
4月18日,国内AI圈发生两件大事:
DeepSeek 首次开启外部融资,目标估值≥100亿美元;
阿里千问同日开源 Qwen3.6-35B-A3B,30亿激活参数实现编程能力SOTA,华为昇腾极速适配。
GPT-6 发布一周,200万Token正在悄悄改变开发者的代码工作流。
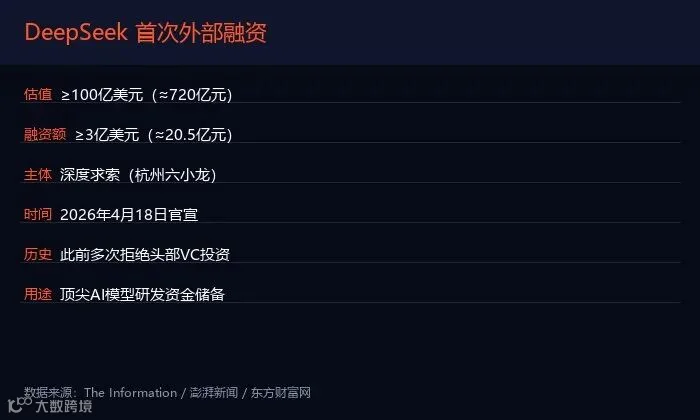 DeepSeek 融资关键数据 | cDesgin-天渊
DeepSeek 融资关键数据 | cDesgin-天渊
一、DeepSeek 首次外部融资:估值100亿美元,AI"独角兽"变"超级独角兽"
4月18日,多家媒体报道:深度求索(DeepSeek)正在开启首次外部融资,目标估值不低于100亿美元(≈720亿元人民币),拟筹集至少3亿美元(≈20.5亿元)。澎湃新闻记者也从多位创投圈人士处证实了这一消息。
 DeepSeek 全链路国产化 | 来源:今日头条
DeepSeek 全链路国产化 | 来源:今日头条
DeepSeek 是杭州"六小龙"之一,2025年凭借 V3 和 R2 两款模型在海外AI圈掀起巨浪,Chatbot Arena 榜单一度登顶。不同于国内大多数AI公司背后站着 BAT 等巨头,DeepSeek 此前已多次拒绝头部风投机构的投资邀约,选择纯自有资金发展。
-
目标估值:≥100亿美元,跻身全球AI超级独角兽行列 -
融资规模:≥3亿美元(≈20.5亿元),用于充实研发资金储备 -
战略意义:从"拒绝投资"到"主动融资",标志着商业化进入新阶段 -
资金用途:将加速下一代模型的研发,应对成本日益高涨的AI军备竞争 -
行业背景:阿里、字节、百度同期也在密集融资,AI进入"资金密集战"阶段
 DeepSeek 融资报道 | 来源:澎湃新闻 / 东方财富
DeepSeek 融资报道 | 来源:澎湃新闻 / 东方财富
二、阿里千问开源 Qwen3.6-35B-A3B:30亿参数,编程能力SOTA
就在 DeepSeek 宣布融资的同一天(4月16日),阿里通义千问团队正式开源了 Qwen3.6 系列首款模型——Qwen3.6-35B-A3B。这是继 Qwen3.5 之后最受开发者期待的一次更新。
 Qwen3.6 核心参数对比 | cDesgin-天渊
Qwen3.6 核心参数对比 | cDesgin-天渊
-
稀疏 MoE 架构:总参数350亿,推理时仅激活30亿,轻量高效 -
Agentic Coding:智能编码能力大幅超越前代 Qwen3.5-35B-A3B,达全球SOTA水准 -
推理速度:较前代提升 35倍,能耗降低 40% -
上下文:原生支持长上下文,适配复杂代码库分析任务 -
芯片适配:华为昇腾 950PR 极速适配,国产算力开箱即用 -
开源许可:Apache 2.0,完全开源,可商用
斯坦福大学 HAI 研究所同天发布的《2026年人工智能指数报告》也指出:阿里千问以11个大模型的数量,位列全球第三,仅次于 OpenAI(19个)和 Anthropic,成为中国AI开源生态的标杆力量。
三、GPT-6发布一周:200万Token正在改变开发者的代码工作流
4月14日,OpenAI 发布 GPT-6(代号 Spud),参数规模5-6万亿,上下文窗口200万Token。发布一周后,开发者社区的实际体验正在验证它的真实威力。
- 一次读完整套代码库:
200万Token≈150万字,相当于可以一次性读完 K8s 完整源码或《三体》全集,工程师无需再手动分段喂给AI - 中间段召回率提升:
相比 GPT-5.4 的47%,GPT-6在"Lost in the Middle"问题上有显著改善,长文档信息召回率达98%+ - 国产替代加速:
面对 GPT-6 的压力,DeepSeek V4(4月下旬)、千问3.6全面开源,国产模型正形成合围之势
总结:AI江湖,一周之内发生了什么?
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
作者:cDesgin-天渊 · 2026年4月20日