
前言
-
Kubernetes作为云原生容器编排调度领域的事实标准,在公共云、私有云、混合云、边缘计算领域都发挥了巨大作用,企业不断将自身信息系统的工作负载部署在Kubernetes平台,利用Kubernetes提供的资源弹性、服务自愈等能力优化自身的IT基础设施。 -
本文通过对
Kubernetes生态的KEDA、Karpenter的实践方案介绍,通过上述组件来帮助企业更好基于Kubernetes平台的弹性能力优化企业的IT成本、简化企业的运维管理以及提升企业IT信息系统的稳定性。
KEDA介绍
-
KEDA(Kubernetes Event-Driven Autoscaling)[1]是CNCF毕业的开源项目,可以安装部署在任意Kubernetes集群(无供应商锁定); KEDA扩展了HPA,Horizontal Pod Autoscaling[2]的能力,使部署在Kubernetes集群的工作负载具备了基于事件驱动的弹性扩展能力; -
KEDA的架构图如下,更多关于KEDA的组件、工作原理、架构的介绍,可以参考KEDA Concepts[3]
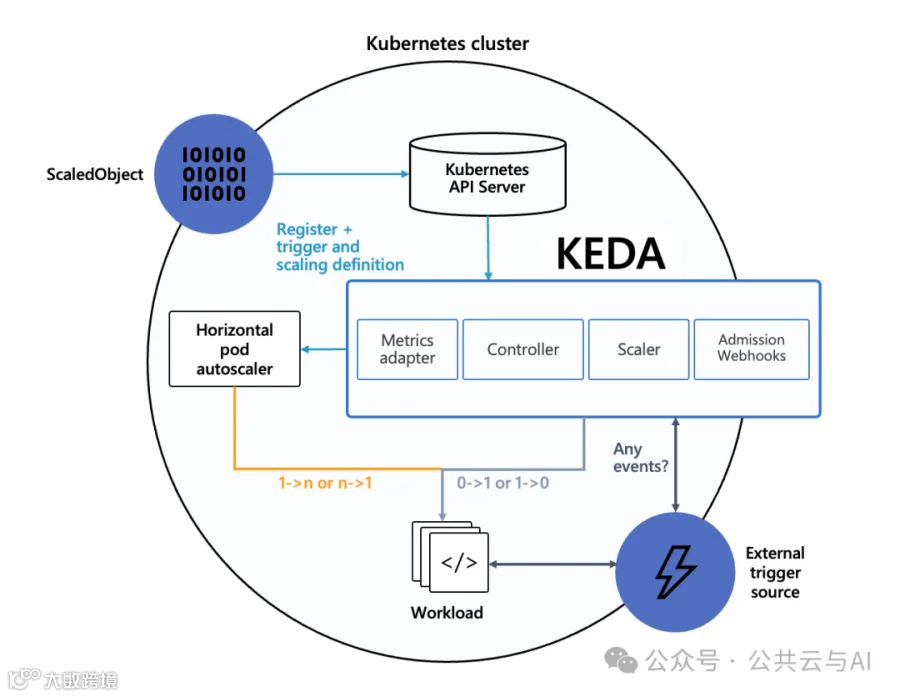
-
KEDA使用了Kubernetes Operator Model[4]模式,通过定义Custom Resource Definitions,CRD[5]来让用户实现基于事件驱动的弹性伸缩,KEDA可以实现当没有外部事件驱动的时候让Deployment缩容到0的特性(对于Kubernetes集群资源成本优化非常不错!);KEDA的相关组件和一些关键常用参数可以参考Scaling Kubernetes: Intro to Kubernetes-based event-driven autoscaling (KEDA)[6];更多KEDA详细技术资料可以直接参考KEDA官网[7]
Karpenter介绍
-
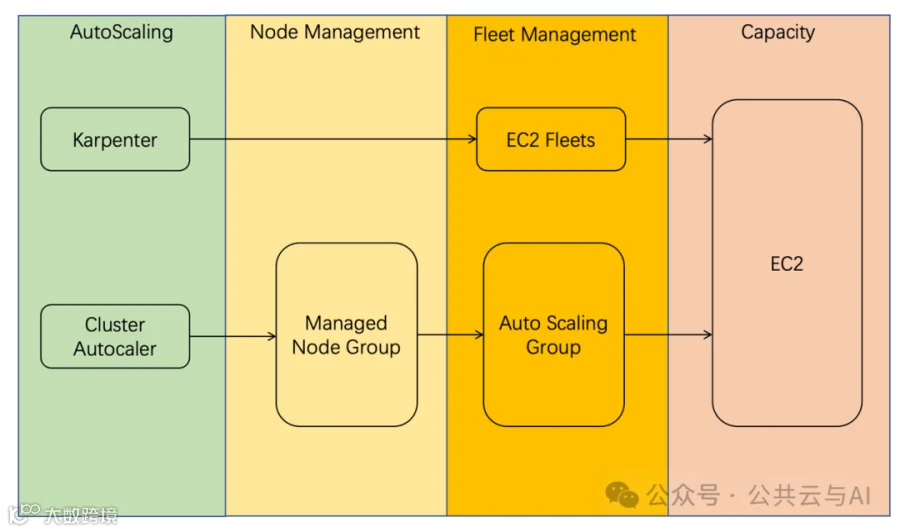
传统的Kubernetes Cluster Autoscaling[8]在面对Kuberntes集群生产级的节点弹性伸缩会有一些限制问题
依赖 Cloud Provider的launch template和Auto Scaling Group,因此Auto Scaling Group的最大值和最小值会限制弹性伸缩节点组的最大和最小节点数量Cluster Autoscaler处理错误的机制是基于超时,对于大规模节点集群(例如集群节点超过1000,每个节点部署超过30个Pod)没有官网的性能测试数据Cluster Autocaler中,Auto Scaling group总会不断请求Cloud Provider来确认状态,在集群庞大以后,很可能碰到API调用限制,造成整个系统停止响应
-
Karpenter取消了节点组的概念(使用EC2 Fleets),仅在创建和删除节点时调用Cloud Provider API,降低了调度的复杂度,能够支持更高的API吞吐量;同时Karpenter对调度也进行了优化,一旦容量扩容的决定被做出,发出创建实例的请求,会立即获得实例ID,不等实例创建完成就创建节点对象,将需要调度的pod绑定到节点;
-
Karpenter不止增加节点,也负责终止节点。其有一个控制器专门负责终止节点,默认一个节点5分钟内没有pod,Karpenter就会终止它。另外,当EC2实例由于某种原因处于unhealthy状态或spot实例即将被回收,它都会发送一个事件,Karpenter会响应这些事件,新创建节点来重部署上面的pod。另外Karpenter也可以为节点设置一个TTL值,比如配置节点生命周期是90天,这个功能在升级时非常有用,可以确保节点一直滚动升级 -
Karpenter也对节点的启动过程做了优化,节点启动的延迟被Karpenter减少到了15~50秒; -
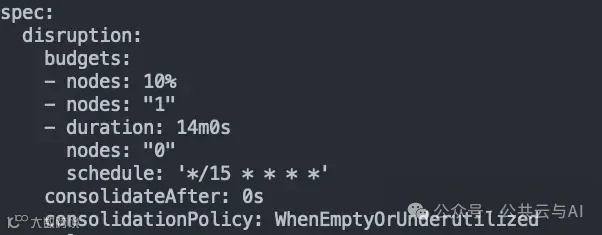
Karpenter可以灵活配置中断预算(Disruption Budget),精准控制节点更新的频率,根据工作负载的重要性分配不同级别的可靠性要求,Karpenter的中断预算与用户配置的Pod 中断预算(PDB)紧密配合,确保升级过程中的高可靠性,例如,在设定的 15 分钟窗口内,如果 PDB 要求不允许任何节点中断,Karpenter将跳过该窗口,确保服务的持续稳定。这种机制在多租户场景下尤为重要,因为它能够完全满足用户对可靠性的严格要求,确保服务始终处于高可用状态
-
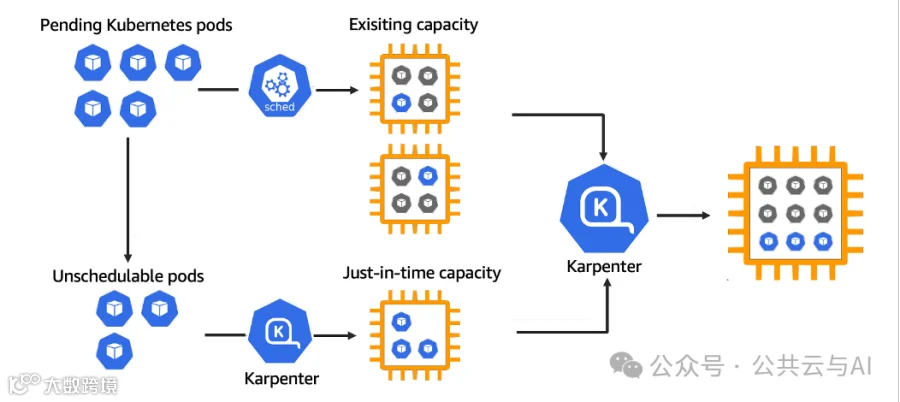
Karpenter的工作过程,如下图所示:当有一个pending状态的pod时,如果还有存在的容量,则由kube scheduler进行调度。如果没有容量造成pod不能被调度,则由Karpenter绕过kube scheduler将pod绑定到新建的预置节点;
-
可以参考Karpenter官网[9]获取更多的 Karpenter信息,目前通过Karpenter提供的Cloud Provider接口,已经可以在AWS EKS、Azure AKS、阿里云ACK上使用Karpenter
实践方案介绍
-
1.1 方案一架构
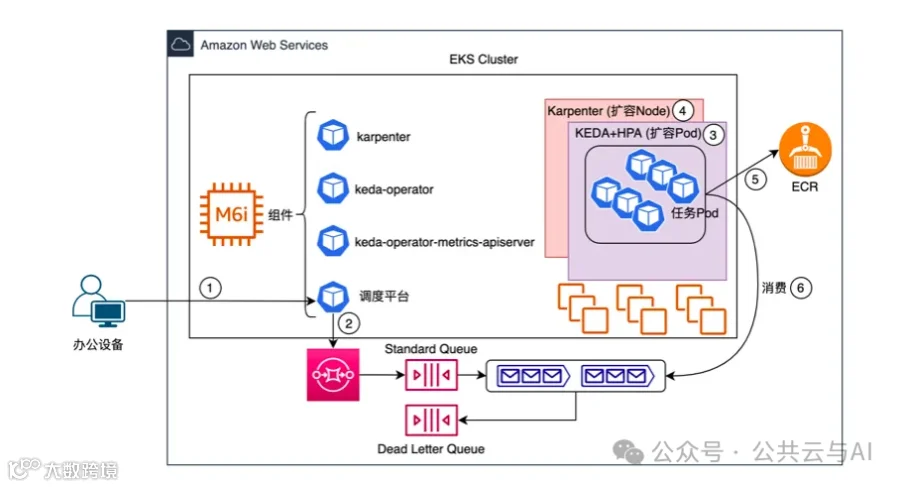 容器服务由
容器服务由AWS EKS进行托管,当然如果在其他云平台(例如阿里云或者Azure),可以选择对应AWS EKS的容器集群服务产品
-
方案一说明
-
发起新任务到调度平台(例如 Airflow调度平台) -
调度平台对任务进行拆解,将子任务存储到 Amazon SQS Queue,当然如果在其他云平台(例如阿里云或者Azure),可以选择对应AWS SQS的托管消息队列产品 -
引入KEDA组件,KEDA组件监控到Amazon SQS Queue中有新的子任务,创建任务Pod -
Karpenter创建新的Node,任务Pod被分配到新的Node -
任务Pod从Amazon ECR拉取镜像启动,当然如果在其他云平台(例如阿里云或者Azure),可以选择对应AWS ECR的托管容器镜像仓库产品 -
任务Pod从Amazon SQS Queue中获取子任务并进行计算 -
方案优势
根据任务数量和负载情况动态调整计算资源规模,按需进行资源付费,最大程度优化云IT资源成本
-
1.2 方案二架构
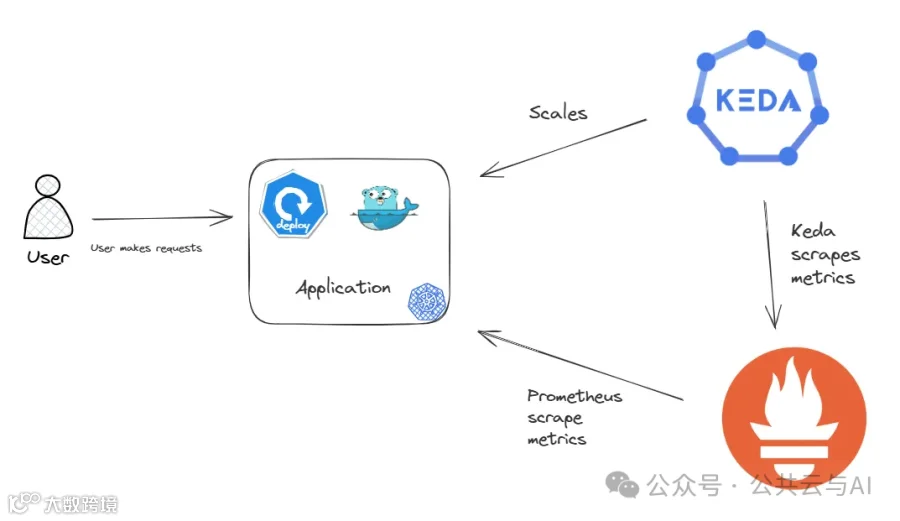
-
方案说明:结合 Prometheus和KEDA实现基于用户自定义指标的事件驱动的pod弹性伸缩演示,demo代码托管在我的GitHub仓库[10]
KEDA(Kubernetes Event-Driven Autoscaling):https://keda.sh/
[2]HPA,Horizontal Pod Autoscaling:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
[3]KEDA Concepts:https://keda.sh/docs/2.16/concepts/#architecture
[4]Kubernetes Operator Model:https://kubernetes.io/docs/concepts/extend-kubernetes/operator/
[5]Custom Resource Definitions,CRD:https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/
[6]Scaling Kubernetes: Intro to Kubernetes-based event-driven autoscaling (KEDA):https://opensource.microsoft.com/blog/2020/05/12/scaling-kubernetes-keda-intro-kubernetes-based-event-driven-autoscaling/
[7]KEDA官网:https://keda.sh/
[8]Kubernetes Cluster Autoscaling:https://kubernetes.io/docs/concepts/cluster-administration/cluster-autoscaling/
[9]Karpenter官网:https://karpenter.sh/
[10]GitHub仓库:https://github.com/mingyu110/Best-Practice/tree/main/goprometheuskeda
推荐阅读
1000+节点、200+集群,Slack如何利用Karpenter提效减负?
项目介绍
Karpenter 于2021年11月推出并开源,是一款开源的Kubernetes集群自动扩缩容工具,专为优化 Kubernetes 集群的工作负载设计,旨在以灵活、高性能和简洁的方式实现节点的弹性扩展。今年9月已发布1.0版本。目前,Karpenter 已为全球超500家知名企业在生产环境中提供服务,包括阿迪达斯、Anthropic、Slack、Figma等。
Karpenter项目地址:
https://github.com/kubernetes-sigs/karpenter