
这是姚顺雨加入腾讯混元担任首席AI科学家后,其团队首次发布研究成果,也是腾讯混元技术博客首次公开。
“
姚顺雨的判断
2025年4月,姚顺雨在博文《The Second Half》中提出,AI发展的下半场是如何定义正确的问题,如何评估真正的进步。
而现在,混元团队定义的问题是:模型如何从上下文中学习到预训练阶段不存在的新知识并正确运用;评估问题的方式是:CL-bench(下文会详细介绍)。
官网链接:Tencent HY Research
“
模型当前的瓶颈
现在的SOTA模型虽然跑赢了benchmark,但却处理不了真实世界的简单任务。
人类可以随时调整,从实战中学习——即使不知道游戏的操作方式,却能在短时间内摸索出闯关的方式。人类可以实时地从眼前的context中学习。模型却不行。
模型目前的智能来源为预训练和强化学习,而对于上下文的理解、自主学习的能力却不具备,这背后的原因是什么?
可以这样理解,模型像应试教育的考生,学了书本上什么知识(预训练),模型可以根据已有的记忆去完成相应的考试(推理),可是对于没有直接给到的知识,模型并不具备基于全新上下文的 “实时学习迁移能力”。其迁移能力的边界,完全受限于预训练数据的覆盖范围,无法突破 “课本知识” 的范畴去吸收新规则、新规律。
大模型只能依赖预训练阶段的静态记忆,而人可以实时根据现场情况完成任务。
“
解决方法:CL-bench
针对当前的模型瓶颈,姚顺雨团队提出建立新的评测标准:CL-bench。即模型必须从上下文中学习到预训练阶段不存在的新知识,并正确应用。
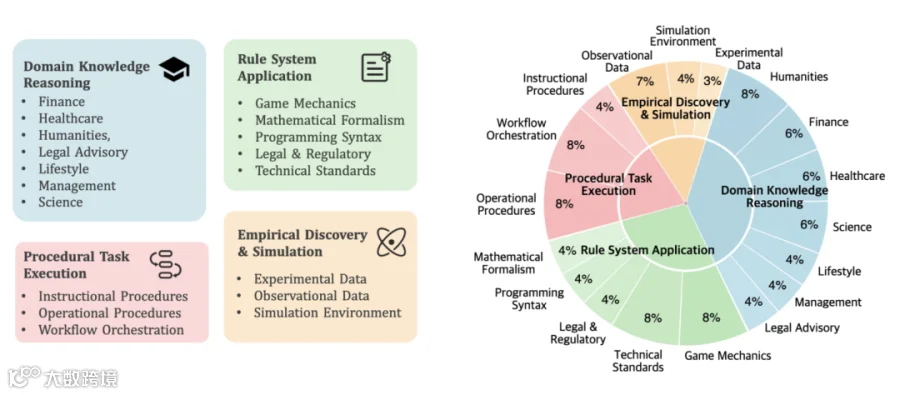
CL-bench包含由专家制作的500个复杂上下文、1899个任务和31607个验证标准。
其对模型的要求为:要求模型必须在解决每个任务都从上下文中学习到模型预训练中不存在的新知识,并正确应用。
具体内容如下:
领域知识推理: context 中提供特定的领域知识(例如 虚构的法律体系、创新的金融工具或小众专业知识)。模型需要利用这些知识来推理并解决具体问题。
规则系统应用:context 中提供新定义的正式系统(例如 新的游戏机制、数学形式体系、编程语法或技术标准)。模型必须理解并应用这些规则来执行任务。
程序性任务执行:context 中提供复杂的过程系统(例如 工作流、产品手册和操作指南)。模型必须理解并应用这些程序性信息来完成任务。
经验发现与模拟:context 中提供复杂系统内的实验数据、观测记录或模拟环境。与前几类涉及演绎推理不同,这一类专注于归纳推理,也是最具挑战性的。模型必须从数据中发现潜在的定律或结论,并应用它们来解决任务。
CL-bench 围绕一个简单但严格的设计原则构建:每个任务都必须要求从 context 中学习新知识。 CL-bench 中的每个 context 都是完全自包含(Self-contained)的。解决任务所需的所有信息都显式地提供在 context 本身之中:不需要外部检索,也不允许隐藏假设。
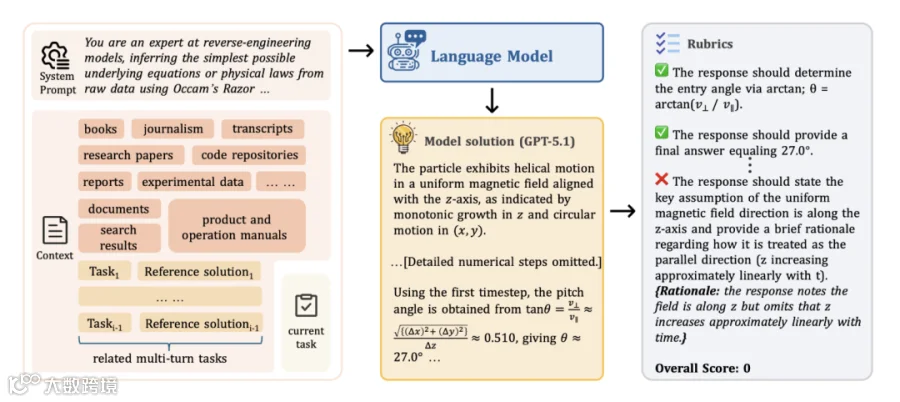
为了确保性能真正反映 context 学习,而不是记忆或数据泄露,CL-bench 采用了无污染设(Contamination-free):
虚构创作: 专家创作完全虚构的内容,例如为虚构国家设计一套完整的法律体系(包括新颖的判例和法律原则),或创建具有独特语法和语义的新编程语言。
现有内容的修改: 专家修改现实世界的内容以创建变体,例如更改历史事件、改变科学和数学定义,或修改技术文档和标准。
整合小众和新兴内容: 专家纳入了在预训练数据集中代表性极低的小众或近期新兴内容,如前沿研究发现、新发布的产品手册或技术文档,以及来自专门领域的特定知识。
在不提供任何 context 的情况下,最先进的模型 GPT-5.1 (High) 仅能解决 不到 1% 的任务。这有力地证明了数据是无污染的,模型若不从 context 中学习,几乎完全无法解决这些任务。
“
模型技术范式
OpenAI作为人工智能领域的领军者,其发展路径清晰地体现了两个关键的技术范式转变,它们共同构成了现代大语言模型能力跃升的基石。
1.预训练范式(Pre-training Paradigm)
核心思想:模型首先在互联网级别的海量文本数据上进行无监督学习,其核心任务是预测下一个词。通过这个过程,模型能够内化语言规律和世界知识,获得强大的通用能力。
代表模型:GPT系列(从GPT-1到GPT-3/4)
关键成果:证明了缩放定律的有效性——即增加模型参数、数据量和计算资源,可以稳定地提升模型性能。这带来了从专用AI到通用AI的转变,使单一模型能处理多种不同任务。
2.推理范式(Reasoning Paradigm)
核心思想:不再单纯追求训练阶段的规模扩大,而是增加模型在回答每个问题时的“思考”计算量。模型在生成最终答案前,会进行更深入、更耗时的推理过程,如生成并验证多种解题路径。
代表模型:o系列模型(如o1, o3)
关键成果:开辟了性能提升的新维度。用户可以为更复杂的问题支付更高的单次推理成本,以获得远超传统模型的答案质量。这使得AI在数学、编程等高难度任务上达到甚至超越了专家级人类水平。
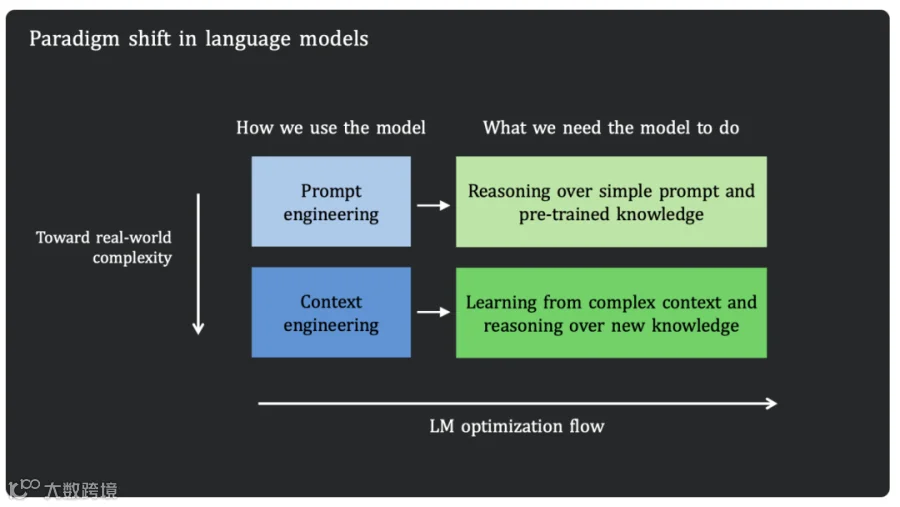
那么2026年呢?下一个模型技术范式会是什么?
CL-bench指向了一个可能的新方向,Context Learning。
让我们共同期待,2026的更多可能性!