
点击上方卡片,关注「CloudPilot AI」
回复关键词【案例】
查看奥迪、Grafana等名企的云端降本实践

Fiverr 是全球知名的自由职业在线平台之一,成立于2010年,目前在全球拥有400万买家,年度交易额达11.3亿美元。
本文将介绍 Fiverr 基础设施团队在 2024 年完成的一项迁移实践,详细记录了他们如何从 Kubernetes 迁移至 Karpenter,并从中获得了哪些收益。
另外,还提供了可以直接抄作业的 Helm 模板配置和 Grafana 监控面板配置。
在 Fiverr,我们始终追求基础设施的优化与资源高效利用。
最近,我们完成了一项重要的迁移工程——将 Kubernetes 的计算节点迁移至 Karpenter 。
本文将详细介绍我们的迁移过程、收获的优势,以及我们在过程中开发并开源的一些辅助工具。

01/
为什么需要改进?
在采用 Karpenter 之前,我们一直依赖第三方方案来管理 Kubernetes 的计算节点,但这种方式存在不少问题:
手动更新繁琐:
节点通过基础设施即代码(IaC)管理,需要频繁运行 terraform apply 才能保证使用最新的 OS 镜像。在我们自动化 IaC 流程之前,这个过程非常繁琐且低效
实例类型需指定:
必须手动配置实例类型和规格,不利于多架构兼容和自动采用新一代实例,灵活性严重受限
人工回收节点:
节点回收完全依赖脚本和手动操作,需要紧密监控,既耗时又容易出错
资源浪费:
在这个成本敏感的时代,“资源浪费”就是原罪
Spot 实例中断频繁:
节点频繁替换导致系统噪音,影响稳定性

02/
为什么选择 Karpenter?
Karpenter 是一款开源的 Kubernetes 集群自动扩缩工具,专为优化性能和成本而设计,旨在以灵活、高性能和简洁的方式实现节点的弹性扩展。它能基于真实资源需求动态扩缩节点容量,为 Pod 提供调度资源。同时,与 Kubernetes scheduler 集成,为 Pending 的 Pod 指定节点。
核心优势:
动态资源分配:可指定 CPU 核数、最低机器代数、架构与处理器制造商,避免了节点组的复杂配置。
节点合并优化:充分利用节点资源,避免资源浪费。
K8s 镜像与架构兼容性保障:适配性强,部署省心。
容量智能调度:当指定实例容量不足时可自动回退到按需实例或替代实例类型。
漂移管理:系统升级或补丁时,自动替换旧节点。
维护窗口支持:根据预算和调度设置控制节点更替频率。
优先级机制:为不同实例类型设定优先级,降低中断率和系统扰动。

03/
Karpenter 并非十全十美
迁移过程并不是一帆风顺,在采用 Karpenter 的过程中,我们遇到了一些挑战:
多可用区节点分布:
确保节点在不同可用区之间分布均衡——通过 topology.kubernetes.io/zone 结合 topologySpreadConstraints 实现
激进的bin-pack策略:
默认尽量将更多 Pod 安排到更少的节点上以节省资源,但这样容易让某些节点压力过大——使用基于 hostname 的拓扑分布策略,避免节点超载
不同实例资源占比:
如何管理 Spot 实例和按需实例的使用比例——借助 capacitySpread 和 topologySpread
YAML 管理复杂:
通过编写 Helm 模板来统一配置并降低重复工作

04/
整体迁移流程概述
在专属 Auto Scaling Group 中部署 Karpenter Controller
通过 Helm 模板定义节点组规格
逐步减少第三方解决方案中的管理下 NodeGroup 的最小/最大节点数,一旦节点被移除,就让 Karpenter 接管
按优先级分批次迁移(从非关键负载开始)
对于某些场景,禁用合并策略并设置实例空闲 TTL,以防止业务中断

05/
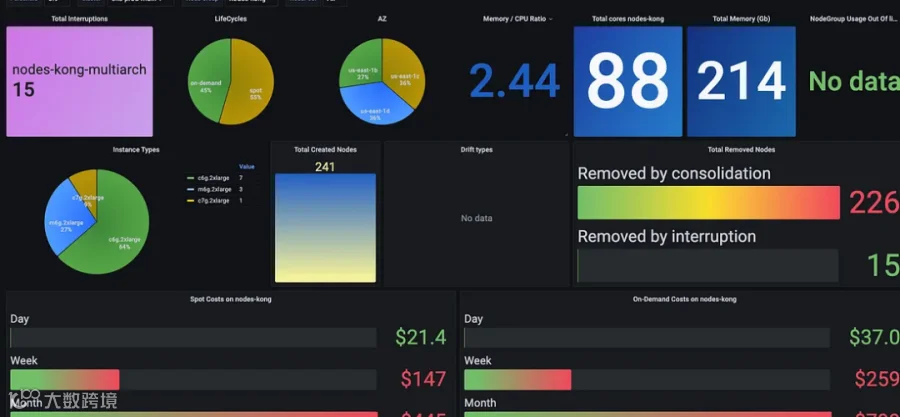
构建清晰的监控体系
Karpenter 对 Prometheus 提供了非常全面的监控指标,我们基于此构建了可导入的 Grafana 可视化面板。
要抄作业可访问下方链接查看:
https://github.com/fiverr/public_charts/tree/master/charts/karpenter_nodes/grafana
主要监控指标:
各 NodeGroup/NodePool 的中断率
超出限制的容量使用情况(如果您定义了limit数值)
潜在成本
容量类型
跨可用区(AZ)分布
节点合并、漂移与调度成功率
Karpenter 本身的运行表现

06/
使用 Helm 简化 NodeGroup 管理
在使用 Karpenter 之前,我们使用 IaC 配置 NodeGroup,但过程非常重复繁琐。
现在我们使用 Helm 模板,实现了:
全局和局部参数灵活配置
自动添加标签(labels)、标记(tags)和污点(taints)等
快速生成 NodeGroup 列表,按需设置个性化覆盖
这个 Helm 模板的设计初衷是让你可以非常简单地创建一个 NodeGroup 对象列表,并在需要的地方进行局部覆盖配置。
例如:
你可能希望某个特定的 NodeGroup(或 NodePool)使用不同的 AMI family、IAM 角色 或 实例配置文件,那么你只需要在该对象中单独指定即可,无需重复编写整套配置。
抄作业指路:https://github.com/fiverr/public_charts/tree/master/charts/karpenter_nodes/examples
对于使用 ArgoCD 的用户,我们建议忽略对 NodeClaim 资源的同步管理,以避免浏览器在渲染大量 NodeClaim 时出现性能问题。
resource.exclusions: |- apiGroups:- "karpenter.sh"kinds:- "NodeClaim"

07/
成果总结
迁移到 Karpenter 之后,我们在 Fiverr 的运维方式发生了巨大转变:系统变得更高效、更具弹性,同时也更易于管理和扩展。
为了让 Helm 模板更清晰、可复用,我们将配置拆分为多个文件:
📁 common.yaml
用于定义所有 NodeGroup 的通用配置,如:IAM 权限、AMI 类型、EBS 配置、子网、可用区、安全组等。
📁 userdata.yaml
用于编写所有 NodeGroup 通用的 User Data。
📁 nodegroups.yaml
列出了我们希望生成的所有 NodeGroup(或 NodePool),并支持按需设置每个节点组的个性化参数(如标签、容量类型、资源限制等)。
完整的配置模板和示例已在 GitHub 开源:
https://github.com/fiverr/public_charts/tree/master/charts/karpenter_nodes/examples
以下是示例配置片段:
nodeGroups:nodes-default:autoTaint: "false"weight: 2instances:categories:- m- rcapacitySpread:start: 1end: 5nodes-default-od:autoTaint: "false"nodeGroupLabel: nodes-defaultcapacitySpread:start: 6end: 6instances:minGeneration: 5categories:- m- rcapacityType:- on-demandnodeClassRef:name: nodes-default-amd64nodes-workers:weight: 2instances:categories:- m- rcapacitySpread:start: 1end: 5nodes-workers-c:nodeGroupLabel: nodes-workerscapacitySpread:start: 1end: 5instances:categories:- cnodeClassRef:name: nodes-workers-amd64nodes-canary:instances: {}capacitySpread:start: 1end: 5nodes-jobs:expireAfter: "Never"instances:capacityType:- on-demandcores:- "8"- "16"consolidationPolicy: "WhenEmpty"blockDeviceMappings:- deviceName: /dev/xvdaebs:deleteOnTermination: trueencrypted: trueiops: 9000throughput: 125volumeSize: 500GivolumeType: gp3nodes-ingress:registryCache: "false"expireAfter: "Never"instances:architecture: "multiarch"capacityType:- on-demandminGeneration: 7cores:- "8"
点击下方卡片关注「 CloudPilot AI 」,我们将持续带来各企业成本优化的优秀实践案例💡

推荐阅读
🎯 Spot Insights:Chrome 扩展插件上线!

公司介绍
CloudPilot AI 是一家全球领先的 Karpenter 托管云服务提供商,致力于通过智能化、自动化的云资源调度和编排技术,帮助企业最大化云资源利用率。我们秉持“让客户在云中花费的每一分钱都物超所值”的使命,为客户提升10倍的资源效率,同时将云成本降低50%以上。
目前,开源K8s弹性伸缩器 Karpenter 已为全球超500家知名企业在生产环境中提供服务,包括阿迪达斯、Anthropic、Slack、Figma等。CloudPilot AI 已为数十家全球顶尖科技公司提供服务,累计为客户节省超过千万美金,平均节省67%。 选择CloudPilot AI,让每一笔支出都更智慧。
免费试用,2步5分钟,降低50%云成本:
cloudpilot.ai