

NEWS

上海市税务局第四稽查局经税收大数据进一步分析,发现邓伦涉嫌偷逃税款,最终,邓伦偷逃税被处罚并追缴1.06亿元。
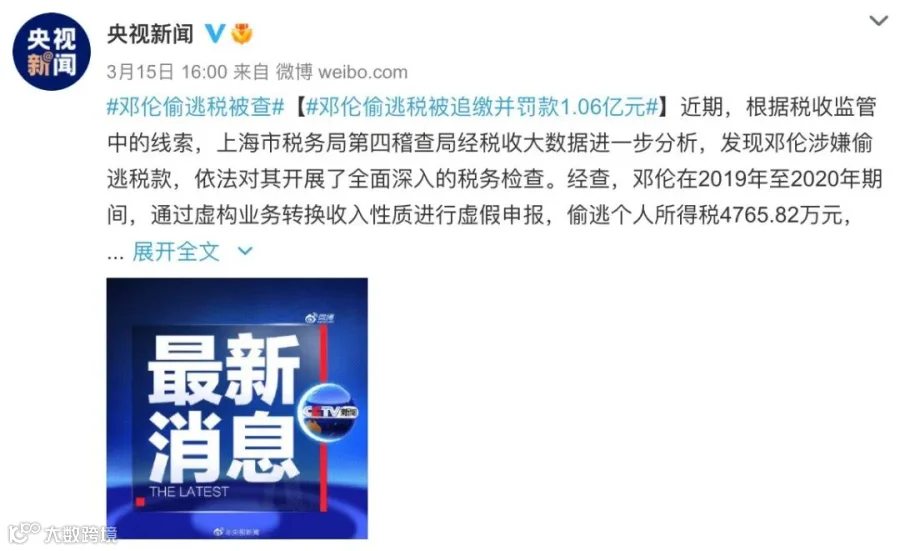
因偷税漏税,被罚1.06亿的邓伦,被罚13.14亿的薇娅,被罚2.99亿的郑爽,被罚8.84亿的范冰冰……这些涉税违法案件均出现了“税收大数据”的身影。
税务部门是采用大数据+提醒、督促、警告、重点稽查、公开曝光的“五步法”查出偷税漏税的人员。

税收大数据分析系统在案件的发现和查处中功不可没,为税务机关加强风险预警、科学精准监管提供了有力支撑。
这个神秘的“税收大数据”究竟是何方神圣?

揭开“税收大数据”神秘面纱

税收大数据
“税收大数据”,本身是指在税收征管过程中形成的一类大数据集,相比于传统的税收统计数据和税收调查数据,税收大数据具有独特的特点:在数据应用层面,将机器学习、云计算以及数据挖掘等技术综合应用于税收征管和经济分析等领域是目前的主流趋势。
邓伦事件就是依靠税收大数据分析实现风险检测,也就是通过对纳税人涉税数据的全面分析、深入挖掘、自动关联,排除常规性事项,发现潜在风险点(异常值)。

如何实现税收风险(异常值)检测?

实现风险检测
当观测值是一堆数字且都是一维时,辨别风险点(异常值)很容易,但如果有数以千计的观测值或数据是多维的,尤其是面对海量的税务数据,如何从几亿纳税人中检测出偷税漏税人员呢?单单靠人工是不可实现的,需要借助大数据分析中的异常值检测实现。
异常值检测是根据一定准则识别或者检测出数据集中的异常值,所谓异常值就是和数据集中的绝大多数据表现不一致。
例如异常值是由于数据本身的变异造成的,那么对他们进行分析,就可以发现隐藏的更深层次的,潜在的,有价值的信息。例如发现偷税漏税行为,金融和保险的欺诈行为,黑客入侵行为等。
检测异常值的常用方法主要分为以下几大类:
一、统计方法
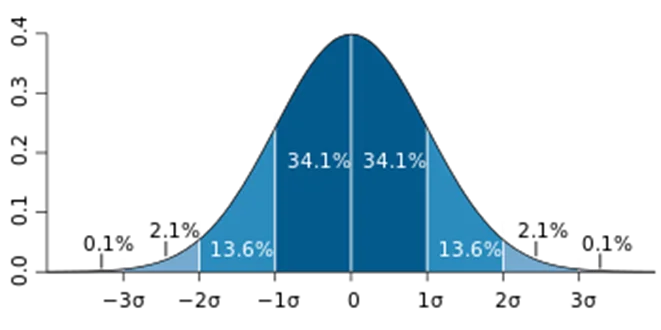
1.3σ准则
3σ准则是指先假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,认为凡超过这个区间的误差,就属于异常值。
2.箱线图
二、机器学习
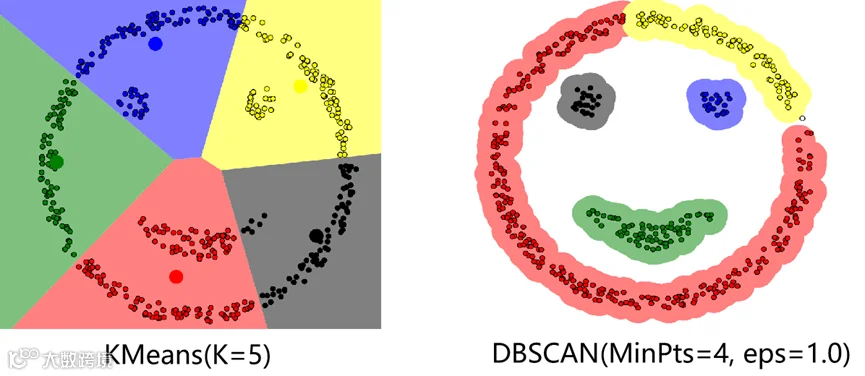
1.聚类(Clustering)方法
聚类(Clustering)方法是通过计算数据对象之间的相似性进行划分类别,最终将相似数据分为一类,也就是“同类相同、异类相异”。通过聚类也可以实现异常值检测,如基于密度的DBSCAN聚类算法,基于划分的K-means算法和基于层次的聚类算法等。
2.孤立森林(Isolation Forest)方法
该方法是一维或多维特征空间中大数据集的非参数方法,其中的一个重要概念是孤立数。孤立数是孤立数据点所需的拆分数。这种方法的工作方式不同。它明确地隔离异常值, 而不是通过给每个数据点分配一个分数来分析和构造正常的点和区域。它利用了这样一个事实:异常值只是少数,并且它们具有与正常实例非常不同的属性值。


操作方法
下面我们用蓝鲸数据挖掘软件实现一个异常值检测的应用案例:
以波士顿房价预测模型为例,在获取波士顿房价数据集后利用“异常值检测”组件中实现异常值检测,如图利用“散点图”可以直观地看到原始数据与经过异常值检测并处理后的数据分布。
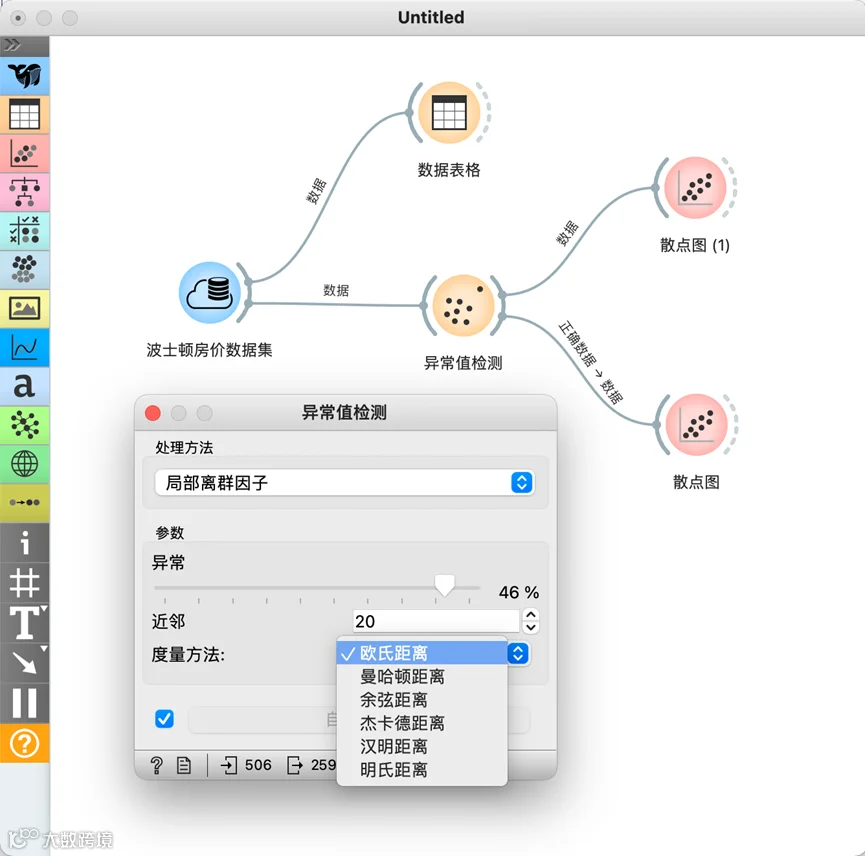
构建模型实现异常值处理
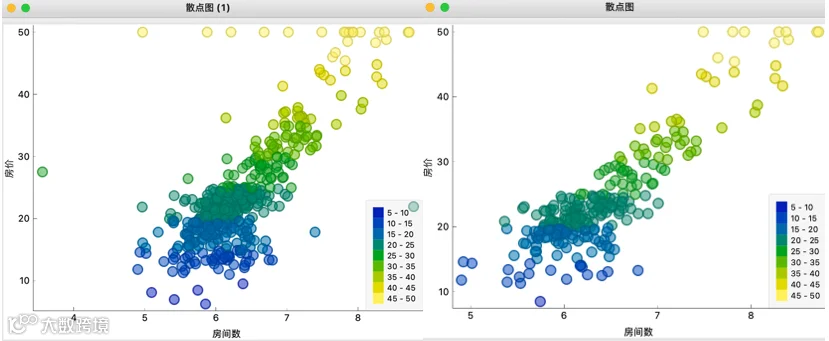
原始数据散点图与剔除异常数据散点图
除此以外,蓝鲸数据挖掘中的箱线图、聚类算法等也可以实现异常值检测。
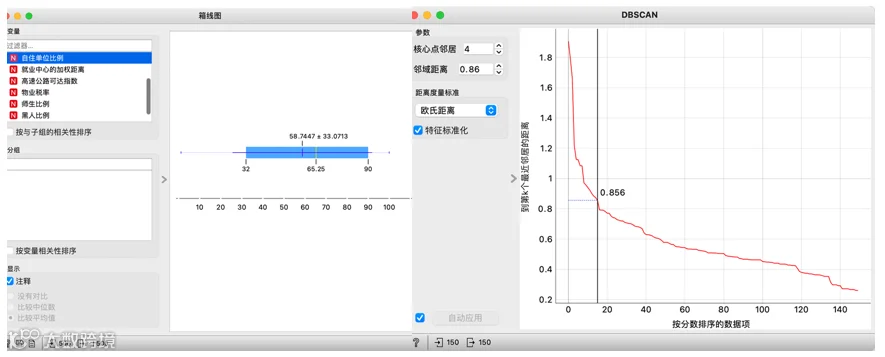
箱线图异常值检测与DBSCAN聚类算法
这么好的工具还不赶紧用起来!
除了强大的大数据分析功能,即使面对非理工科出身的学生也非常友好,我们知道大部分数据挖掘工具的使用需要编程基础,对于非理工科出身的学生,难以发挥数据挖掘在经济、管理方面的应用性,而我们要推荐的这款蓝鲸数据挖掘软件可以完美解决这一痛点。
目前,蓝鲸数据分析挖掘软件的全新版本正式上线,对所有用户免费开放下载。


蓝鲸是一款拖拽式、非编程的数据挖掘软件,采用可视化建模的设计思路,支持数据挖掘问题的主流算法,并且具有可拓展性功能,具备数据描述与理解功能、数据获取与组织功能、数据挖掘建模功能。它封装了包括机器学习、数据预处理和数据可视化等组件,帮助使用者以最简约的方式通过数据挖掘和机器学习来解决业务问题。
进入蓝鲸官网,首页免费下载蓝鲸软件!
网址:https://bw.dashenglab.com,或直接点击文末“阅读原文”进入。
温馨提示:
目前蓝鲸软件不仅免费开放下载,而且蓝鲸官网还提供物流、供应链、电商、交通运输等丰富的行业数据和案例资源。赶紧进入官网下载,让我们一起来探索数据挖掘的奥妙吧!

点击阅读原文查看更多内容