

物流行业在近几年开始快速发展,据中国电子商务研究中心(100EC.CN)监测 数据显示,2016年中国快递企业营业收入为 4005 亿元,与 2015 年的2769.6 亿元相比,同比增长 44.6%。可见物流行业的发展速度并非一般。
然而,物流企业为取得可观收益而高兴时,也应看到物流成本居高不下的现状。2016 年我国社会物流总费用 11.1 万亿元,同比上年增长 2.9%,2016 年社会物流总费用与GDP 的比率为 14.9%。其中物流成本居高不下的重要原因之一,是企业不重视需求预测或者预测不科学不准确,导致供需不平衡,企业存在缺货成本或库存成本。因此,科学准确的商品需求预测与库存优化具有很大意义。
问题描述
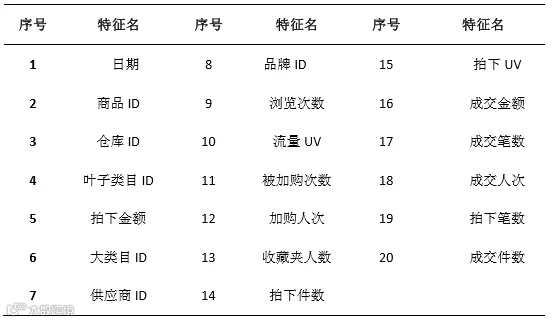
商品特征整理
通过长风大数据网站的数据平台获取了某电商平台的智能分仓数据,考虑 到研究需要,本文选取了若干个与需求指标具有较大相关性的特征作为研究对象,如下表:
表-商品特征
虽然采用的数据库中有 1000 种商品,但考虑到商品需求研究方法同一,因此本文随机抽取了编号为 3435 的商品作为样本,针对其交易时间轴为 2014 年 9月 29 日至 2015 年 12 月 27 日的海量交易数据进行研究。同时,以周为单位时间跨度,通过多种预测模型和库存优化方法比较,预测出 2015 年 12 月 28 日至 2015年 1 月 3 日,即一周的成交件数及订购数量。以 7 天为一个时间窗口,用 2014年9 月 29 日到 2015 年 12 月 27 日,445 天,65 周的数据构成 65 个样本基础点,采用多元回归模型和 BP 神经模型分别预测 2015 年12 月 28 日至 2015 年 1 月 3日即第 66 周的需求量,并以此进行库存优化。
商品特征分析
1、同一标度下特征分析
为了便于在同一标度下观察,选取“拍下金额”、“拍下件数”、“拍下 UV”、 “拍下笔数”这四个同一标度的特征进行观察,利用 PMT 得到这四个特征的走势图,结果表明,这四个特征同一标度下的特征走势趋于一致。
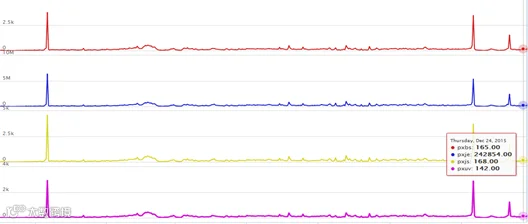
图-商品同一标度特征走势图
注:图中曲线依次为拍下笔数、拍下金额、拍下件数、拍下 UV
2、不同标度下特征分析
本次研究目标函数是需求量,即成交件数。所以分别选取“被加购次数”、“收藏夹人数”、“浏览次数”等和“成交件数”一一进行特征走势对比观察。如成交件数与被加购次数走势图所示,各特征向量的波动走势和成交件数的波动走势是几乎吻合的,由此说明各特征异常值与成交件数同向变动,证明这些特征与成交件数存在关联,同 时在2014 年 11 月 11 日、12 月 12 日、2015 年 6 月 18 日、11 月 11 日和 12 月12 日的数据中发现异常值。
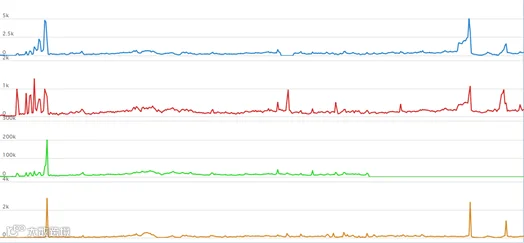
图-成交件数与被加购次数走势图
注:图中曲线依次为被加购次数、收藏夹次数、浏览次数、成交件数
3、总特征与成交件数特征分析
特征加和公式:
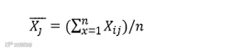
其中X̅ j 代表第j天的总特征,Xij代表第i特征第j天的值,n=13即研究指标的13个特征。利用公式把每一天的所有商品特征分别加总,形成 455 天的商品总特征,再利用 PMT 对计算出来的总特征值与成交件数进行对比分析,得到该商品总体多特征走势,如总特征与成交件数走势图 所示。结果表明总特征值与成交件数的波动走势趋同,证明总特征和成交件数存在关联性。
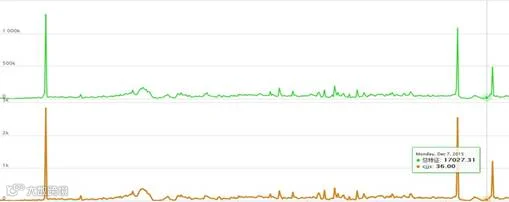
图-总特征与成交件数走势图
注:图中曲线依次为总特征、成交件数
在本次需求预测中,将“成交件数”定义为预测目标,即因变量。并将“拍 下笔数”、“拍下金额”、“浏览次数”等其余的 12 个研究指标特征定义为自变量。考虑到 12 个特征对“成交件数”的影响程度不一,以及特征间存在多重共线性,需要降维处理,以确定影响需求的关键因素。方法如下:
第一步:利用 PMT 软件里面的 Correlations 工具,将“成交件数”与其他的12 个特征进行成对的相关性分析,相关性大于 0.97 的特征视与“成交件数”近似完全相关[2],即两者同属于内生变量。分析结果表明“成交笔数”、“成交金额”、“成交人次”、“拍下件数”、“拍下金额”和“成交件数”共同构成内生变量集(如内生变量集的相关性列表)。考虑到多重共线性对预测的影响,故进行剔除处理。
表-内生变量集的相关性列表

第二步:利用 PMT 软件里面的 Select Rows 工具把第一步的五个特征剔除并将成交件数作为控制变量,其余的特征放入自变量,再利用 Correlations 工具对7 个外生变量进行成对的相关分析。对相关性大于 0.97 的特征对,视它们近似完全相关。通过上表可以发现“被加购次数”和“加购人数”、“浏览次数”和“浏览 UV”、“拍下笔数”和“拍下 UV”是同一性质的三对内生变量。(如内生变量特征对相关性列表所示)。最终选出 4 类特征作为初步预测成交件数的特征变量:浏览次数(或浏览UV)、收藏夹人数、拍下笔数(或拍下 UV)、加购人数(或被加购次数)
表-内生变量特征对相关性列表

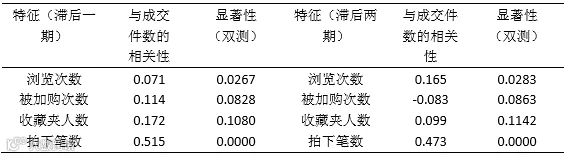
第三步:利用 Correlations 工具对成对的内生变量各自单独与成交件数进行相关性分析,选择相关性相对高的作为接下来的研究因素。结果表明“浏览次数”、“被加购次数”、“收藏夹人数”、“拍下笔数”这四个变量相关性较高,因此选取 这四个变量作为自变量来研究对“成交件数”的影响。其相关性如下表 所示。
表-内生变量与成交件数相关性列表

第四步:考虑到预测需求,自变量需要其滞后一期或者滞后两期。因此需要测量“浏览次数”、“被加购次数”、“收藏夹人数”、“拍下笔数”这四个变量与因 变量 “成交件数”的相关性和显著性。利用Eviews 进行测量,结果发现滞后一期的“浏览次数”、“被加购次数”、“收藏夹人数”、“拍下笔数”与成交件数的相 关性和显著性要比滞后两期的“浏览次数”、“被加购次数”、“收藏夹人数”、“拍下笔数”与成交件数的相关性和显著性更明显。(如外生变量特征对相关性列表所示)。所以选取“滞后一期的浏览次数”、“滞后一期的被加购次数”、“滞后一期的苏藏夹人数”、“滞后一期的拍下笔数”作为自变量对“成交件数”进行研究。
表-外生变量特征对相关性列表
需求预测
根据特征走势图,发现各特征存在异常值,由于异常值会加大预测误差率, 为了确保预测模型的准确性,需进行异常值处理。
第一步,进行异常值的确定
利用 PMT 对该商品的预测目标——“成交件数”特征刻画其走势图,分析结果表明 2014 年 11 月 11 日和 12 月 12 日、2015 年 6 月 18 日、11 月 11 日和12 月 12 日等 5 天的数据存在明显的异常值。并且考虑到促销日对前一天及后一天的销售会产生影响,所以将图中发生异常值节点的前后一天都归为异常值。成交件数异常值分布如成交件数异常值分布图所示:
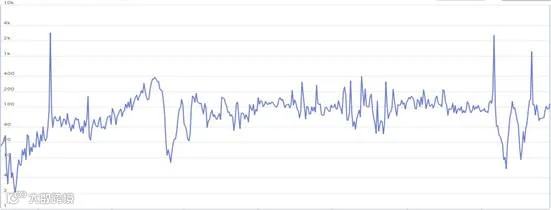
图-成交件数异常值分布图
第二步 正态分布检验及异常值处理
通过 SPSS 分析发现“成交件数”符合高斯分布中的正态分布,再根据 PMT 中的 Outliers 节点中的 Covariance estimator 算法和均值填补方式进行异常值处理。异常值处理后的走势图表明数据相对平稳。
多元回归模型建立
首先,选择“浏览次数”、 “被加购次数”、“收藏夹人数” 、“拍下笔数” 作为自变量,以“成交件数”作为因变量,利用长风大数据挖掘平台里面的 JMT 模块计算模型参数,多元回归预测模型如下:
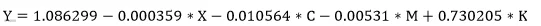
表-回归模型变量表

从预测值与实际值的散点图中可知预测值与实际值偏离程度较大,证明该模型精确度不高。
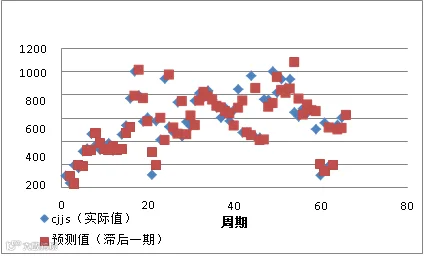
图- 预测值与实际值的散点图
回归模型预测
基于以上回归模型可以预测未来一期的需求量,预测结果如下表所示:
表-预测结果
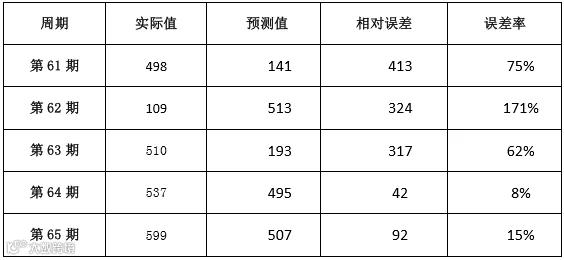
从上表可知多元回归预测值与实际值相差较大,在过去 5 期的预测结果中最小误差为 8%,最大误差为 171%,平均误差为66%。同时全体数据的平均绝对误差(MAE)为 169、平均误差平方和(MSE)为 49638、绝对误差百分率(MAPE)为 44.33%。进一步说明模型的精确度不够。
利用多元线性回归模型预测66 期的成交件数的预测值,其预测值为617 件。
本文选取X1(滞后一期的浏览次数)、X2(滞后一期的被加够次数)、X3(滞后一期的收藏夹人数)、X4(滞后一期的拍下笔数)共 4 个影响因素作为输入变量,成交件数(cjjs)作为输出变量的 BP 神经网络预测模型。用第 1 期到50 期的数据作训练集,第 51 期到 65 期的数据作测试集,进行参数测定。
1. 数据归一化处理
为避免原始数据过大造成的网络麻痹,所以要对原始数据进行归一化处理,归一化方法很多,在本系统中,神经网络的传递函数是基于 S 型的函数。既要满足输入数据的简单,又要保证原始数据的有效性,其输入数据的范围控制在区间[0,1]最佳。采用如下的算法:首先求出这段时间原始数据库的最大值Xmax和最小值Xmin。而Xi和X̂i分别为归一化前后的数据,取数据影响因素的归一化函数为:
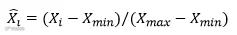
其反归一化公式如下:
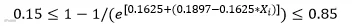
反归一化公式变形如下:
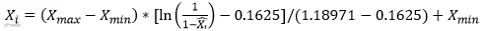
这样就避免了数据落入饱和区域,保持了数据的原有特征,也可以大大加快 网络学习速度。
2. 神经网络模型结果分析
通过 MATLAB 编程,可以测算出模型参数(如BP 网络运行过程图所示)。于该模型,可以预测各期的成交件数。过去五期的成交件数预测结果如下表所示。
表-过去五期成交件数预测结果
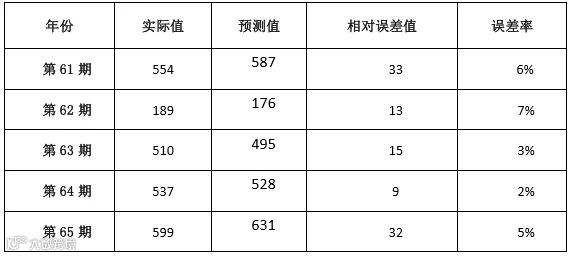
从上表可知多元线性回归预测值与实际值相差不大,在过去 5 期的预测结果中最小误差为 2%,最大误差为 7%,平均误差为 4.6%。同时全体数据的平均绝对误差(MAE)为 19、平均误差平方和(MSE)为 523、绝对误差百分率(MAPE) 为3%。以上数据说明模型在本研究中精度较高。(如BP 网络预测误差图)。
保存已经训练好的BP 神经网络,将第 65 期的影响因素作为输入,即可输出66期的成交件数的预测值,预测值为 619 件。
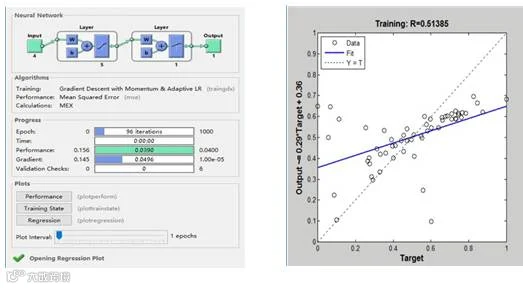
图-BP 网络运行过程图 图 -BP 网络预测误差图
三种评价精度指标
由于大多数学者在评价模型精度时,使用的指标是平均绝对误差(MAE)、平均误差平方和(MSE)、绝对误差百分率(MAPE)这三个指标,所以本文选取这三个指标作为精度评价指标,公式如下:
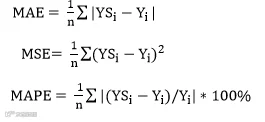
模型精度对比
按照以上三个指标,得出结果如下表 :
表-精度比较
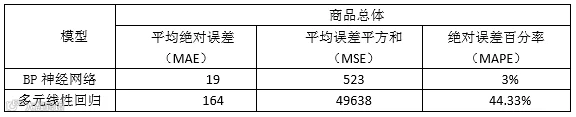
从表 3-4 可以看出,相对于多元线性回归模型,BP 神经网络模型在各项指 标上都具有明显的优势,说明在此次研究中,BP 神经网络更适合。由此预测出第 66 期的成交件数为 619 件。
总仓规划
企业可能存在供需不平衡,造成库存成本或缺货成本。因此,需要对总仓进行合理优化即合理补货。故本文以总仓为研究对象,提出规划建议。
问题抽象化:设某仓库的商品i 在某一时点的实际需求为Di,库存成本为h , 缺货成本为𝑙,预测需求为DFi,相对误差为∆δ。如何调配该商品的库存规划,使得成本期望最小。
如果按照数量Qi补货,则成本函数为:
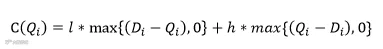
相对误差∆𝛿t =|Di − DFi | ,由于预测需要,本研究认为当期需求与滞后一期的相对误差存在关联。选取滞后一期的相对误差∆δt;1,根据统计经验,设定相对误差∆δt-1服从正太分布,即∆𝛿𝑡-1~N(0, σ2) 。而预测需求值已经通过神经网络模型计算出,设定为一常数,则假设商品需求服从均值为,方差为滞后一期的相对误差∆δt-1的正态分布,即Di~N( DFi , ∆𝛿𝑡-12) 。那么,这个问题就转化为需求分布已知的连续随机变量的报童模型问题。
① 当𝑄i≥ Di时,产生单位库存成本为ℎ,则持有成本期望值为:
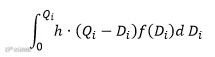
② 当𝑄i ≤Di时,产生单位缺货成本为𝑙 ,则缺货成本期望值为:
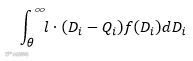
总的损失成本期望:
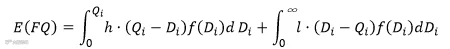
令
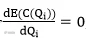
并根据莱布尼茨公式,得
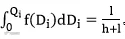
此时,求得Qi的最优值,而最优值Qi∗即是该仓库对该商品i 的库存规划。
通过对前面的分析,可以看出Qi∗实际上是在确定相对误差的分布、缺货成本 和库存成本的基础上,对预测值进行调整,通过调整,将Qi∗作为商品i的分仓规划值。
假设商品需求服从均值为DFi,方差为 1.25*MAD的正态分布, 即Di~N(DFi , 1.25MAD2)。其中,MAD (mean-absolute deviation)是 Brown 在 1959年提出的[4],可以通过指数平滑来估计,即MADt = α ∗ MADt-1 + (1 − α)| DF 𝑡-1 − Dt-1|,其中α为平滑系数,一般取值[0.1,0.2]之间,本文取值为0.1。将此假设与本文基于相对误差分析的需求分布假设做比较,选取编号为 3435 商品过去 5 期的总仓成本进行对比分析,如下表所示。
表 -两种假设的库存优化比较
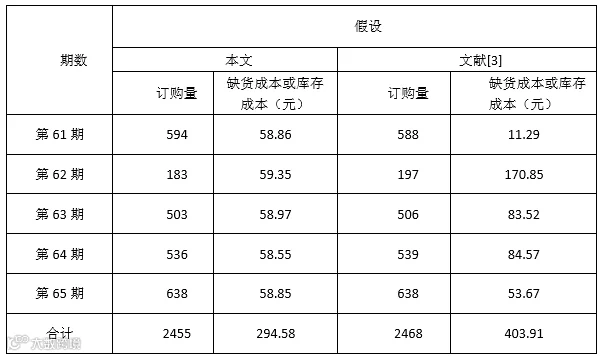
从上表可以看出,本研究所采用的分仓规划方法优于文献[3]的分仓规划方法,由此可见本研究的分仓规划方法对总仓规划更具有参考意义。基于本文分仓规划方法,由第 66 期预测值 619 件,计算出第 66 期的订购量为 626 件。库存成本或缺货成本为 58.4 元。
结论
1. BP 神经网络模型更适合于本案研究,研究结果全期最小误差为 0%,最大误差为 8%,平均误差为3%。用 BP 神经网络预测模型来预测商品成交件数效果更好,可以为总仓规划提供数据支持。
2. 预测该商品未来一周即 2015 年 12 月 28 日到 2016 年 1 月 3 日的成交件数,预测值为619 件。
3. 本文中服从Di~N(DFi ,∆𝛿𝑡-12) 的总仓规划方法优于文献[3] 中的服从Di~N(DFi , 1.25MAD2)的总仓规划方法。本文总仓规划方法在过去五期中订购量和库存成本明显小于文献[3]。
4、基于第 66 周即 2015 年 12 月 28 日到 2016 年 1 月 3 日的预测值为 619件。选取本文总仓规划方法,计算出订购量为 626 件,缺货成本或库存成本为58.4 元。
作 者:广西财经学院-广财小分队
团队成员:何雨蒙、韦琼英、邹鼎 、庞积凤、 唐春连
指导老师:黄毅、王逸
近期长风大数据公众号将于每周一、三、五定期推出2017大数据分析专业竞赛作品赏析系列,评论里留下你想看到的作品,小编会努力满足你的要求哦
同时,竞赛的优秀作品集也在密集整理当中,想要获取免费赠送名额的小伙伴,点赞转发一下呗

声明:微信文章为独家原创,欢迎个人用户分享到朋友圈;其他任何形式的转载,请联系本公号取得授权,否则将追究法律责任。长风大数据(微信号:cf-dsj)隶属于Logis北京络捷斯特科技发展股份有限公司,简称:络捷斯特,证券代码:834832。

长风大数据(微信号:cf-dsj)基于多行业的海量数据资源,为企业运营和院校科研提供先进的数据挖掘分析工具,帮助用户释放数据价值、捕获深层信息。
联系电话:010-65568598转8013
电子邮箱:cfdsj@logis.cn
网址:http://www.cfdsj.cn

