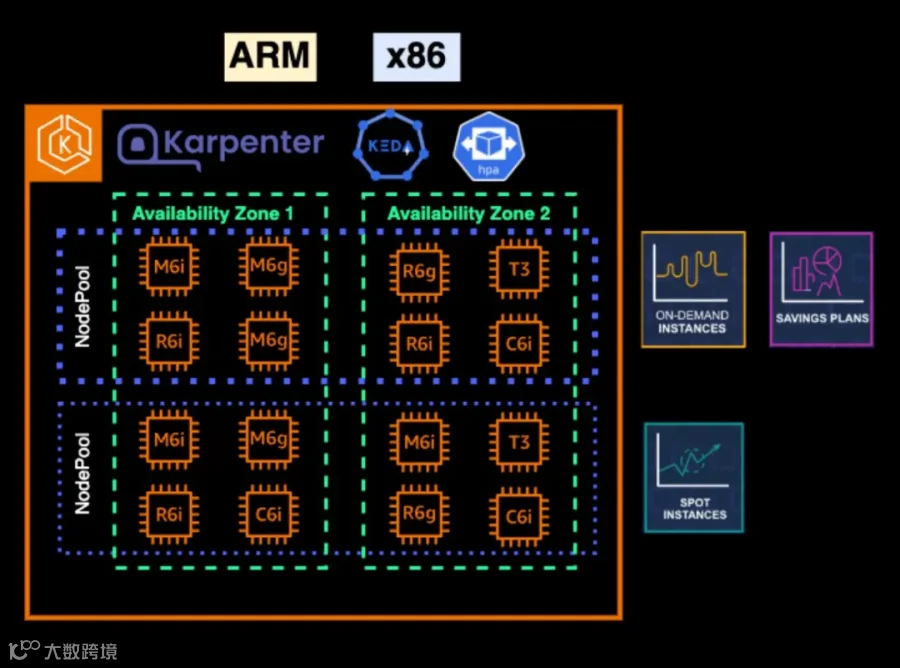
两种节点池都支持 x86 与 ARM 架构,为实例选择提高了更多灵活性,进一步优化了整体成本结构。
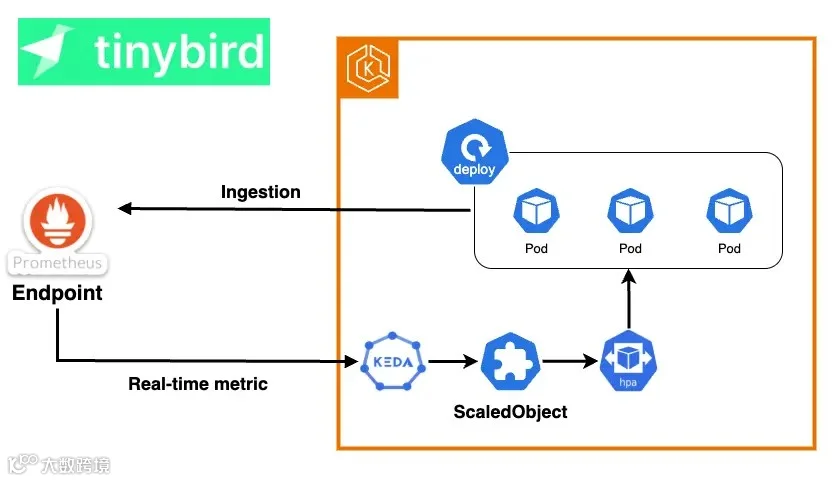
在 Pod 的水平自动伸缩方面,我们借助 KEDA(Kubernetes Event-driven Autoscaling)实现,它扩展了 Kubernetes HPA 的能力,允许基于外部指标和事件进行扩缩。
KEDA 支持超过 70 种类型的 Scaler,可以根据多种来源的指标触发弹性伸缩,比如 CloudWatch、SQS 队列中的消息数量,甚至是 DynamoDB 表中的记录数。
在 Tinybird,我们使用自身平台提供驱动自动扩缩容的指标。
只需一个简单的查询,就能创建一个 Prometheus 格式的 HTTPS 端点,随后 KEDA 会直接读取它来动态调整每个部署的副本数量。
虽然我们的监控与告警系统基于 Prometheus 和 Grafana 构建,但在自动扩缩容场景中,我们更倾向于直接从 Tinybird 读取数据。
这是因为 Prometheus 和 Grafana 的监控数据并不够“实时”,而 KEDA + HPA 获取的指标数据越及时,就能越快响应流量高峰,工作负载的弹性伸缩也就越精准。

04/
节点合并
节点合并是 Karpenter 为了降低集群成本而做出的优化决策。
即便 Pod 的数量保持不变,Karpenter 也能检测出资源利用率较低的节点,并决定将这些节点移除,同时将其上的 Pod 重新调度到其他节点上。这个过程有助于保持基础设施的精简与高效。
举个例子,下图展示了我们某个集群在 48 小时内的 Karpenter 活动情况,其中包括节点的创建、终止和合并操作——即使这期间工作负载并没有发生明显波动。
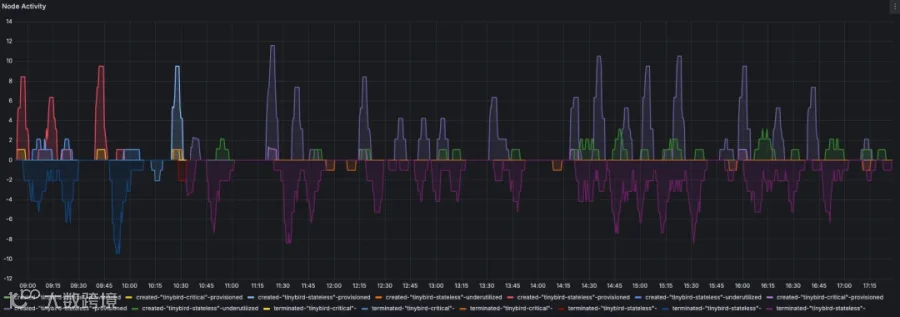
然而,每一次节点合并都会涉及 Pod 的迁移,因此提前为工作负载做好准备至关重要,否则很容易出现内部服务器错误或短暂的服务中断。
以下是我们认为非常关键的一些最佳实践:
优雅关闭:
确保你的 Pod 配置了合理的优雅终止时间(terminationGracePeriodSeconds),让它们在被终止前有足够时间完成清理工作,避免因突然中断而导致服务异常。
Pod 中断预算:
为你的部署设置 PDB,确保在自动驱逐或升级过程中,不会一次性终止所有副本,从而保障服务始终保持可用。
拓扑分布约束:
将副本均匀分布到不同的可用区或节点上,增强系统的容错能力,提高整体的可靠性。
只要你的部署配置好了优雅关闭、PDB 策略和拓扑分布约束,你就可以放心地让 Karpenter 在发现优化机会时自动合并节点,无需人工干预就能实现资源和成本的最优平衡。
下面是我们亲测效果非常好的三项 Karpenter 配置策略:
1. 不要局限于少数几种实例类型
很多人初用 Karpenter 会下意识认为“只用 r7/m7 这些新实例最好”,但实际上,这是一个误区,这样做会严重限制 Karpenter 的优化空间,导致它在成本和可用性上都很难发挥出最大优势。
Karpenter 的强大就在于它能从更多类型中择优选择。
你给它的选择越多,它就越有可能帮你选出既便宜又可用的最佳组合,节省下来的成本自然也越可观。
apiVersion: karpenter.sh/v1beta1kind: NodePoolmetadata:name: tinybird-node-pool-statelessspec:expireAfter: 168hnodeClassRef:group: karpenter.k8s.awskind: EC2NodeClassname: tinybird-statelessrequirements:- key: karpenter.k8s.aws/instance-categoryoperator: Invalues:- c- m- r- key: karpenter.k8s.aws/instance-generationoperator: Gtvalues:- "4"- key: topology.kubernetes.io/zoneoperator: Invalues:- us-east-1a- us-east-1b- us-east-1c- key: kubernetes.io/archoperator: Invalues:- amd64- arm64- key: karpenter.sh/capacity-typeoperator: Invalues:- spot- on-demandtaints:- effect: NoSchedulekey: tinybird.co/stackvalue: stateless
但无论如何,Karpenter 在选择节点类型时仅基于价格考量,这有时会导致选择到价格相近但性能相差悬殊的实例,从而影响业务运行效率。
CloudPilot AI 在智能选型时,会综合评估价格、磁盘 I/O、网络带宽等关键因素,优先选择真正具备高性价比的实例类型。
30天免费试用已开放,欢迎注册:cloudpilot.ai
2. 关键业务时间段使用中断预算
如果你有关键业务时间段(比如早上 8 点到中午 12 点),就设置一个中断预算(Disruption Budget),禁止在这个时间段进行节点合并,从而确保集群在最重要的时间段保持稳定。
apiVersion: karpenter.sh/v1beta1kind: NodePoolmetadata:name: my-node-poolspec:disruption:consolidationPolicy: WhenUnderutilizedbudgets:- nodes: "30%" # Allows up to 30% of nodes to be disruptedreasons:- "Empty"- "Drifted"- "Underutilized"- nodes: "0" # Prevent consolidations during peak traffic periodduration: "4h"schedule: "0 8 * * *"
3. 设置节点自动过期
我们建议将节点配置为每 24 至 48 小时进行过期回收。
这种机制不仅能有效缓解内存泄漏等问题(确保 Pod 在因 OOM 错误崩溃前即被重建),还能显著提升安全性。
通过定期回收节点,每个新节点启动时都会安装最新的安全补丁,从而确保集群的安全性和时效性。
apiVersion: karpenter.sh/v1beta1kind: NodePoolmetadata:name: ttl-based-disruption-poolspec:disruption:consolidationPolicy: WhenUnderutilizedexpireAfter: 48h # Nodes expire after 2 days

05/
Karpenter 的部署建议
在部署 Karpenter 时很关键的一环是:不要将 Karpenter 控制器运行在其管理的节点池上。
原因很简单:如果运行控制器的节点被删除或启动失败,Karpenter 就无法工作,导致无法创建新节点,可能会引起集群不可用。
一种常见做法是创建一个小型、专用的 NodeGroup(比如通过 Terraform),包含少量节点,关闭自动伸缩,并在其中运行两个 Karpenter 副本。
不过这种方式也有缺点:这些节点可能利用率不高,需要手动维护和更新 NodeGroup,实际上违背了减少节点管理负担的初衷。
AWS Fargate
我们推荐的解决方案是将 Karpenter 部署在 AWS Fargate 上。
作为 AWS 提供的无服务器计算引擎,Fargate 能够无缝集成到 EKS 中。
通过定义一个包含 Karpenter Pod 选择器的 Fargate 配置文件,可以确保 Karpenter 始终独立于它所管理的节点运行。
这个方案有效避免了因节点中断导致 Karpenter 不可用的风险,也省去了维护专用节点组的运维成本。
resource "aws_eks_fargate_profile""karpenter_profile" {cluster_name = aws_eks_cluster.eks_cluster.namefargate_profile_name = "karpenter"pod_execution_role_arn = aws_iam_role.karpenter-fargate.arnsubnet_ids = ["<subnet_1>", "<subnet_2>"]selector {namespace = "karpenter"labels = {"app.kubernetes.io/name" = "karpenter"}}}
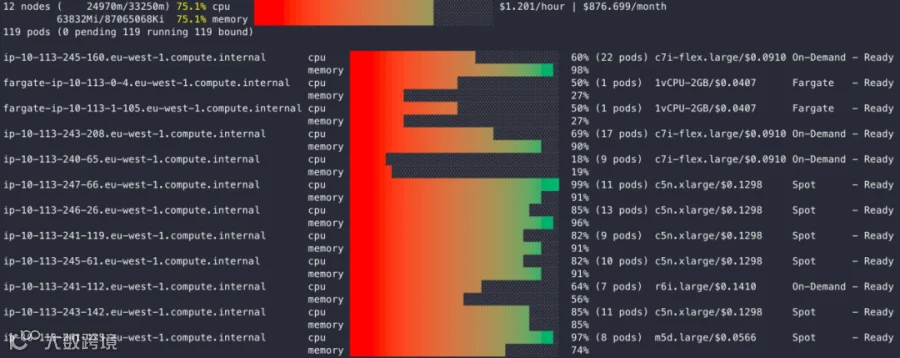
在你的 EKS 集群中,调度到 Fargate 上的 Karpenter Pod 会以节点的形式出现,但你看到的不是具体的 EC2 实例类型,而是 Fargate 分配的资源。

06/
如何加速启动时间
Karpenter 的扩缩容速度快得惊人,新建一个节点不到一分钟就能完成,但启动节点只是第一步,真正的挑战在于缩短从节点启动到 Pod 完成调度、准备好处理流量的总时间。
以下是两个简单却对我们收效显著的小技巧:
1. 使用 Harbor + Kyverno 本地缓存镜像
尽管 Karpenter+KEDA+Tinybird 的组合能让节点在不到 45 秒内完成启动,但接下来的瓶颈在于容器镜像的拉取。
在全新节点上,Kubelet 必须从镜像仓库下载所有所需镜像,而有些服务镜像体积较大。
为加快这一过程,我们在集群内部署了开源镜像仓库 Harbor 作为本地缓存。
当新节点被创建时,它会优先从 Harbor 拉取镜像,而不是每次都从 ECR 获取。
我们通过 Kyverno 策略实现这一流程的自动化,在 Pod 启动时动态重写 ECR 镜像的 DNS,使其指向我们的本地 Harbor 缓存,大大节省了拉取时间。

apiVersion: kyverno.io/v1kind: ClusterPolicymetadata:name: ecr-replace-image-registry-to-harborannotations:policies.kyverno.io/title: Replace Image Registry ECR to Harborspec:background: falserules:- name: replace-image-registry-pod-containers-legacymatch:any:- resources:kinds:- Podnamespaces:- tinybirdmutate:foreach:- list: "request.object.spec.containers"patchStrategicMerge:spec:containers:- name: "{{ element.name }}"image: "{{ regex_replace_all('<accountID>.dkr.ecr.eu-west-1.amazonaws.com/(.*)$', '{{element.image}}', 'harbor.tinybird.app/aws/$1' )}}"
2. 使用 BottleRocket AMI
我们的所有节点都运行在 BottleRocket 上——一款由 AWS 赞助支持的基于 Linux 的开源操作系统,专门为在 ECS 或 EKS 上运行容器而设计。
BottleRocket 只包含必要的系统组件,不仅减少了攻击面和安全风险,更重要的是,大幅缩短了节点的启动时间,让集群响应速度更快。
apiVersion: karpenter.k8s.aws/v1beta1kind: EC2NodeClassmetadata:name: microservicesspec:amiFamily: Bottlerocket# removed additional configuserData: |[settings][settings.kubernetes]registry-qps=25registry-burst=50serialize-image-pulls=falsetags:managed-by: karpentertinybird.k8s.workload: criticalkarpenter.sh/discovery: my-cluster-nameblockDeviceMappings:- deviceName: /dev/xvdaebs:volumeSize: 60GivolumeType: gp3deleteOnTermination: true- deviceName: /dev/xvdbebs:volumeSize: 120GivolumeType: gp3deleteOnTermination: truethroughput: 500iops: 3000snapshotID: snap-09a75da610666d675
结合这两种策略,我们将从节点创建到所有 Pod 启动、运行并准备好处理流量的时间大幅缩短了 2 分钟。
这一显著提升能够帮助我们在扩容高峰期依然保持集群的快速响应和稳定运行。

07/
总结
总的来说,采用 Karpenter 为我们的基础设施带来了很大的提升。
如果你在使用 Kubernetes,尤其是在 AWS 上,Karpenter 是一个绝对值得尝试的工具。
Karpenter 和 Spot 实例、自动伸缩(KEDA)以及实时监控结合使用,能帮助你实现更快速、更稳定且更节约成本的弹性伸缩方案。
Karpenter 智能的弹性扩缩能力帮助我们摆脱了过往运维工作的复杂繁琐,让节点管理变得更加智能和灵活,大幅降低了 AWS 成本,同时提升了集群的扩缩容速度和稳定性。
这样一来,团队可以把更多精力放在业务创新和交付上,而不是花时间维护底层基础设施。
我们还认识到,要发挥 Karpenter 的最大优势,关键在于:
了解自身的工作负载
提前做好应对中断的部署工作
学会利用本地镜像缓存和优化的 AMI
遵循控制器部署和节点类型多样性的最佳实践
如果你想让弹性伸缩变得更智能、更高效,让 Spot 实例“性价比拉满”,欢迎点击下方卡片,关注 CloudPilot AI 回复关键词【试用】,获取免费试用资格。

推荐阅读
AWS悄悄变天:预留实例退场,Savings Plan上位!
颠覆 IT 世界的 20 万行代码:Kubernetes 的前世今生(文末有彩蛋)
公司介绍
CloudPilot AI 是一家全球领先的 Karpenter 托管云服务提供商,致力于通过智能化、自动化的云资源调度和编排技术,帮助企业最大化云资源利用率。我们秉持“让客户在云中花费的每一分钱都物超所值”的使命,为客户提升10倍的资源效率,同时将云成本降低50%以上。
目前,开源K8s弹性伸缩器 Karpenter 已为全球超500家知名企业在生产环境中提供服务,包括阿迪达斯、Anthropic、Slack、Figma等。CloudPilot AI 已为数百家全球顶尖科技公司提供服务,累计为客户节省超过千万美金,平均节省67%。 选择CloudPilot AI,让每一笔支出都更智慧。
免费试用,2步5分钟,降低50%云成本:
cloudpilot.ai