
大
赛
2021年第五届“长风杯”全国大学生大数据分析与挖掘竞赛为参赛师生准备了《商业智能数据分析》和《大数据分析与挖掘》的课程。
大赛竞技组选手通过课程学习大数据技能,从大赛必选赛题中四选一,完成数据分析报告。
“夏季服装销量预测”是赛题之一,给出某电商平台网站夏季服装销售数据集(包括产品、网店、宣传、评价、销售等信息),让参赛队伍完成销量预测数据模型的构建。
项目团队使用了决策树、神经网络、随机森林、梯度提升算法构建数据预测模型并分析比较,从数据获取、分析处理、模型训练到模型评估,全过程使用蓝鲸大数据分析与挖掘工具完成。
///
团队名称;154
团队成员:杨梦娜,段薇,秦婷婷
指导教师:刘国秀
所在学校:金陵科技学院
数据获取分析
明确问题获取数据
本项目基于电商平台网店服装销售历史数据,运用科学的方法,对未来一定时期服装的供求变化规律以及发展趋势进行分析,构建销量预测模型。
项目团队从蓝鲸的云资源获取查看数据集,初步设置目标变量、特征变量,并进行缺失值处理。
数据探索性分析
在数据探索性分析过程中,项目团队使用散点图观察特征变量与目标变量间的相关性。如评分数量、等级、商店评分等特征变量与单位销售量之间的相关性。
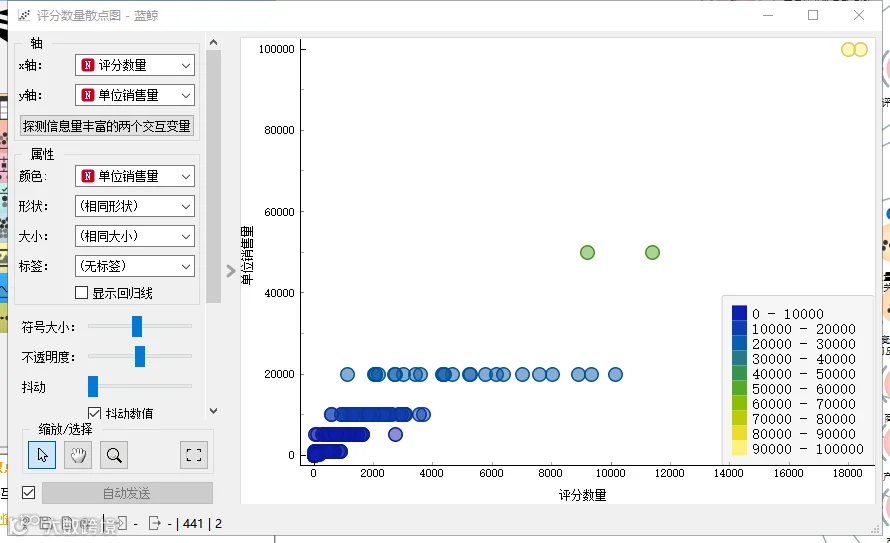
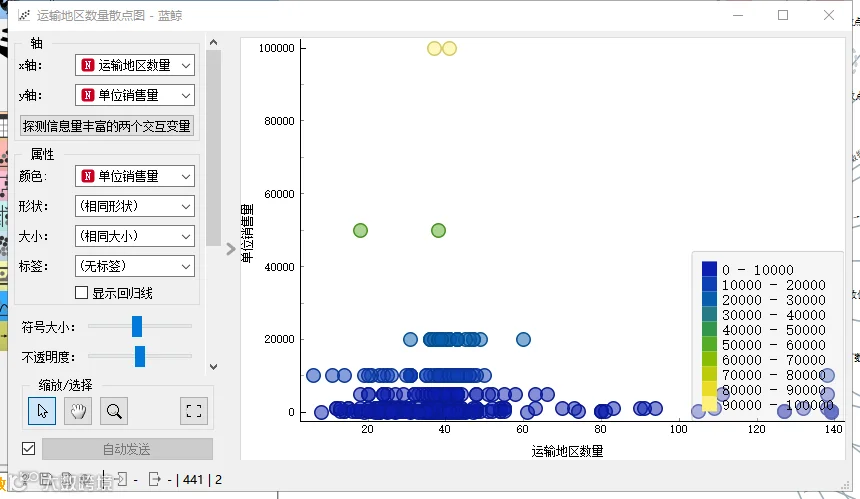
项目团队运用大数据分析方法来探索各变量之间的相关性。
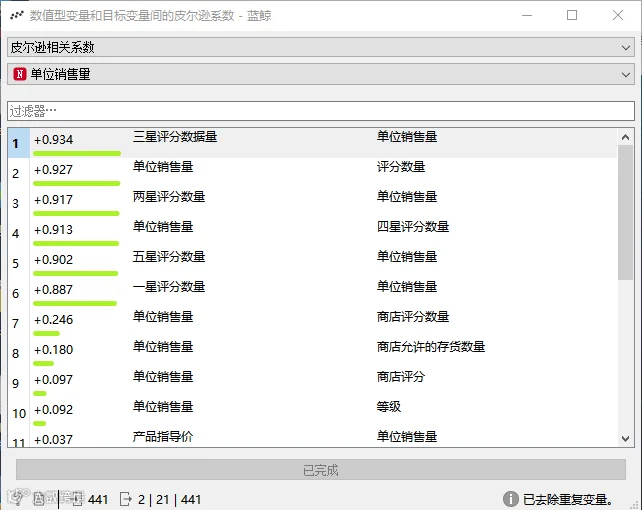
分析比较相关性,最常用的是皮尔逊相关系数分析法。
通过观察皮尔逊相关系数来探索数值型变量的相关性,皮尔逊相关系数的值介于-1 和 1 之间,越接近于 1 则正相关性越强,越接近于-1 则负相关性越强。
运用“皮尔逊相关系数”分析组件查看,如果各特征变量相似,且他们之间皮尔逊相关系数均在 0.9 以上,可以保留一个相关性最强的。
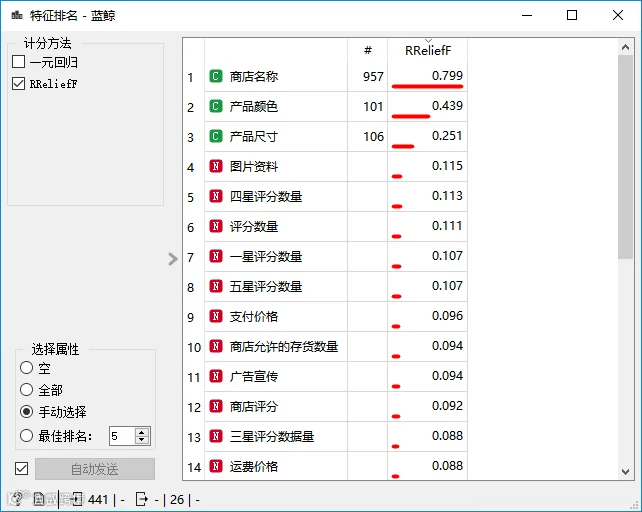
探索数值型变量与目标变量的相关性。如图三星评分数据量、评分数量与单位销售量正相关关系最强。
探索其他变量与目标变量的相关性。选择散点图、分布图、特征排序等来进行分析。
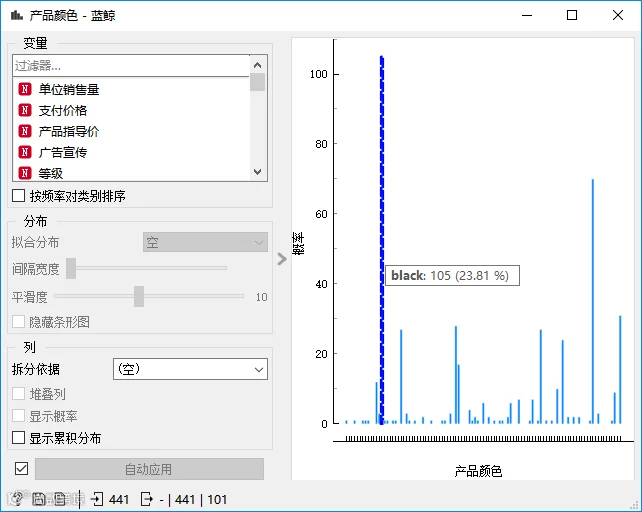
特征工程
特征工程是为了提高模型预测精度,将原始数据转化成更好的表达问题本质的特征的过程。
特征选择
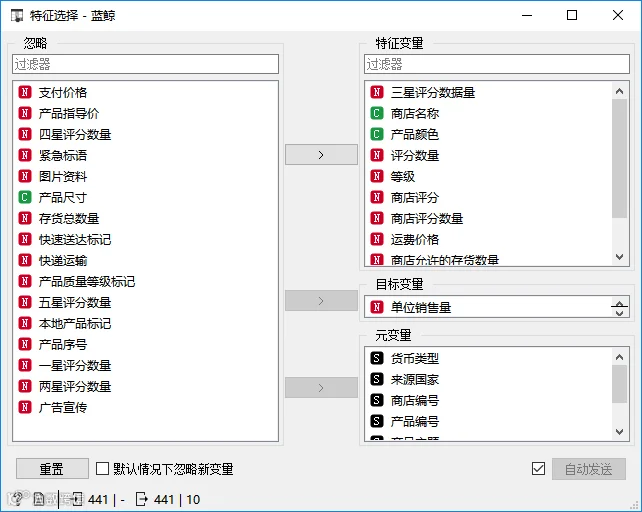
项目团队根据数据探索性分析的情况进行特征选择。
特征选择影响建模效果。特征变量太少,不足以描述数据,易造成偏差;特征变量太多,则会增大计算成本或导致过拟合。
数据预处理
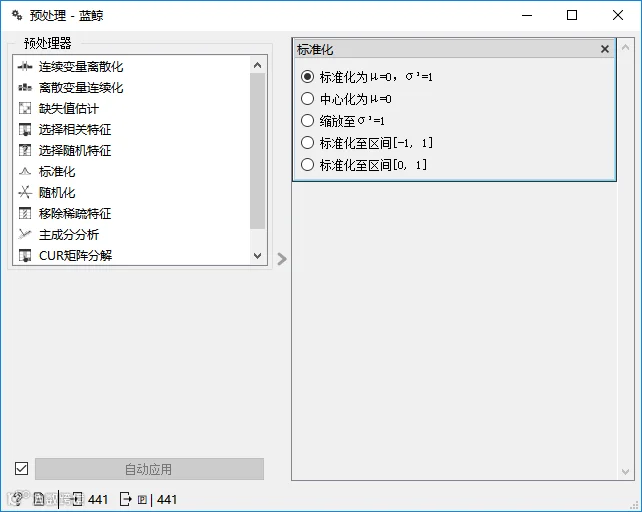
在构建模型之前,通常要对数据进行离散化、连续化、标准化或随机化等预处理。
蓝鲸预处理组件提供了多种方法供选择。标准化处理适用于特征值取值不均匀的情况。
模型构建
项目团队通过比较不同算法的优缺点,选择决策树、神经网络、随机森林、梯度提升这四种算法对数据进行模型构建。
数据集划分
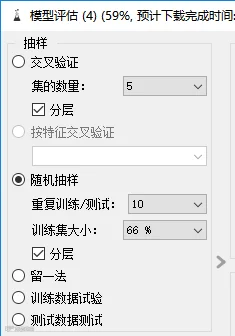
数据集通常按7:3比例划分训练集和测试集。训练集用于模型训练,测试集在模型训练好后,通过预测情况来评估模型效果。
训练时,为了更充分的利用数据,可以采用交叉验证法来处理。
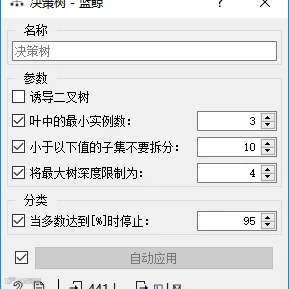
蓝鲸中“模型评估”组件可以对数据集划分进行设置。
模型训练
根据分析,做好特征处理,构建数据建模,选择4种模型。
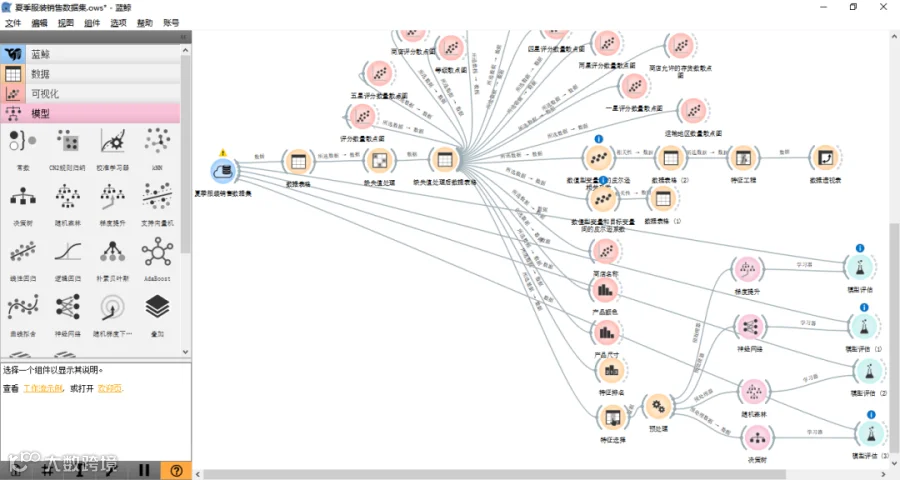
蓝鲸客户端,提供了丰富的模型组件,各模型可以通过设置调整有关超参数来进行迭代优化。
这种设计有利于数据分析人员聚焦于算法的应用,无需将过多精力用在算法编程上。

模型评估
通过“模型评估”组件,选择多种评估方法进行比较。本项目观察比较MSE、R2,选出模型效果较好的算法为梯度提升。
小结
本项目通过蓝鲸大数据挖掘平台实现了对夏季服装销量的预测模型构建、训练与评估。
销售预测模型越准确,越能解决库存积压、利润损失和缺货等问题,进而会影响到供应链、客户服务和品牌。

圣
诞
快
乐
/ 2021.12.25
关注官网及微信公众号,了解大数据教研咨讯!

关注我们
微信号|cf-dsj