
6月2日,微软在Build 2026开发者大会上做了一件大事:一口气发布了7款完全自研的AI模型。这不是合作,不是授权,是微软自己从零训练的。业界给这个动作起了个名字——"去OpenAI化"。7年独家合作,终于画上了句号。
7年"婚姻"终于结束了
先说背景。
2019年,微软给OpenAI投了10亿美元,从此成为OpenAI最大的金主和独家合作伙伴。Azure云是OpenAI的独家算力提供商,微软的产品(Office、Bing、Copilot)全都用OpenAI的模型。
这种关系持续了7年。
但2026年4月,双方正式结束了独家合作协议。新协议允许微软开发自研AI应用,不必再和OpenAI共享技术。
然后,微软在Build 2026上甩出了7款自研模型。
MAI家族:七兄弟各司其职
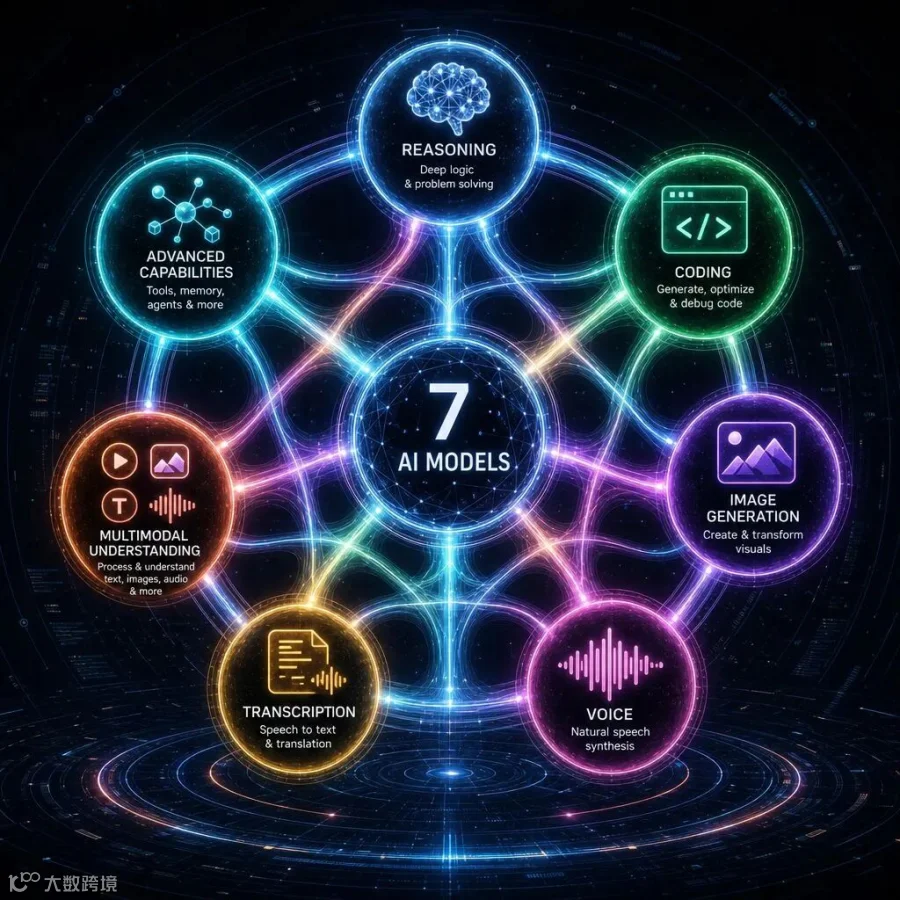
这7款模型统称MAI系列,覆盖了AI的核心场景:
1. MAI-Thinking-1:旗舰推理模型,350亿活跃参数(MoE架构),总参数约1万亿,256K上下文窗口。在SWE-Bench Pro编程基准测试中表现与Claude Opus 4.6持平。完全从零训练,零蒸馏。
2. MAI-Code-1-Flash:编程模型,50亿参数,专为GitHub Copilot和VS Code定制。性能对标Haiku,但成本更低。
3. MAI-Image-2.5:图像生成模型,在Arena排行榜上排名第二,超越了Gemini 3 Pro。
4. MAI-Image-2.5-Flash:图像生成的轻量版,速度更快。
5. MAI-Transcribe-1.5:语音转文字,支持43种语言,速度是竞品的5倍。
6. MAI-Voice-2:语音合成,支持15种语言,语调更自然。
7. MAI-Voice-2-Flash:语音合成的轻量版。
为什么说这是"断奶宣言"?
"所有7款模型均为微软内部训练,非OpenAI模型。"
微软这次的表态非常明确:
- 完全自研
:从零训练,不依赖OpenAI的任何技术 - 干净数据
:训练数据不含任何第三方AI生成内容,对医疗、金融等监管行业有吸引力 - 零蒸馏
:没有用OpenAI或Anthropic的模型输出来训练自己的模型 - 端到端自有
:后续的Project Polaris运行在微软自研的Maia AI加速器上,从硅片到模型全栈自研
这意味着什么?微软不再满足于当OpenAI的"代理商"了。它要成为独立的AI巨头。
MAI-Thinking-1:350亿参数打1万亿的仗
最值得关注的是MAI-Thinking-1。
它采用MoE(混合专家)架构,350亿活跃参数,总参数约1万亿。每次推理只激活一小部分"专家"网络,实际资源占用远小于同等能力的Dense模型。
关键数据:
-
SWE-Bench Pro:与Claude Opus 4.6持平 -
AIME数学推理:准确率超过94% -
盲测评估:用户偏好与Claude Sonnet 4.6持平 -
上下文窗口:256K tokens
微软给它的定位很聪明:不追求绝对SOTA,而是用更低的成本覆盖企业级高频推理场景。
蝴蝶效应:AI行业格局巨变
微软的"去OpenAI化"影响深远:
- OpenAI失去最大客户
:微软是OpenAI最大的云服务客户,如果微软转向自研模型,OpenAI的营收将大幅缩水 - GitHub Copilot换引擎
:MAI-Code-1-Flash将在2026年8月取代GPT-4 Turbo,成为GitHub Copilot的默认引擎 - 企业客户有更多选择
:微软的MAI模型可以直接通过Azure调用,企业不需要再通过OpenAI的API - AI模型价格战升级
:微软的规模优势可能让MAI模型的价格远低于OpenAI和Anthropic
有人说,微软这是在"卸磨杀驴"——用OpenAI的技术完成了AI转型,然后自己做模型。但从商业角度看,这完全是理性的选择。当你每年给OpenAI支付几十亿美元的API费用,而你自己有能力训练同等水平的模型时,"去OpenAI化"只是时间问题。微软用了7年时间完成了从"投资者"到"竞争者"的转变。这可能是AI行业历史上最成功的"抄作业"。
作者:cDesgin-天渊 | 发布日期:2026年6月12日