
作者:Rajdeep Saha,AWS 首席解决方案架构师;
Praseeda Sathaye,AWS 容器与开源首席解决方案架构师
来源|CNCF
Karpenter 开源地址:
https://github.com/kubernetes-sigs/karpenter
引言
Karpenter[1] 是一个开源项目,旨在提供节点生命周期管理,以优化在 Kubernetes 集群上运行工作负载的效率和成本。AWS 于 2021 年创建并开源了 Karpenter,帮助用户自动选择、配置和扩展集群中的基础设施,为 Kubernetes 用户提供更大的灵活性,以充分利用不同云服务提供商的独特基础设施。2023 年,该项目进入 beta 阶段,Kubernetes 自动扩展特别兴趣小组(SIG)向云原生计算基金会(CNCF)贡献了该项目的供应商中立核心[2]。
2024 年,AWS 发布了 Karpenter 版本 1.0.0,标志着该项目成熟的最后一个里程碑。在此版本中,所有 Karpenter API 都将在未来的 1.0 次版本中继续使用,并且不会在修改方式上产生破坏性变化。
Karpenter 作为开源软件 (OSS) 提供,使用 Apache 2.0 许可证。它将 Kubernetes 应用程序感知和工作负载打包的通用逻辑与创建和运行 API 请求以启动或终止特定云厂商的计算资源的过程分开。
通过开发针对特定云提供商的集成,Karpenter 能够与不同云计算服务的 API 进行交互,使得 AWS、Azure、GCP 等各大云提供商能够在各自的环境中使用 Karpenter 的功能。2023 年,微软发布了 Karpenter Provider,使 Karpenter 能够在 Azure Kubernetes Service (AKS) 上运行。近期,阿里云的Provider即将发布,敬请关注。
如今,Karpenter 在 Kubernetes 社区中已获得广泛认可,各种组织和企业利用其功能来提高应用可用性、降低运维开销,并提高成本效率。
Karpenter 的工作原理
Karpenter 在 Kubernetes 集群中的任务是根据应用程序和 Kubernetes 的需求做出计算资源决策。它作为 Kubernetes Operator 构建,运行在 Kubernetes 集群中,管理集群计算基础设施。Karpenter 做出两种类型的决策:在需要时提供新的计算资源,以及在不再需要时撤销这些资源。
Karpenter 通过监控 Kubernetes 调度器标记为不可调度的 Pod,评估 Pod 请求的调度约束(资源请求、节点选择器、亲和性、容忍度及拓扑扩散约束),并根据 pod 的要求提供合适的节点。当节点不再需要时,Karpenter 会自动撤销它们。
此外,Karpenter 的工作负载整合功能能够主动识别并重新调度使用率低的工作负载,使其集中在一组更具成本效益的实例上。这可以通过在集群中重用现有实例或启动新的优化实例来实现,从而最大化资源利用率并减少运营成本。
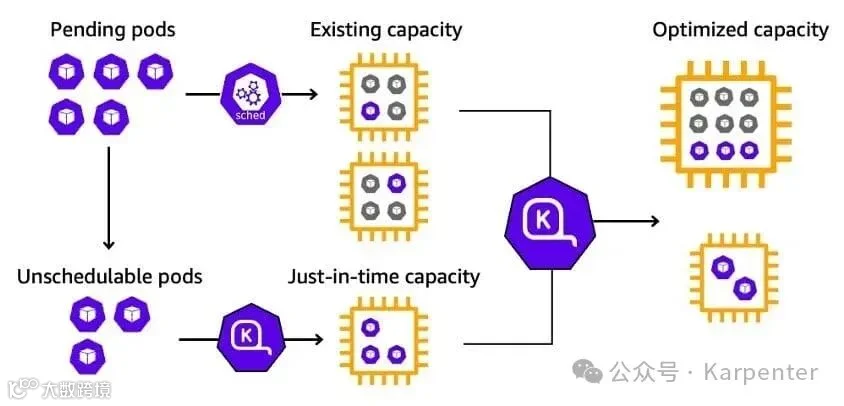
图 1:Karpenter 根据待处理的不可调度 Pod 配置节点
Karpenter 的扩展控制通过 Kubernetes 原生的 YAML 文件实现,具体来说是通过使用自定义的 Kubernetes 资源——NodePool 和 NodeClass 来管理。
NodePools 对 Karpenter 在 Kubernetes 集群中配置的节点设定约束。每个 NodePool 定义实例类型、可用区、架构(例如 AMD64 或 ARM64)、容量类型(竞价或按需)和适用于 NodePool 中所有节点的其他节点设置等要求。它还允许对 NodePool 可消耗的 CPU、内存和 GPU 等总资源设置限制。以下是 NodePool 配置的示例。
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: karpenter.k8s.aws/instance-category
operator: In
values: ["c","m","r","t"]
- key: "karpenter.k8s.aws/instance-family"
operator: In
values: ["m5","m5d","c5","c5d","c4","r4"]
- key: karpenter.k8s.aws/instance-size
operator: NotIn
values: ["nano","micro","small","medium"]
- key: topology.kubernetes.io/zone
operator: In
values: ["us-west-2a","us-west-2b"]
- key: kubernetes.io/arch
operator: In
values: ["amd64","arm64"]
limits:
cpu: 100
请参考 Karpenter 文档[3]以获取 NodePool 要求的完整字段列表。
以下是带有污点、用户定义标签和注释的 NodePool 示例,这些都会添加到 Karpenter 配置的所有节点上。
apiVersion: karpenter.sh/v1beta1
kind: NodePool
spec:
template:
metadata:
annotations:
application/name: "app-a"
labels:
team: team-a
spec:
taints:
- key: example.com/special-taint
value: "true"
effect: NoSchedule
apiVersion: apps/v1
kind: Deployment
metadata:
name:
spec: myapp
nodeSelector:
team: team-a
Karpenter 支持所有标准的 Kubernetes 调度约束,例如节点选择器、节点亲和性、污点/容忍度以及拓扑分布约束。这使得应用程序在调度 pod 到 Karpenter 提供的节点时,可以使用这些约束来满足特定需求。
Karpenter 中的 NodeClasses 允许你为 Kubernetes 集群中的节点配置云服务提供商特定的设置。每个 NodePool 都引用一个 NodeClass,以确定 Karpenter 所提供节点的具体配置。例如,在 AWS 的 EC2NodeClass 中,您可以指定如 AMI(Amazon Machine Image)系列、子网和安全组选择器、AWS 身份和访问管理(IAM)角色/实例配置文件、节点标签,以及各种 Kubelet 配置。在 Azure 中的 AKSNodeClass 中也可以进行类似的配置。
不仅仅是自动扩展
Karpenter 不仅仅是 Kubernetes 的高效集群自动扩展器。它还能优化计算成本,帮助升级和修补数据平面的工作节点,并通过与其他 CNCF 工具的结合,提供强大且具有探索性的应用场景。
成本优化
在上一节中,我们看到了 Karpenter 如何根据 pod 资源请求提供适当的 Worker 虚拟机(VM)。随着 Kubernetes 集群中工作负载的变化和扩展,有必要启动新实例,以确保它们拥有所需的计算资源。随着时间的推移,随着一些工作负载的缩减或从集群中移除,这些实例可能会未被充分利用。Karpenter 的工作负载整合可自动寻找机会,将这些工作负载重新安排到一组更具成本效益的实例上,无论这些实例是否已经在集群中还是需要启动。
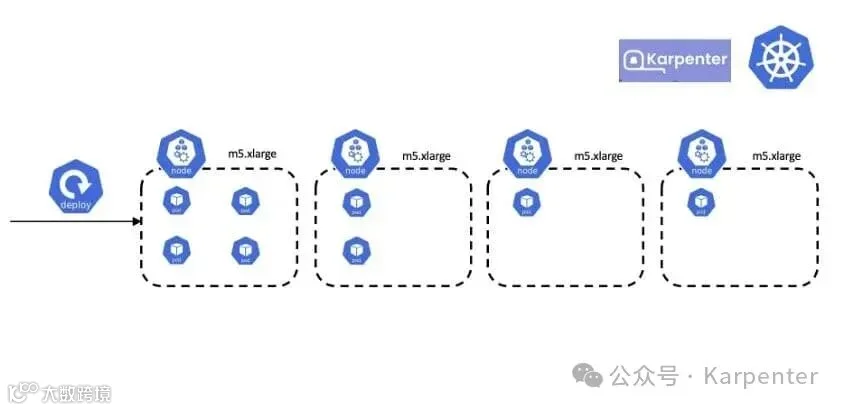
图 2:使用程度不同的 worker 节点
在上面的图中,第一个节点的使用率很高,而其他节点的使用率则不如预期。使用 Karpenter,你可以在 NodePool YAML 文件中启用整合功能:
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
Karpenter 始终在评估并努力降低集群成本。它会在满足 pod 的资源和调度约束的前提下,将工作负载整合到最少且成本最低的实例上。在上述场景中,Karpenter 会将最后两个节点上的 pod 迁移到第二个节点,并终止由此产生的空节点。
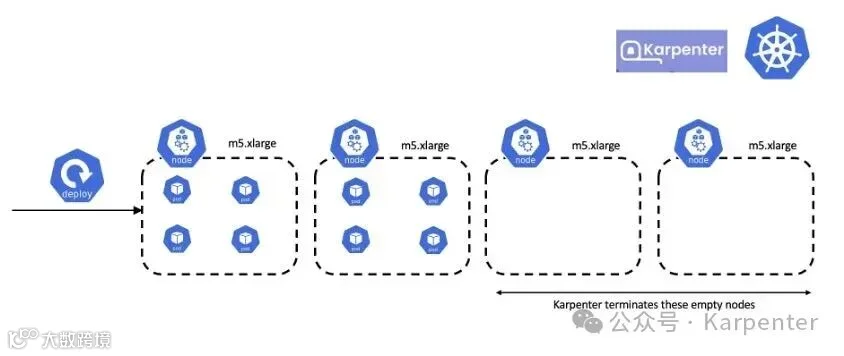
图 3:Karpenter 通过整合将 pod 分包到现有节点中
Karpenter 会根据调度的 pod 数量优先选择节点进行整合,优先处理 pod 数量较少的节点。对于有突发需求或可中断作业的工作负载,频繁的 pod 创建和删除(即 pod churn)可能会引起顾虑。Karpenter 提供了 consolidateAfter 设置,用于控制它在保持最佳容量和最小化节点波动方面的整合速度。用户可以以小时、分钟或秒为单位指定一个延迟时间,以确定 Karpenter 在响应 pod 增减之前启动整合操作的时间间隔。
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:
name: default
spec:
disruption:
consolidationPolicy: WhenEmptyOrUnderutilized
consolidateAfter: 1h
通过整合,Karpenter 还会调整工作节点的大小。例如,在以下情况下,如果 Karpenter 将 Pod 从第三个节点整合到第二个节点(m5.xlarge),则仍然会出现未充分利用的情况。Karpenter 会配置一个较小的节点(m5.large)并整合 Pod,从而实现更低的成本。
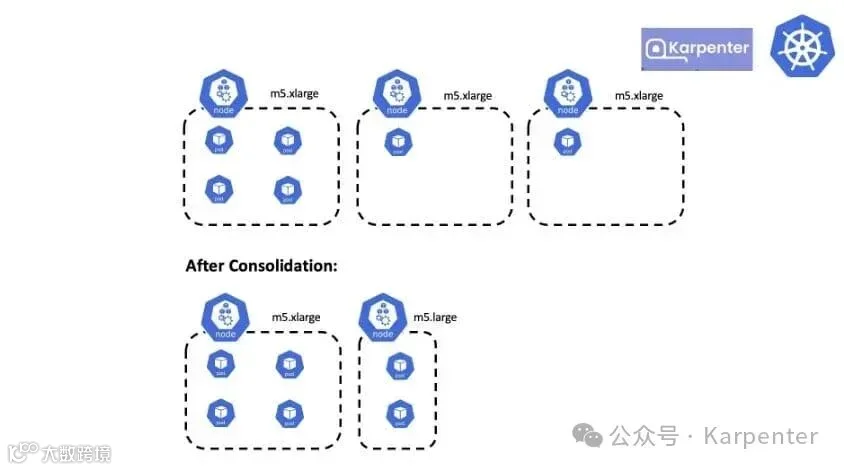
图 4:Karpenter 通过整合调整节点大小
有关整合的更多信息,请参考官方文档[4]。
工作节点的生命周期管理
Karpenter 确保你的工作节点始终使用最新的节点镜像/Amazon 机器镜像(AMI)。在 NodeClass YAML 中,你可以指定 AMI 系列和版本,如下所示:
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
amiSelectorTerms:
- alias: bottlerocket@latest
amiSelectorTerms 是 NodeClass 的必要字段,自版本 1.0 起引入了一个新术语 alias,它由 AMI 系列和版本(family@version)组成。如果 NodeClass 中存在别名,则 Karpenter 会选择云服务提供商为该系列提供的 AMI。通过这个新功能,用户还可以固定到特定版本的 AMI。对于 AWS,可以配置以下 Amazon Elastic Kubernetes Service(Amazon EKS)优化的 AMI 系列:al2、al2023、bottlerocket、windows2019 和 windows2022。
通过此 NodeClass 提供的所有节点都将使用最新的 Bottlerocket AMI。由于该别名使用了 @latest 版本,当云提供商为集群运行的 Kubernetes 版本发布新的优化 AMI 时,Karpenter 会在遵循 Kubernetes 调度约束的情况下自动更新工作节点的 AMI。工作节点将以滚动部署的方式进行升级。
如果集群升级到更高版本,Karpenter 会自动使用该新版本的最新 AMI 来升级工作节点,整个过程无需人工干预。这减少了管理开销,并确保您始终运行最新且最安全的 AMI。在预生产环境中,这种自动升级的方式非常适合用于测试,但在生产环境中建议对 AMI 版本有更多的控制。
另外,你也可以将工作节点固定到特定版本的 AMI,如下所示:
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
amiSelectorTerms:
- alias: bottlerocket@v1.20.3
在这种情况下,如果云提供商发布了新的 Bottlerocket AMI,Karpenter 不会漂移现有工作节点。
Karpenter 还支持自定义 AMI。您可以使用 amiSelectorTerms 中的已有标签、名称或 ID 字段来选择 AMI。在以下示例中,选择了 ID 为 ami-123 的 AMI 来提供节点。此外,amiFamily 为 Bottlerocket 时,会将预生成的用户数据注入到配置的节点中。
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
...
amiFamily: Bottlerocket
amiSelectorTerms:
要升级工作节点,只需更改 amiSelectorTerms 来选择不同的 AMI,节点将漂移并升级到指定的 AMI。
Karpenter 与其他 CNCF 项目协作
Karpenter 可以与其他 CNCF 项目结合使用,为常见的应用场景提供强大解决方案。一个典型的例子是将 Kubernetes 事件驱动自动扩展(KEDA)与 Karpenter 结合,以实现事件驱动的工作负载。通过 KEDA,您可以根据需要处理的事件数量来驱动 Kubernetes 中任意容器的扩展。一个常见的实现是,当消息进入队列时,自动扩展工作节点以容纳处理这些消息的 pod。
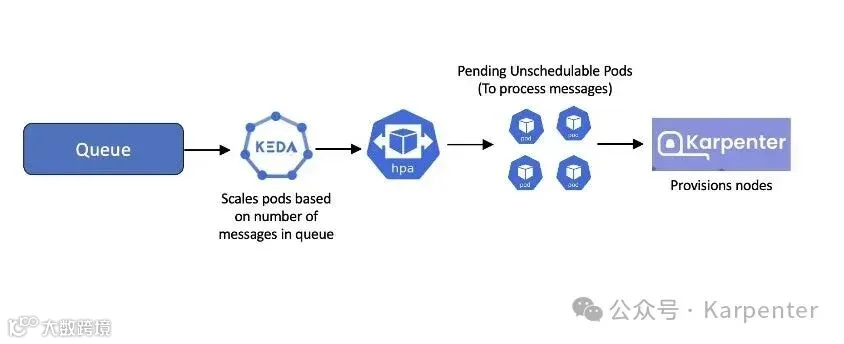
图 5:Karpenter 根据队列中的消息与 KEDA 配置节点
用户通常希望在非高峰时段减少工作节点的数量。KEDA 和 Karpenter 可以支持这种场景:
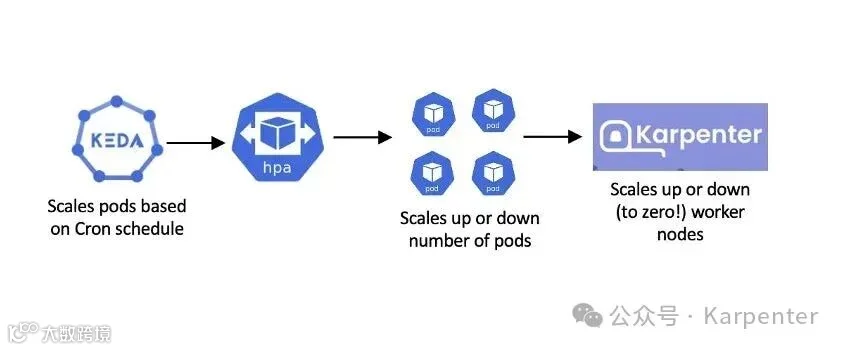
图 6:Karpenter 根据 KEDA 的 Cron 计划配置节点
Karpenter 可以与其他 CNCF 项目结合使用,如 Prometheus、Argo Workflows 和 Grafana,以实现多样的用例。请查看在 Kubecon EU 2024 上的演讲[5],了解 Argo Workflows 如何与 Karpenter 结合,从而完成从集群自动伸缩器的迁移。
采用 Karpenter
要开始使用 Karpenter,您可以参考官方的 Karpenter 入门指南[6],该指南提供了使用 eksctl 创建 EKS 集群并添加 Karpenter 的逐步操作。
或者,如果您更喜欢使用 Terraform,可以使用适用于 Terraform 的 Amazon EKS Blueprints[7],其中包含 Karpenter 模块,从而简化了在 EKS 集群中设置 Karpenter 的流程。
此外,还提供了其他 Kubernetes 发行版(如 AWS 上的 kOps[8])设置 Karpenter 的指南。如果您希望将现有的 EKS 集群从 Kubernetes Cluster Autoscaler 迁移到 Karpenter 以实现自动节点配置,可以参考此迁移指南以获取详细步骤。
展望未来
Karpenter 已经超越了作为自动弹性伸缩工具的角色,展示了其在云原生生态系统中的多功能性和更深层次的集成。Karpenter 不仅能够扩展工作节点,还能推动成本效益的提升,轻松管理生成式 AI 等多样化的工作负载,并精确地支持数据平面升级等操作。
展望未来,Karpenter 的可能性是无限的,尤其是在各组织探索开创性应用场景的过程中。我们才刚刚开始揭开 Karpenter 与其他 CNCF 项目结合后所能实现的潜力。Karpenter 在下一代基础设施中的贡献前景广阔,我们期待看到用户提出的创新且强大的应用场景,使云操作变得更加高效、可扩展且智能化。
为了塑造 Karpenter 的未来,欢迎你投票和评论[9]我们应当重点开发的功能,也欢迎扫描下方二维码加入中文技术社区。

项目介绍
Karpenter 于2021年11月推出并开源,是一款开源的Kubernetes集群自动扩展工具,专为优化 Kubernetes 集群的工作负载设计,旨在以灵活、高性能和简洁的方式实现节点的弹性扩展。今年9月已发布1.0版本。目前,Karpenter 已为全球超500家知名企业在生产环境中提供服务,包括阿迪达斯、Anthropic、Slack、Figma等。
引用链接
[1] Karpenter: https://github.com/kubernetes-sigs/karpenter[2] 贡献了该项目的供应商中立核心: https://github.com/kubernetes-sigs/karpenter[3] Karpenter 文档: https://karpenter.sh/docs/concepts/nodepools/[4] 官方文档: https://karpenter.sh/docs/concepts/disruption/[5] Kubecon EU 2024 上的演讲: https://www.youtube.com/watch?v=rq57liGu0H4[6] Karpenter 入门指南: https://karpenter.sh/docs/getting-started/getting-started-with-karpenter/[7] 适用于 Terraform 的 Amazon EKS Blueprints: https://aws-ia.github.io/terraform-aws-eks-blueprints/getting-started/[8] kOps: https://kops.sigs.k8s.io/operations/karpenter/[9] 投票和评论: https://github.com/kubernetes-sigs/karpenter