
点击上方卡片,关注「CloudPilot AI」
回复关键词【案例】
查看多邻国、Canva等名企的云端降本实践

01/
为什么 Java 工作负载在 Kubernetes 上难以优化
Java 应用在 Kubernetes 上面临着独特的优化挑战,通用的资源调优工具无法有效解决。
内存盲区
大多数 Kubernetes 优化工具——包括 VPA 和许多商业平台——只能看到容器级指标,如 RSS 和 Working Set。但对于 Java 工作负载而言,真正的关键在 JVM 内部:
- 容器指标会”骗人”。
一个容器报告 4 GB 内存使用量,并不能说明 JVM Heap 是否多分配了 2 GB,还是即将触发一次 Full GC。 - Heap 过大:
内存空闲堆积,白白增加云成本。 - Heap 过小:
GC 压力升高,延迟飙升,OOM 只是时间问题。 - 手动调优无法规模化。
正确设置 Xmx需要深厚的 JVM 专业知识,而最优值会随流量模式变化而漂移。团队人员变动后,经验知识无法传承。
根本原因在于:容器级 Rightsizing 和 JVM Heap 调优被当作两个独立问题处理,而它们本应是一个协同的优化闭环。
启动阶段的资源冲突困境
Java 应用在启动阶段(类加载、JIT 编译、Spring 上下文初始化)消耗的 CPU 远高于稳态运行时。如果没有自动化手段,团队将面临一个两难选择——我们在下文的 ResourceStartupBoost 章节中展开讨论。

02/
实战效果
某客户将多个基于 Java 的集群接入了 CloudPilot AI Workload Autoscaler。在优化 Pipeline 生效后,所有集群的实际内存消耗均显著下降——无需任何手动调优或服务中断。
在 Cluster A 中,实际内存使用从 ~352 GiB 降至 194 GiB——降幅达 45%——同时 Requested 内存从 352 GiB 精简到 245 GiB。
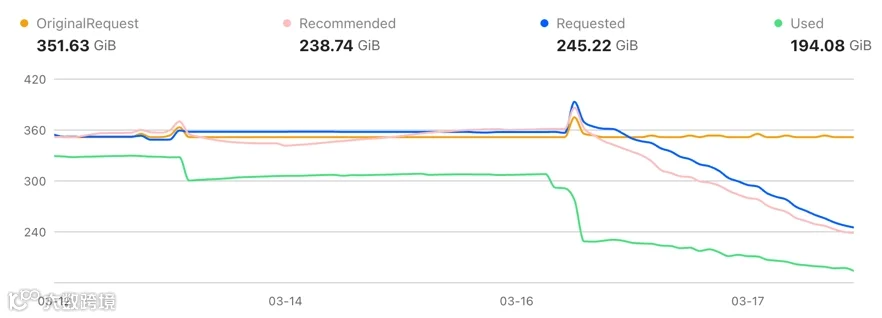
在 Cluster B 中,实际内存使用从 ~255 GiB 降至 154 GiB——降幅达 40%——Requested 内存从 255 GiB 降至 235 GiB。
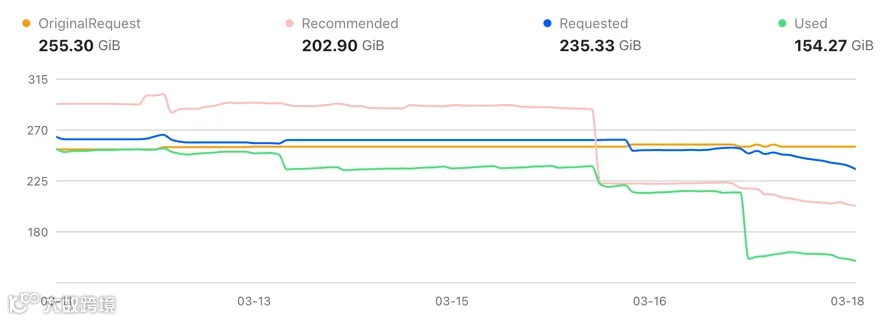
两个集群合计减少了超过 250 GiB 的内存消耗——综合降幅 43%。
这不是纸面上的 Requests/Limits 调整。节省来自实际内存消耗的降低,源于 JVM Heap 和容器级别的联合优化。

03/
Java 内存优化:从”容器调优”到”JVM + 容器联合优化”
核心能力
- JVM 级可观测性
cloudpilot-node-agent采集 Heap Used/Committed/Max、GC 频率、GC 暂停时间、GC 压力趋势等指标——决策不再仅依赖外层容器指标。 - 直接管理 Heap
Heap 推荐范围(包括 Xmx)由系统直接管理,并与 Pod 内存推荐在同一优化闭环中协同计算。 - GC 风险控制
GC 压力、暂停行为、对象分配速率均纳入每一次推荐决策,确保成本节省不以可靠性为代价。
内存推荐的工作原理
目标不是简单地”缩减内存”——而是在稳定性和效率之间找到最佳平衡点:
- 观测(Observe)
— 采集 JVM 指标(Heap、GC、分配趋势)及容器指标(RSS、OOMKill 历史、重启次数)。 - 建模(Model)
— 基于多时间窗口百分位数估算真实 Heap 需求,降权部署期抖动等离群点。 - 推荐(Recommend)
— 输出一对协同的推荐值:目标 Xmx范围(含突发缓冲和 GC 安全裕度)以及匹配的 Pod Requests/Limits(考虑 Non-Heap 开销:Metaspace、Code Cache、Thread Stacks、Native Memory)。 - 验证(Validate)
— 变更上线后持续监控 GC、延迟、OOM 和利用率。当风险阈值被触发时自动重新调整。


04/
ResourceStartupBoost:解决 Java 启动阶段的资源尖峰
Java 应用在启动阶段和稳态运行时有截然不同的资源画像。如果没有 ResourceStartupBoost,团队只能在两种不完美的策略之间做选择:
两难困境
方案 A:按稳态使用量配置资源
如果根据稳态用量设置 Requests/Limits,启动阶段会受影响:
-
类加载、JIT 编译、Spring 上下文初始化期间遭遇 CPU Throttling,导致启动缓慢甚至失败。 -
Readiness Probe 超时触发反复重启,产生级联调度压力。 -
Rolling Deployment 时新 Pod 无法及时就绪,产生容量缺口和用户侧报错。
方案 B:按启动峰值配置资源
如果将 Requests/Limits 设置得足够高以覆盖启动尖峰,稳态阶段就会浪费:
-
为仅持续几分钟的峰值预留的资源,在数小时甚至数天内处于空闲状态。 -
Scheduler 看到虚高的 Requests,降低了 Pod 装箱效率,集群整体的 Packing Density 下降。 -
云成本上升,但在正常运行期间没有任何性能收益。
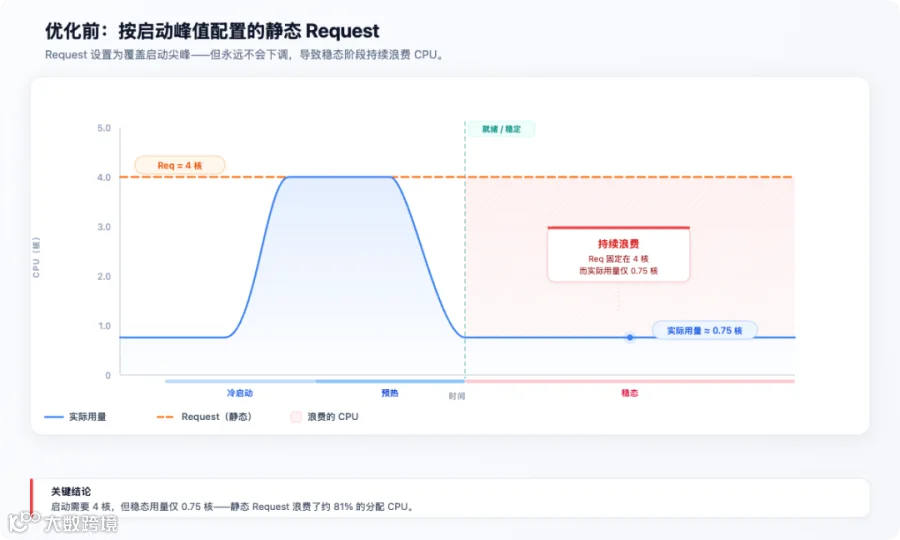
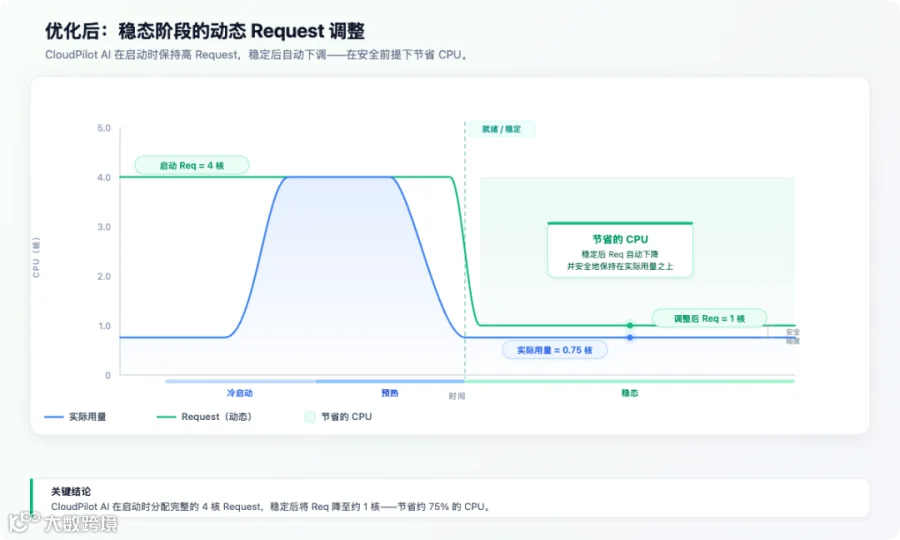
我们的方案:两者兼得
ResourceStartupBoost 通过将启动配置与稳态配置解耦,消除了这个 Trade-off:
- 启动阶段(Boost Window)
临时提升 Pod 的 CPU/Memory Requests/Limits,吸收启动阶段的峰值开销——确保快速、可靠地启动,不会出现 Throttling 或超时失败。 - 稳态阶段
应用稳定后自动回落到推荐的稳态值——释放资源并保持集群高 Packing Density。
结果:兼具方案 B 的启动可靠性和方案 A 的成本效率,无需任何手动配置管理。
为什么需要与 Node Autoscaler 协同?
ResourceStartupBoost 无法独立运作——它依赖与 CloudPilot Node Autoscaler 的紧密协同。原因如下:当 Startup Boost Window 结束后,Pod 的 CPU Requests 回落到稳态水平(例如从 4 核降到 1 核)。独立运行的 Node Autoscaler 只看到这些低水平的稳态 Requests,于是判定节点有大量空闲容量,继续往上装载更多 Pod,甚至缩容”利用率不足”的节点。
当 Pod 需要重启时问题就暴露了——无论是 Rolling Update、Crash Recovery 还是重新调度。Pod 再次需要 Startup Boost(例如 4 核),但节点已按稳态数值紧密装箱,没有空间。结果:Pod 陷入 Pending 状态,集群紧急扩容新节点,原本几秒就能完成的重启变成了几分钟。
CloudPilot 通过让 Node Autoscaler 感知 Boost 来解决这个问题。它了解每个工作负载的 Startup Boost Profile,并将这些潜在资源需求纳入装箱和扩缩容决策。Node Autoscaler 预留足够的 Headroom,确保任何 Pod 重启时,Startup Boost 都能立即满足——无需紧急扩容节点,也不会为了”以防万一”而过度预留整个集群的资源。


05/
技术原理
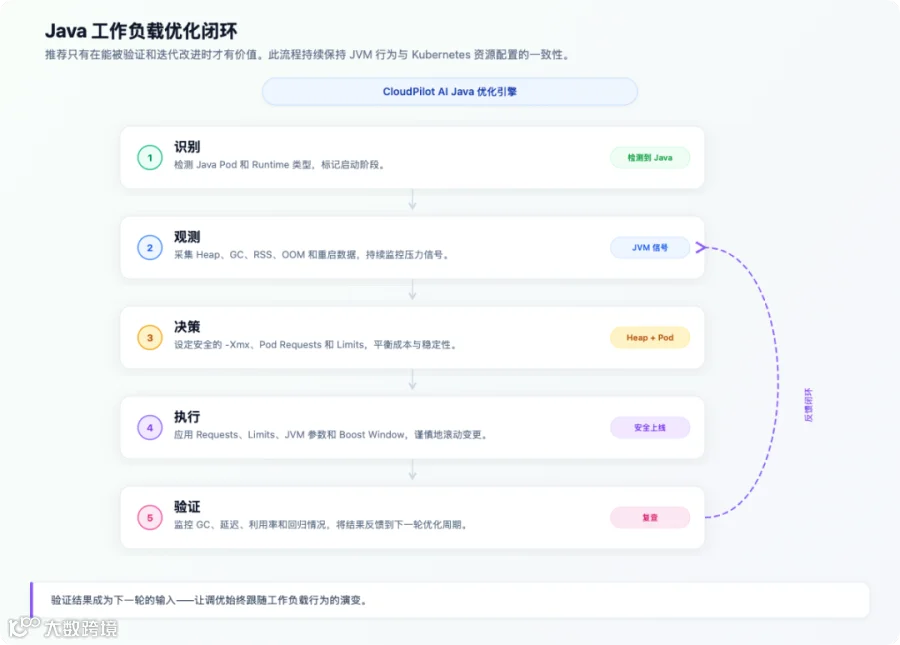
CloudPilot AI Workload Autoscaler 为每个 Java 工作负载运行一条专属优化 Pipeline:
- 识别(Identification)
cloudpilot-node-agent检测每个 Pod 的语言和 Runtime Profile,自动按RuntimeLanguage进行分类。 - 观测(Observation)
采集关键 JVM 指标(Heap Used/Committed/Max、GC 频率、GC 暂停时间、GC 压力趋势、容器 RSS/Working Set,以及 Pod OOM 和重启历史)。 - 决策(Decisioning)
同时建模稳定性目标(避免 OOM、降低 Full GC 风险)和成本目标(消除空闲内存浪费),输出 Pod 资源推荐和 JVM Heap 推荐。 - 执行(Execution)
协同 Kubernetes Requests/Limits 和 JVM 参数(如 Xmx),并基于反馈持续调优。 - 启动加速(Startup Boost)
在启动窗口期启用 ResourceStartupBoost临时提升资源,应用稳定后回落到稳态推荐值。

06/
竞品分析
我们对最常见的替代方案在 Java 特定优化能力维度进行了评估。虽然所有平台都支持基础的容器 Requests/Limits 调优,但差异体现在 JVM 级智能和启动阶段感知能力上。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
-Xmx
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- 开源 VPA
完全在容器层面运行,对 JVM 内部没有任何可见性,容易导致 Java Heap 的过度或不足分配。 - Cast AI
提供强大的容器级 Rightsizing 和 In-place Pod Resizing 能力,但不提供 JVM 级可观测性或 Heap 参数管理。对于启动尖峰,它依赖 Kubernetes 原生机制(如 Startup Probe、移除 CPU Limits)而非集成的 Boost-and-Fallback 工作流。 - ScaleOps
在 2025 年末推出了 JVM 感知的资源管理,提供 Heap/GC 可观测性和 Xmx调优。但其优化决策侧重于将 Heap 与容器内存对齐,而非将 GC 风险信号(暂停时间、压力趋势、分配速率)直接嵌入推荐模型。它也不支持启动与稳态阶段的资源分离。 - CloudPilot AI
将 JVM 级可观测性、直接 Xmx管理与 GC 风险感知决策,以及ResourceStartupBoost的阶段感知资源管理相结合——提供完整的闭环优化 Pipeline。

07/
总结
Java 工作负载需要的不仅仅是更小的容器——而是JVM 与容器的协同优化。CloudPilot AI Workload Autoscaler 通过三项互相增强的能力实现这一目标:

在生产环境中,这转化为客户集群 40–45% 的实际内存降幅——节省来自真实消耗的减少,而不仅仅是 Requests 和 Limits 的纸面调整。
想了解 CloudPilot AI 能为您的 Java 工作负载带来什么?联系我们的团队以了解更多。

推荐阅读
全球抢 GPU,Kubernetes 却闲置?看 DRA 如何让算力按需飞
别了,EC2 Auto Scaling!AWS 2025 变革信号背后的行业真相
公司 GPU 还在 “摸鱼” 吗?这项Kubernetes 技术或许能帮你节省百万算力成本
公司介绍
CloudPilot AI 是一家总部位于旧金山硅谷的科技公司。致力于彻底变革云基础设施的管理方式
我们秉持“为全世界最严苛的团队自动扩展Kubernetes集群”的使命,已为数百家全球顶尖科技公司提供服务,累计为客户节省超过5亿美金,平均节省67%。
免费试用,2步5分钟,降低50%云成本:
cloudpilot.ai