

2018.03.06
“大数据系列公开课即将登录各大高校”的通知发出
2018.03.20
全国30多所高校的近百名师生报名
2018.03.21-2018.04.04
Logis大数据团队奔赴北京、广州、银川、西安为多个院校的老师与学生就大数据人才培养在高校中的转化和应用问题做了相关分享和交流

北京物资学院、北京电子科技职业技术学院



广东省轻工业高级技工学校、广东药科大学中山学院



北方民族大学、宁夏职业技术学院、宁夏大学新华学院、银川能源学院





西安理工大学、西安交通工程学院、陕西青年职业学院、咸阳职业技术学校





此次公开课分享内容包括大数据在物流行业的发展背景与聚类分析算法在企业客户群识别的应用。课堂上,老师以用图片聚类的小游戏切入,不仅提高了大家听课的兴趣,而且帮助大家进一步理解机器学习算法中的有监督学习的分类算法与无监督学习的聚类算法的根本区别。
知识点1:分类与聚类
分类:分类任务就是通过学习得到一个目标函数f,把每个属性集x映射到一个预先定义的类标号y中。
聚类:聚类指事先并不知道任何样本的类别标号,希望通过某种算法来把一组未知类别的样本划分成若干类别。
知识点2:K-Means聚类算法
概念:K-means是一种基于距离的迭代式算法。它将n个观察实例分类到k个聚类中,以使得每个观察实例距离它所在的聚类的中心点比其他的聚类中心点的距离更小。
特点:依据属性进行分组,使组间差别大,组内差别尽可能小。
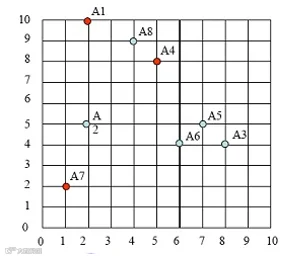
为了让大家深入理解K-Means聚类算法原理,老师给大家发布了一个小任务,如下图所示,网格中有八个坐标点,需要划分为3类,确定初始质心A1、A4、A7后,让大家自己依据聚类原理迭代计算。
经过不断迭代以及更换质心后,所得结果如下:
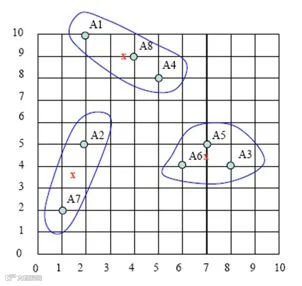
同学们手动计算后,纷纷表示计算量太大,而且计算时间比较长。这也是我们为什么要用工具去做数据挖掘分析的一个原因。
一场公开课虽然没办法将更多专业知识传送给大家,但是至少大家对于大数据的概念、特点、分析过程以及无监督学习中的聚类算法都有了一定的理解。结合企业实际案例以及数据挖掘分析工具PMT的亲身实践,使得没有计算机专业知识的经管专业的同学对数据挖掘兴趣大大提升,这就是我们公开课的意义所在了。
公开课太短没听够?福利来啦~

“基于聚类分析的快递企业客户群识别实验”实操教程视频获取方式:
1.关注“cf-dsj”公众号;
2.在公众号后台回复“K-means”;
3.获取视频下载地址&密码;
注:在文章末尾点击阅读原文,也可以获取视频下载地址呦 ;
;
即可获取“基于聚类分析的快递企业客户群识别实验”实操教程视频哦!

声明:微信文章为独家原创,欢迎个人用户分享到朋友圈;其他任何形式的转载,请联系本公号取得授权,否则将追究法律责任。长风大数据(微信号:cf-dsj)隶属于Logis北京络捷斯特科技发展股份有限公司,简称:络捷斯特,证券代码:834832。

长风大数据(微信号:cf-dsj)基于多行业的海量数据资源,为企业运营和院校科研提供先进的数据挖掘分析工具,帮助用户释放数据价值、捕获深层信息。
联系电话:010-65568598转8013
电子邮箱:cfdsj@logis.cn
网址:http://www.cfdsj.cn
长风大数据 ∣一个有逼格的平台

