
点击上方卡片,关注「CloudPilot AI」
回复关键词【案例】
查看多邻国、Canva等名企的云端降本实践


导读
公司 GPU 不够用?AI 算力成本太高?
Kubernetes 动态资源分配(DRA)正是破解这些难题的下一代技术。
就像从“固定套餐”升级到“自助点餐”,DRA 为 GPU 资源提供了精细化的管理范式。它提供了一个清晰的“菜单”(设备属性)供您选择,但点餐后仍需等待厨房配餐(调度与分配)。
本文由 CNCF 基金会大使、前微软与 AWS 云架构专家 Janakiram MSV 撰写,深入浅出地解析:
🔹 如何利用 DRA 将现有GPU利用率提升数倍
🔹 避免“8卡服务器只能跑1个任务”的常见陷阱
🔹 最新Kubernetes 1.34版本的实际配置指南
无论您是技术决策者还是平台工程师,本文都将为您提供切实可行的GPU资源优化方案。
传统的 Kubernetes 资源管理机制最初是为 CPU、内存这类可计量的基础资源设计的。这套模式在通用计算场景下表现良好,但面对 GPU 和专用 AI 加速器等异构硬件时,就显得力不从心。Kubernetes 1.8 引入的设备插件框架试图弥补这一差距,但其架构存在根本性限制:
它只能上报"有多少个"可用设备,无法描述设备的具体属性(如型号、内存大小)。
每个设备只能被整个分配给一个容器,无法实现资源共享或分时复用。
缺乏参数化配置能力,无法根据工作负载需求动态设置设备(如 MIG 模式、功耗限制)。

01/
设备插件架构的局限性
Kubernetes 设备插件框架在核心架构上存在根本性局限,难以满足异构硬件资源的精细化管理需求,具体体现在以下四个层面:
资源抽象能力不足
框架采用基于整数的资源模型,将 GPU、加速卡等异构设备简化为无差别的可计数单元,无法表达设备间在型号、显存、算力等关键属性上的差异。这种过度简化的抽象方式,直接导致运维人员需依赖节点标签(node labels)等外部机制进行资源筛选,加剧了基础设施的耦合性,并显著增加运维复杂度。
资源共享与隔离机制缺失
设备仅支持整体分配,无法实现多个容器共享同一设备或按算力比例分配。这导致即使容器仅需少量算力,也必须独占整张GPU卡,造成高端硬件资源的严重利用率不足。
动态配置与调度能力薄弱
1.参数化缺失:工作负载无法在运行时动态设置设备参数(如MIG分区、功耗限制),致使类似功能必须通过厂商特定方案实现,丧失可移植性。
2.调度盲区:调度器无法感知设备拓扑(如NVLink连接、卡间亲和性)及集群全局资源状态,易作出次优调度决策,影响分布式训练等跨节点业务的性能。
3.健康监测简陋:设备故障后,关联Pod常陷入僵滞状态,需外部控制器介入恢复,可靠性存疑。
安全权限管控粗放
设备插件通常以高权限DaemonSet形式运行,享有过宽的主机访问权限,引入潜在安全风险。
综上,设备插件框架的根本矛盾在于:
其基于通用CPU/内存场景的简单设计,与现代AI、异构计算场景下硬件资源的复杂属性、动态配置需求及细粒度共享要求严重脱节。这个矛盾已逐渐成为支撑下一代云原生工作负载的架构瓶颈。

02/
DRA 架构是什么?
DRA架构对 Kubernetes 管理异构硬件资源的方式进行了彻底重构。
该架构在 resource.k8s.io API组中引入了一系列新 API 对象,通过协同工作机制实现资源的动态分配。
核心组件解析
ResourceClaim(资源声明)
🔹 通过通用表达式语言(CEL)描述对特定资源的详细需求,例如申请显存不小于16 GB 且具备特定计算能力的 GPU
🔹 支持手动创建实现资源共享,或通过 ResourceClaimTemplate 实现按 Pod 自动生成
🔹 完整生命周期管理:从初始请求、资源绑定到最终清理的全流程跟踪
DeviceClass(设备类别)
🔹 由平台管理员在安装 DRA 驱动时定义设备筛选类别
🔹 使用 CEL 表达式基于设备属性进行筛选,例如专为AI工作负载定义仅选择特定显存配置和计算架构的 GPU 类别
🔹 结构化参数设计使调度器能够直接理解设备需求,无需依赖黑盒化的厂商特定配置
ResourceSlice(资源切片)
🔹 由 DRA 驱动发布,实时反映各节点的可用资源状态
🔹 包含完整设备属性(内存容量、架构版本、厂商特定功能等)
🔹 为调度器提供动态资源视图,支持基于实时设备状态的智能调度决策
相比设备插件的静态资源上报机制,DRA通过这三层抽象实现了资源请求与物理设备的解耦,为 GPU、AI 加速器等异构硬件提供了真正的动态管理能力。

03/
从存储模型启发的范式转变
为从根本上解决设备插件框架的深层局限,Kubernetes 引入了动态资源分配(DRA)机制。
DRA的核心理念源自持久化存储领域成熟的动态供给模型——即通过 PersistentVolume(PV)和 PersistentVolumeClaim(PVC)管理存储资源的范式。
这一转变标志着 Kubernetes 对异构硬件资源的管理方式发生了根本性变革。
对于工程师而言,这种类比构建了极具启发性的认知模型:
DRA 中的 DeviceClass 类似于 StorageClass,用于定义可用资源的类型;而ResourceClaim则对应 PVC,表征用户对资源实例的申请。
这种设计实现了资源需求与底层实现的解耦,从而提供极大的灵活性。
下表通过对比 DRA 与存储模型的核心组件及其主要使用者角色,清晰展现其对应关系:
概念 |
动态资源分配 |
相关角色 |
存储抽象模型 |
相关角色 |
定义可用资源的“类型”或“类别” |
DeviceClass |
集群管理员、设备负责人 |
StorageClass |
集群管理员、存储专家 |
用户对资源实例的请求 |
ResourceClaim、ResourceClaimTemplate |
工作负载运维者 |
PersistentVolumeClaim |
开发者、应用运维者 |
代表集群中实际可用的资源 |
ResourceSlice |
DRA 驱动(设备负责人) |
PersistentVolume |
集群管理员、存储专家 |

04/
DRA 如何革新资源分配流程
DRA 的技术工作流程充分展现了其相对于传统方法的优势。
当用户创建带有 ResourceClaim 要求的 Pod 时,调度器会立即通过 DynamicResources 插件开始分析这些资源声明。
它会查询集群中的所有 ResourceSlice,寻找符合 CEL 选择条件的设备。复杂的 CEL 表达式可以同时评估多个属性,例如要求设备同时满足最小内存要求和特定架构特性。
一旦识别到合适设备,调度器将基于集群整体优化目标选择最优的节点与设备组合。分配细节会直接写入 ResourceClaim 状态中,无需外部驱动参与调度决策。
这种方式使调度器能够并行处理多个 Pod 的资源分配,相比设备插件方案显著提升了调度吞吐量。
值得一提的是,这种精细化的资源调度能力可以与 CloudPilot AI 的 Workload Autoscaler 形成完美互补。当 DRA 确保 GPU 资源被合理分配时,CloudPilot AI 就像一个永不疲倦的 SRE,通过机器学习持续观察每个 Pod 的真实资源消耗,动态推荐最优的 Requests 值,在提升资源利用率的同时保证应用稳定性。
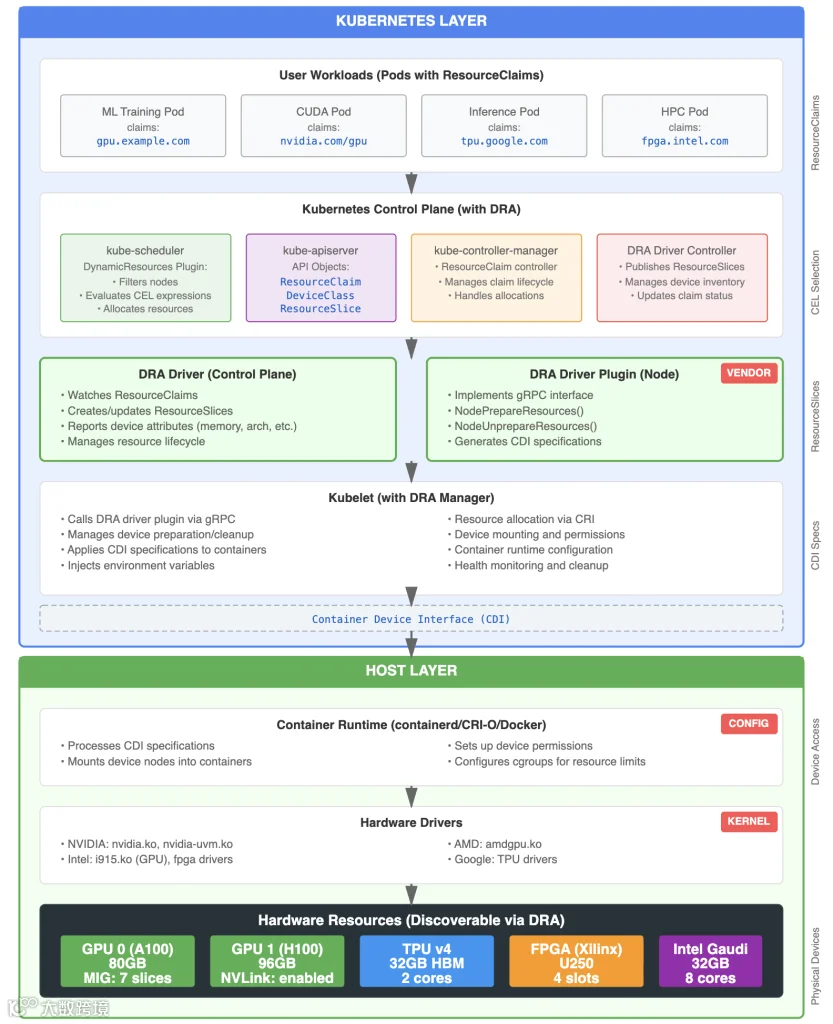
当 Pod 完成节点绑定后,kubelet 中的 DRA 管理器将接管本地资源管理。
它会调用相应 DRA 驱动插件的 NodePrepareResourcesgRPC 方法。驱动此时会完成硬件设备的准备工作,并生成容器设备接口规范,用于配置容器对资源的访问权限。
当 Pod 终止时,kubelet 将调用 NodeUnprepareResources方法进行资源清理与释放,确保资源可被后续分配复用。DRA 驱动采用双组件架构,实现了控制平面与节点级操作的解耦:
🔹控制端组件:集中运行,负责 ResourceSlice 的创建与更新,监听 ResourceClaim 变更并管理资源生命周期
🔹节点端组件:以 DaemonSet 形式运行于各节点,通过 gRPC 接口实现设备的准备与清理操作
这种组件分离的架构相比单体式设备插件方案,具备更清晰的边界定义和更强的可扩展性。

05/
DRA的功能状态与未来规划
DRA 目前处于 Beta 阶段,多项功能由特性门控管理。其核心功能自 Kubernetes 1.32 版本开始提供,另包含可分拆设备、设备污点与容忍度、备选设备优先级列表等 Alpha 功能,这些能力正在积极开发测试中,为正式发布做准备。
DRA 要完全成熟仍面临若干技术挑战:
🔹 需挂载后才可用的网络附加设备需要特殊支持;
🔹 驱动实现复杂度高于传统设备插件,对厂商存在学习门槛;
🔹 大规模设备环境下 ResourceSlice 可能面临扩展性压力。
社区正通过增强测试和性能优化积极解决这些问题。
最新发布的 Kubernetes 1.34 版本带来多项重要增强:
🔹 DRA 扩展资源桥接器支持从现有设备插件平滑迁移;
🔹 设备绑定状态机制提供基于优先级的就绪检查;
🔹 可消费容量功能支持更精细的共享模型;
🔹 原生健康监测将设备状态直接集成到 Kubernetes 资源模型。

06/
评估与采用 DRA 的最佳实践
建议各组织立即启动针对特定工作负载的动态资源分配(DRA)技术评估。
该技术能为不同场景带来显著价值:
对于运行 AI/ML 工作负载的平台团队,其 GPU 共享与动态分配能力可产生立竿见影的收益;
在高性能计算环境中,DRA 能够有效满足复杂的设备拓扑管理与跨设备依赖调度需求;
而在网络功能虚拟化场景中,它则可实现更精细化的网络资源管理。
从现有设备插件迁移至 DRA 架构虽需周密规划,但将带来显著的长期价值。
建议企业采取分阶段推进策略:
首先应搭建包含 DRA Beta 功能的测试环境,以积累运维实践经验;
同时需为开发团队提供培训,重点掌握结构化参数模型和基于 CEL 的设备选择机制;
此外,还需预先评估硬件供应商对关键设备的 DRA 驱动支持情况。

07/
总 结
总体而言,动态资源分配(DRA)代表了 Kubernetes 异构硬件管理的未来方向。
该技术从根源上解决了长期制约资源利用率和工作负载灵活性的架构瓶颈。凭借强大的生态支持与清晰的发展路径,DRA 有望成为云原生环境下管理 GPU、加速器等专用资源的高效实践方案。
然而,要充分发挥 DRA 的潜力,仅仅拥有精准的"调度能力"是不够的,更需要一个能够自主运作的" SRE 代理"。
作为基于 Karpenter 的智能成本优化方案,CloudPilot AI通过机器学习技术构建了全自动的云成本优化体系。在 DRA 实现 GPU 资源精细分配的基础上,CloudPilot AI 能够无缝衔接并深化优化效果:
🔹 其智能算法持续监控工作负载的真实资源消耗,确保每个 DRA 资源声明都设定在最优区间
🔹 同时基于深度优化的资源需求,从超过 800 种实例类型中智能选择最佳规格,并利用 45 分钟前预测 Spot 中断的能力,确保工作负载的稳定性
这意味着,企业无需投入额外预算组建专家团队,即可通过这个5分钟即可上手的解决方案,实现平均45%的云成本节约。
通过将 DRA 的精细调度能力与 CloudPilot AI 的自主优化能力相结合,企业不仅能最大化 GPU 资源利用率,更能将云原生基础设施转化为稳定、高效且成本可控的核心竞争力,从而真正专注于业务创新与迭代。
扫描文末二维码联系小助手,即可获得 CloudPilot AI 抢先体验特权!

推荐阅读
美股 SaaS 巨头如何用 Karpenter 节省 1/4 的 EC2 成本
公司介绍
CloudPilot AI,Your SRE Agent。致力于通过智能化、自动化的云资源调度和编排技术,数分钟即可降低 80% Kubernetes 成本。实现云基础设施的预测性优化与稳定性保障,帮助企业最大程度减少资源浪费。
我们秉持“让客户在云中花费的每一分钱都物超所值”的使命,已为数百家全球顶尖科技公司提供服务,累计为客户节省超过千万美金,平均节省67%。
目前,开源K8s弹性伸缩器 Karpenter 已为全球超500家知名企业在生产环境中提供服务,包括阿迪达斯、Anthropic、Slack、Figma等。选择CloudPilot AI,让每一笔支出都更智慧。
免费试用,2步5分钟,降低50%云成本:
cloudpilot.ai