
Karpenter 开源地址:
https://github.com/kubernetes-sigs/karpenter
在 Kubernetes 中,节点资源的供需关系直接影响着集群的稳定性与应用的可用性。为了实现资源的高效调度与成本优化,自动化的节点管理尤为关键。
Karpenter 是一款开源的 Kubernetes 集群自动扩缩容工具,它在 EKS 中负责动态创建或回收 EC2 节点。虽然目前运行状况良好,但出于生产保障考虑,我们仍然需要对其进行全面监控。
本文将手把手教你完成以下目标:
-
• ✅ 将 Karpenter 的指标接入 Prometheus / VictoriaMetrics; -
• ✅ 筛选出最有用的 Karpenter 指标; -
• ✅ 使用 Grafana 创建可视化仪表盘,全面监控 WorkerNodes 的资源与状态;
总体来说,这篇文章更偏向讲解 Grafana,而不是 Karpenter,不过在 Grafana 的图表中,我们主要使用的还是来自 Karpenter 的监控指标。
第一步:收集 Karpenter 指标
我们的 VictoriaMetrics 是通过专用 Helm Chart 部署的,具体可参考:
https://github.com/VictoriaMetrics/helm-charts
要添加一个新的 target ,只需更新该 Helm Chart 的 values.yaml 配置文件,并添加以下 Karpenter 的指标端点:
karpenter.karpenter.svc.cluster.local:8000部署后通过端口转发检查目标:
kk port-forward svc/vmagent-vm-k8s-stack 8429检查目标状态:

查看指标数据:
kk port-forward svc/vmsingle-vm-k8s-stack 8429通过{job="karpenter"}查询:

第二步:了解 Karpenter 的核心概念与关键指标
核心概念
-
• Controller:
Karpenter 的子组件之一,如 Pricing Controller 处理实例价格,Disruption Controller 负责节点中断处理。 -
• Reconciliation:
当实际状态与期望状态不一致时(如缺乏资源调度 Pod),Karpenter 会自动调整。 -
• Disruption:
节点替换、缩容、漂移(Drift)等触发行为。 -
• Interruption:
实例被 EC2 停用,如 Spot 被收回,或硬件异常等。 -
• Provisioner:
根据 Pod 资源请求决定是否扩容节点。
实用指标分类汇总
以下为当前最有用的指标:
完整列表参见 Inspect Karpenter Metrics 和 Datadog 文档:https://karpenter.sh/docs/reference/metrics/
https://docs.datadoghq.com/integrations/karpenter/
Controller:
-
• controller_runtime_reconcile_errors_total:
工作节点更新时错误数量,比如执行过期、漂移、中断、整合操作时,在 Disruption Controller 中出错的次数 (适用于 Grafana 图表或告警) -
• controller_runtime_reconcile_total:
每个 Controller 所有 Reconciliation 操作次数
Consistency:
-
• karpenter_consistency_errors:
一致性检查失败的次数,当前为空
Disruption:
-
• karpenter_disruption_actions_performed_total:
中断操作总数(如节点替换) -
• karpenter_disruption_eligible_nodes:
可被中断的节点数量 -
• karpenter_disruption_replacement_nodeclaim_failures_total:
新节点替换失败次数
Interruption:
-
• karpenter_interruption_actions_performed:
EC2中断事件处理次数
Nodeclaims:
-
• karpenter_nodeclaims_created:
创建 NodeClaims 数量 -
• karpenter_nodeclaims_terminated:
NodeClaims 终止数量
Provisioner:
-
• karpenter_provisioner_scheduling_duration_seconds:
调度耗时
Nodepool:
-
• karpenter_nodepool_limit:
NodePool 资源限制(spec.limits) -
• karpenter_nodepool_usage:
NodePool 资源使用量(CPU /内存/存储/Pod 数)
Nodes:
-
• karpenter_nodes_allocatable:
提供现有 WorkerNode 的详细信息(类型/CPU/内存/Spot 或按需/所在可用区等) -
• 可统计 Spot /按需实例数量 -
• sum(karpenter_nodes_allocatable) by (resource_type):
可用于获取当前集群总的 CPU/内存资源 -
• karpenter_nodes_created:
节点创建总数 -
• karpenter_nodes_terminated:
节点终止总数 -
• karpenter_nodes_total_pod_limits:
各节点非 DaemonSet 的 Pod 资源限制总和 -
• karpenter_nodes_total_pod_requests:
各节点非 DaemonSet 的 Pod 请求总和
Pods:
-
• karpenter_pods_startup_time_seconds:
Pod 从创建到 Running 状态的时间 -
• karpenter_pods_state:
Pod 状态(含所在节点/命名空间等信息)
Cloudprovider:
-
• karpenter_cloudprovider_errors_total:
AWS 报错数 -
• karpenter_cloudprovider_instance_type_price_estimate:
实例类型成本
第三步:创建 Grafana 可视化面板
虽然 Grafana 上已经有一个现成的 Karpenter 可视化面板,但它的信息量其实非常有限,不够直观或实用。
不过你依然可以从中提取一些图表组件或 PromQL 查询语句,作为参考或二次改造的基础。
目前,我已经基于实际需求自建了一个自定义可视化面板,主要用于查看每个 WorkerNode 的状态与资源使用情况,包括 CPU、内存、节点标签、调度行为等关键指标。

在这个面板的图表中,我设置了数据链接,可以跳转到展示特定 Pod 详细信息的可视化面板。

下面展示的 ALB 图表是基于 Loki 中的日志构建的。
我们接下来的做法是:创建一个新的可视化面板,展示所有 WorkerNode 的概览信息,然后在这个可视化面板的图表中添加数据链接,跳转到之前提到的第一个面板。
这样就能形成一套良好的导航逻辑:
✅「总览面板」:展示所有 WorkerNode 的整体状态并支持点击跳转到某个节点的详细面板
✅「节点详情面板」:查看该节点上的 Pod 资源、状态等信息
可视化面板规划
我们来思考一下,在新的 Grafana 可视化面板中希望看到哪些内容:
过滤器 / 变量
-
• 可查看所有 WorkerNodes 整体或单独选择特定节点 -
• 可按特定命名空间或应用查看资源(本例中每个服务有独立命名空间)
节点信息展示
节点总体信息:
-
• 节点总数 -
• Pod 总数 -
• CPU 核数 -
• 总内存大小 -
• Spot 实例与按需实例占比 -
• 每日节点总成本
分配资源百分比
-
• 从 Pod 请求的 CPU -
• 从 Pod 请求的 内存 -
• Pod分配率
实际资源使用情况(节点级)
-
• 各节点 CPU/内存使用量 -
• 每个节点上的 Pods 数量占比(相对最大 Pods 数) -
• 节点创建 / 删除趋势(Karpenter 自动扩缩容行为) -
• 单个节点成本变化趋势 -
• EBS 磁盘使用百分比 -
• 网络输入/输出流量(字节/秒)
关于 Karpenter:
-
• controller_runtime_reconcile_errors_total:
总错误次数 -
• karpenter_provisioner_scheduling_duration_seconds:
Pod 创建的耗时 -
• karpenter_cloudprovider_errors_total:
云厂商相关的错误总数
创建可视化面板
新建一个面板,并设置主要参数:

Grafana 变量设置
我们需要两个变量:节点和命名空间
-
• Nodes:从 karpenter_nodes_allocatable中获取 -
• Namespaces:从 karpenter_pods_state中获取
先来创建第一个变量——node_name,启用 “All” 和 “多选” 功能:


创建第二个变量 ——$namespace:
为了仅从第一个过滤器中选中的 Nodes 中筛选 Namespaces,添加通过我们上面创建的 $node_name 的筛选功能,并使用正则表达式 =~(当选择多个节点时):

集群中的 WorkerNode 数量:
查询——对选中的节点使用 node_name=~"$node_name" 过滤条件:
count(sum(karpenter_nodes_allocatable{node_name=~"$node_name"}) by (node_name))
集群中的 Pod 数量:
查询——这里可以同时按 Nodes 和 Namespaces 进行过滤:
sum(karpenter_pods_state{node=~"$node_name", namespace=~"$namespace"})
所有节点的 CPU 核数:
部分资源会被系统或 DaemonSet 占用 —— 这些不会计入 karpenter_nodes_allocatable。
你可以用下面的查询验证:
sum(karpenter_nodes_system_overhead{resource_type="cpu"})因此,我们可以选择两种展示方式:
-
• 总资源数: karpenter_nodes_allocatable{resourcetype="cpu"}+karpenter_nodes_system_overhead{resourcetype="cpu"} -
• 实际可用于工作负载的资源:
-
karpenter_nodes_allocatable{resourcetype="cpu"}
这里我们希望看到的是总量,所以使用 sum:
sum(karpenter_nodes_allocatable{node_name=~"$node_name", resource_type="cpu"}) + sum(karpenter_nodes_system_overhead{node_name=~"$node_name", resource_type="cpu"})
总可用内存容量:
顺带一提:
-
• SI 标准:1 KB = 1000 字节 -
• IEC 标准:1 KiB = 1024 字节
但在这里我们就自己 /1024 ,统一使用 Kilobytes:
sum(sum(karpenter_nodes_allocatable{node_name=~"$node_name", resource_type="memory"}) + sum(karpenter_nodes_system_overhead{node_name=~"$node_name", resource_type="memory"})) / 1024
Spot 实例——占节点总数的百分比:
除了 Karpenter 自己创建的节点外,我还有一个在集群创建时就存在的 “默认” 节点,用于运行各种控制器。它目前也是 Spot 实例,所以我们也把它算进去。
公式如下:
spot nodes percent=all spot instances from karpenter +1default/ total number of nodes查询语句本身:
sum(count(sum(karpenter_nodes_allocatable{node_name=~"$node_name", nodepool!="", capacity_type="spot"}) by (node_name)) + 1) / count(sum(karpenter_nodes_allocatable{node_name=~"$node_name"}) by (node_name)) * 100
CPU 请求量——占总可分配 CPU 的百分比:
我们取自默认 Karpenter 面板的查询语句,稍作调整以适配我们的筛选条件:
sum(karpenter_nodes_total_pod_requests{node_name=~"$node_name", resource_type="cpu"}) / sum(karpenter_nodes_allocatable{node_name=~"$node_name", resource_type="cpu"}) 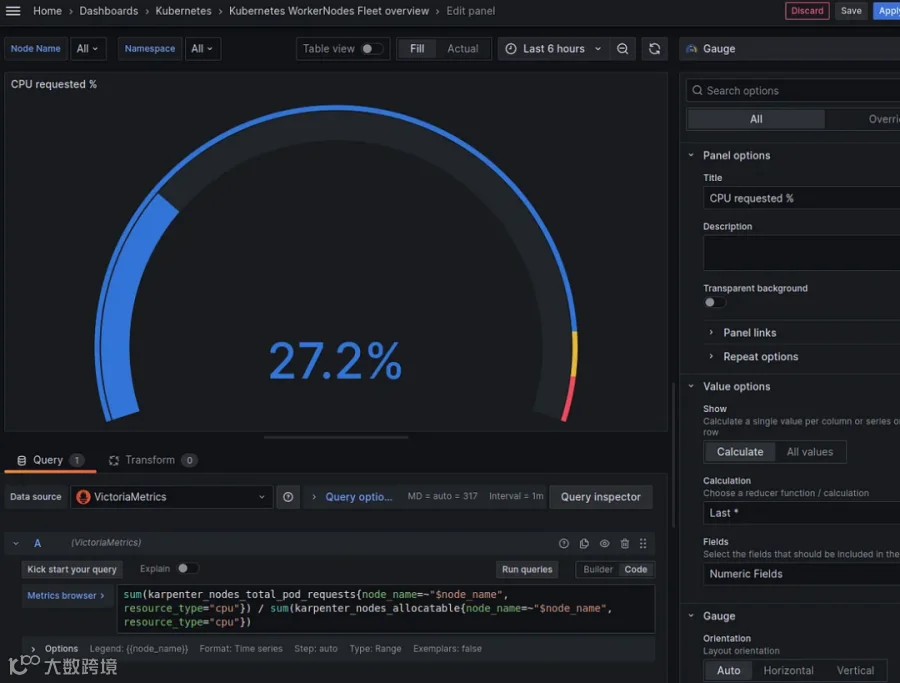
内存请求量——占总可分配内存的百分比:
同理:
sum(karpenter_nodes_total_pod_requests{node_name=~"$node_name", resource_type="memory"}) / sum(karpenter_nodes_allocatable{node_name=~"$node_name", resource_type="memory"}) 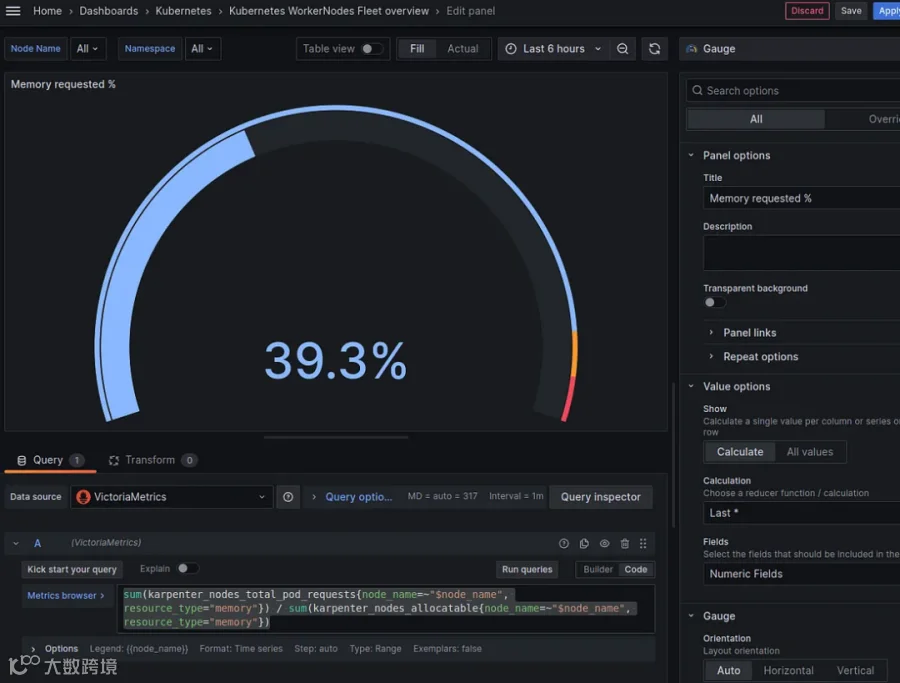
Pods 分配——占总可分配容量的百分比:
我们到底用了多少 Pod,占了总容量的多少:
sum(karpenter_pods_state{node=~"$node_name", namespace=~"$namespace"} / sum(karpenter_nodes_allocatable{node_name=~"$node_name", resource_type="pods"})) * 100
控制器错误:
controller_runtime_reconcile_errors_total 这个指标包含了 VictoriaMetrics 的控制器错误,所以我们用 {container!~".*victoria.*"}把它们排除掉:
sum(controller_runtime_reconcile_errors_total{container!~".*victoria.*"})
云厂商报错:
按每秒速率统计:
sum(rate(karpenter_cloudprovider_errors_total[15m]))
24小时节点成本—所有节点一天的费用:
这里的情况挺有意思的。
首先,AWS CloudWatch 有默认的计费指标,但我们项目用的是 AWS 额度(credits),那些指标是空的,没法用。
所以我们采用 Karpenter 自带的指标:karpenter_cloudprovider_instance_type_price_estimate
要展示服务器成本,首先需要选出每种正在使用的实例类型,然后计算每种类型的总费用和对应的节点数量。
现状如下:
-
• “默认”节点:Spot 类型,但不是 Karpenter 创建的,可以忽略 -
• Karpenter 创建的节点:既可能是 Spot 实例,也可能是按需实例,实例类型多样(如 t3.medium、c5.large 等)
第一步,需要统计每种实例类型的节点数量:
count(sum(karpenter_nodes_allocatable) by (node_name, instance_type,capacity_type)) by (instance_type, capacity_type)我们得到 4 个 Spot 节点,还有一个没有 capacity_type 标签的实例,因为它属于默认的节点组。

我们可以通过添加 {capacity_type!=""} 条件来排除这个默认节点——我们只有一个这样的非自动扩缩节点,可以安全忽略它,因为它只是用来运行 CriticalAddons 。
为了获得更完整的数据视图,建议扩大时间范围进行查询,因为期间还使用过t3.small 实例类型:

接下来,我们用 karpenter_cloudprovider_instance_type_price_estimate 这个指标,计算每种 instance_type 和 capacity_type 下所有实例的总成本。
查询语句大致长这样(多亏了 ChatGPT):
sum by (instance_type, capacity_type) (count(sum(karpenter_nodes_allocatable) by (node_name, instance_type, capacity_type)) by (instance_type, capacity_type)* on(instance_type, capacity_type) group_leftavg(karpenter_cloudprovider_instance_type_price_estimate) by (instance_type, capacity_type))
这里是整个查询的结构说明:
-
• 内层查询 : sum(karpenter_nodes_allocatable) by (node_name, instance_type, capacity_type):
计算每个node_name+instance_type+capacity_type组合下的所有 CPU、内存等资源总和。 -
• 外层查询: count(...) by (instance_type, capacity_type):
对内层结果进行计数,得到每种instance_type和capacity_type组合对应的 WorkerNodes 数量。 -
• 第二个查询: avg(karpenter_cloudprovider_instance_type_price_estimate) by (instance_type, capacity_type):
获取每种实例类型和容量类型的平均价格。 -
• 使用 on(instance_type, capacity_type):
将节点数量(第二个查询结果)与对应实例价格(第三个查询结果)按实例类型和容量类型匹配后相乘。 -
• 最外层查询: sum by (instance_type, capacity_type) (...):
对上述结果按实例类型和容量类型求和,得到每种组合的总费用。
最终效果就是下面这个图表:

那我们这儿有什么?
-
• 4 个 t3.medium和 2 个t3.small实例 -
• 所有 t3.medium每小时总成本是 0.074,所有 t3.small 是 0.017
想确认一下,手动算算,先从 t3.small 开始:
{instance_type="t3.small", capacity_type="spot"}算下来是 0.008:

然后是 t3.medium 的计算结果:
{instance_type="t3.medium", capacity_type="spot"}结果是 0.018:

总结一下:
-
• 4 个 t3.medium,每个 $0.018 /小时,总共就是 $0.072 /小时 -
• 2 个 t3.small,每个 $0.008 /小时,总共就是 $0.016 /小时
没错,完全正确!
接下来只要把它们整合起来,算出所有服务器 24 小时的总费用——用 avg() 取平均,再乘以 24 小时就行:
avg(sum by (instance_type, capacity_type) (count(sum(karpenter_nodes_allocatable{capacity_type!=""}) by (node_name, instance_type, capacity_type)) by (instance_type, capacity_type)* on(instance_type, capacity_type) group_leftavg(karpenter_cloudprovider_instance_type_price_estimate) by (instance_type, capacity_type))) * 24

最终,完整的查询大概长这样:

我们继续看图表部分。
每个节点的 CPU 使用百分比:
我们这次用的是 Node Exporter 的默认指标——node_cpu_seconds_total。
不过有个小坑:
这个指标的标签是 instance="10.0.32.185:9100" 这种形式,而不是像 Karpenter 的 node_name 或 node 标签(比如 karpenter_pods_state{node="ip-10-0-46-221.ec2.internal"})。
所以,为了让 node_cpu_seconds_total 这个指标可以配合我们现有的 $node_name 变量使用,我们需要新增一个变量:node_ip。
这个变量的来源是指标 kube_pod_info,我们通过其中的 node 标签进行过滤,用 $node_name 来选出我们在筛选器中选择的那些节点。

现在我们就可以用下面这个查询语句创建一个图表了:
100 * avg(1 - rate(node_cpu_seconds_total{instance=~"$node_ip:9100", mode="idle"}[5m])) by (instance)
因为在这个查询里,instance 返回的是像"10.0.38.127:9100"这种格式,而我们整个面板(包括 $node_name)都在用 "ip-10-0-38-127.ec2.internal"这种内部 DNS 名字格式。
如果不统一格式,后面比如加数据链接、跳转联动,就会出错或查不到数据。
所以,我们可以用 Prometheus 的 label_replace() 函数把 IP 地址格式转成 ip-...ec2.internal的形式:
100 * avg by (instance) (label_replace(rate(node_cpu_seconds_total{instance=~"$node_ip:9100", mode="idle"}[5m]),"instance","ip-${1}-${2}-${3}-${4}.ec2.internal","instance","(.*)\\.(.*)\\.(.*)\\.(.*):9100"))
这里,label_replace 接收了 4 个参数:
1️⃣进行转换的指标:
(这里是 rate(node_cpu_seconds_total) 的结果)
2️⃣进行替换的标签名:instance
3️⃣新的标签值格式:"ip-${1}-${2}-${3}-${4}.ec2.internal"
4️⃣从中提取数据的原始标签名:
同样是 instance
最后,我们描述了这个正则表达式:"(.*)\\.(.*)\\.(.*)\\.(.*):9100",它的作用是从像 10.0.38.127:9100 这样的 IP 地址中提取出每一段(每个八位组 / octet),然后将它们依次填入 ${1}-${2}-${3}-${4} 这些正则分组中。
因此,最终结果就会变成:ip-10-0-38-127.ec2.internal
现在我们就得到了一个图表,如下所示:

节点内存使用情况:
这里的操作也完全一样:
sum by (instance) (label_replace((1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100,"instance", "ip-${1}-${2}-${3}-${4}.ec2.internal", "instance", "(.*)\\.(.*)\\.(.*)\\.(.*):9100"))

Pods 占用率(按节点):
这部分我们得同时用到两个指标:karpenter_pods_state 和karpenter_nodes_allocatable,来算出 Pods 用掉的百分比:
(sum by (node) (kube_pod_info{node=~"$node_name", created_by_kind!="Job"})/sum by (node) (kube_node_status_allocatable{node=~"$node_name", resource="pods"})) * 100
或者,我们可以排除掉默认的节点 “ip-10–0–41–2.ec2.internal”,只显示 Karpenter 自己创建的节点。
方法是通过过滤 karpenter_nodes_allocatable{capacity_type!=""} 来实现——毕竟我们更关心的是 Karpenter 为应用创建的节点到底有多忙。
不过要注意,karpenter_nodes_allocatable 这个指标使用的是 node_name 标签,而之前用的两个指标是 node 标签,不一样。所以我们得用 label_replace 再来一波转换,把请求改成这样:
(sum by (node) (kube_pod_info{node=~"$node_name", created_by_kind!="Job"})/on(node) group_leftsum by (node) (kube_node_status_allocatable{node=~"$node_name", resource="pods"})) * 100and on(node)label_replace(karpenter_nodes_allocatable{capacity_type!=""}, "node", "$1", "node_name", "(.*)")
这里,在 and on(node) 里,我们用的是查询结果左边(sum by())中的node标签,和右边 karpenter_nodes_allocatable{capacity_type!=""} 里的节点列表做匹配。
也就是说,只选出那些同时出现在这两个集合里的节点,排除掉我们的“default”节点,只关注 Karpenter 创建的节点。
简单来说,就是先拿出第一个查询得到的节点,再从 karpenter_nodes_allocatable{capacity_type!=""} 里筛选出和它们匹配的节点,保证数据精准。

EBS 使用率(按节点):
这部分更简单直接:
sum(kubelet_volume_stats_used_bytes{instance=~"$node_name", namespace=~"$namespace"}) by (instance)/sum(kubelet_volume_stats_capacity_bytes{instance=~"$node_name", namespace=~"$namespace"}) by (instance)* 100
Karpenter 创建/终止的节点数:
要展示自动伸缩的动态,可以加一个图表,里面放两个查询:
increase(karpenter_nodes_created[1h])- increase(karpenter_nodes_terminated[1h])这里,increase() 函数用来查看一个小时内数值变化了多少:

想去掉那些“阶梯状”的突变,可以把结果再套一层 avg_over_time() 函数:

最终效果
把所有内容整合在一起后,整个面板就长成这样啦:

第四步:配置数据链接
最后一步就是给面板加上数据链接——也就是点某个节点,跳转到另一个专门展示该节点的详情面板。
这个目标面板的 URL 格式如下:
https://monitoring.ops.example.co/d/kube-node-overview/kubernetes-node-overview?var-node_name=ip-10-0-41-2.ec2.internal
其中,var-node_name=ip-10-0-41-2.ec2.internal 指定了显示节点的数据。

打开面板,找到“Data links”这一栏:

设置名字和链接地址——想看所有可用字段,按下 Ctrl+Space 即可,自动弹出:

__field 会从面板查询结果里的 labels.node 里取值,也就是说它会自动用对应节点的名字替代链接里的变量。

它会生成类似格式的链接:“https://monitoring.ops.example.co/d/kube-node-overview/kubernetes-node-overview?var-node_name=ip-10-0-38-110.ec2.internal”。
总结
在这篇文章中,我们从监控指标的收集、筛选,到 Grafana 面板的配置,最终构建了一个实用的 Karpenter 可视化监控面板,有助于我们实时了解 Kubernetes 以及公有云上资源的实际消耗情况,并提前识别出可能存在的问题,推动资源高效管理。
如果您也在使用 Karpenter,或者想要了解如何高效利用 Kubernetes 资源,欢迎扫描下方二维码,加入我们的技术交流群。
推荐阅读
全球知名自由职业平台Fiverr的Karpenter弹性伸缩实践
流量激增也不慌!纽约时报如何利用Karpenter+KEDA快速应对

项目介绍
Karpenter 于2021年11月推出并开源,是一款开源的Kubernetes集群自动扩缩容工具,专为优化 Kubernetes 集群的工作负载设计,旨在以灵活、高性能和简洁的方式实现节点的弹性扩展。今年9月已发布1.0版本。目前,Karpenter 已为全球超500家知名企业在生产环境中提供服务,包括阿迪达斯、Anthropic、Slack、Figma等。
Karpenter项目地址:
https://github.com/kubernetes-sigs/karpenter