

投稿来源:湖南财政经济学院|凌云团队
研究背景
在电商行业,随着大数据技术的发展,商家可以搜集到用户的消费记录,怎样挖掘消费者的特征和价值,以及如何有针对性的对用户进行精准营销,是商家最关注的问题,也是CRM的核心应用场景。
研究目的
运用真实的交易数据评估用户价值;筛选最优质的用户进行精准营销。
数据准备
以巴西电子商务交易数据为例,计算出各指标的值。
R指标的计算:
R指标表示最近一次购买日期距离数据采集日的天数,将数据采集日定为2019年12月8日,R=数据采集日-最近一次购买日期。
F指标的计算:
用户消费的总次数。
M指标的计算:
用户消费的总金额。

指标计算结果截图
模型的构建
RFM模型在应用时需对指标离散化后再分析,常见的方式是分成五个等份,每个等份接近20%的用户,由于R指标的影响是负向的,值越小越好,F指标和M指标的影响是正向的,值越大越好。将R、F、M三个指标离散化后的得分进行组合,得到每一个用户的RFM得分(即RFMscore),得分越高,用户价值越大。
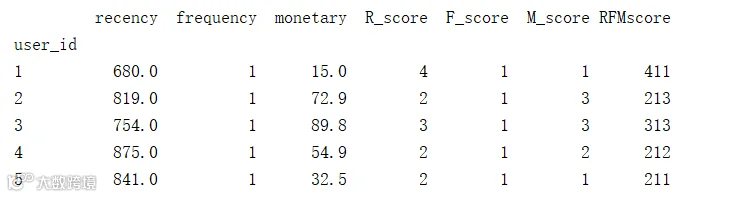
模型构建结果
基于RFM得分结合二八法则对用户进行分类,指标得分进入前20%区间赋值为1,另外80%赋值为0,三个指标进行组合,能够把所有用户分成八类。
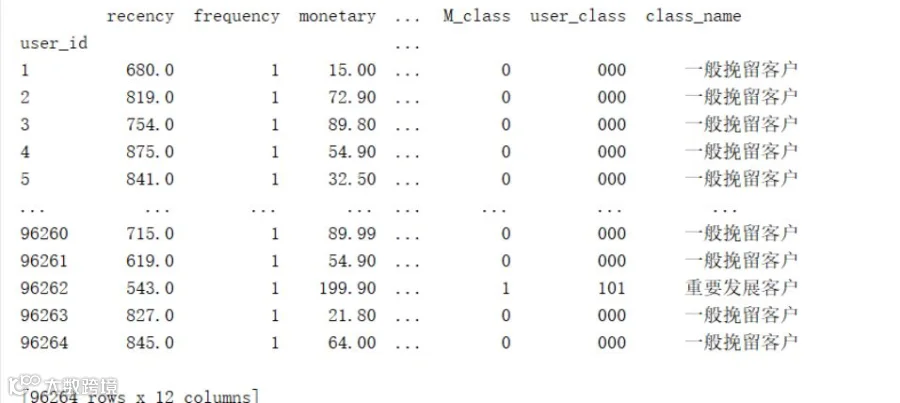
用户分类结果
用户价值计算
为了更好的区分不同类用户的价值差异,引入动态权重计算单个用户的价值。
01
层次分析法计算主观权重
建立判断矩阵
根据巴西电子商务数据级交易产品特点,建立的判断矩阵如下:
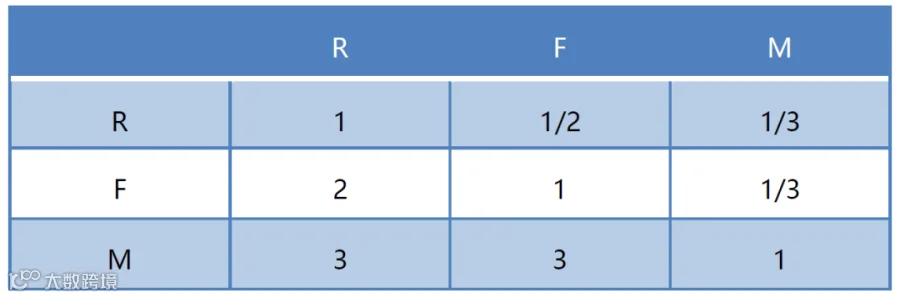
归一化处理
得判断矩阵的特征向量W=(0.16,0.25,0.59)T。
计算最大特征根λmax,
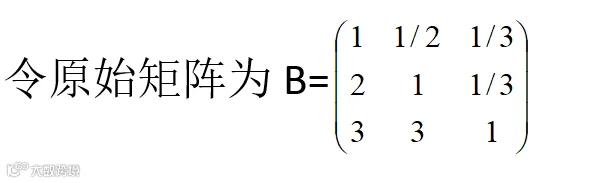
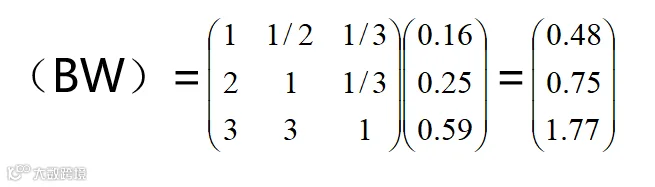
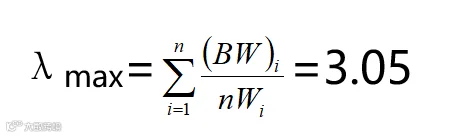
一致性检验
一致性指标CI,
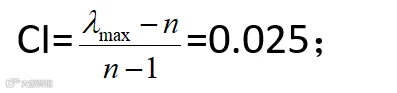
检验系数CR,
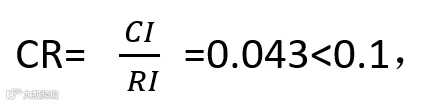
判断矩阵通过一致性检验,确立R、F、M指标主观权重分别为0.16,0.25,0.59。
02
熵值法计算客观权重
数据标准化
由于数据采集日定为了2019年12月8日,为了消除数量级带来的影响,首先对数据进行标准化处理。因为F指标和M指标对客户价值影响是正向的,采用第(1)个标准化公式,R指标影响是负向的,采用第(2)个标准化公式。
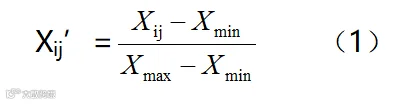
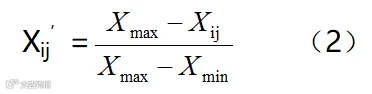
计算第i个样本下第j项指标的比重,
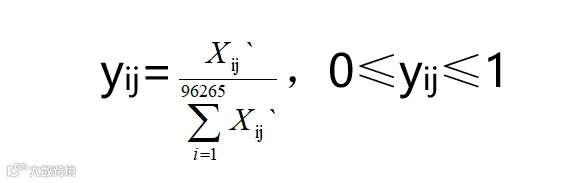
计算第j项指标的信息熵,
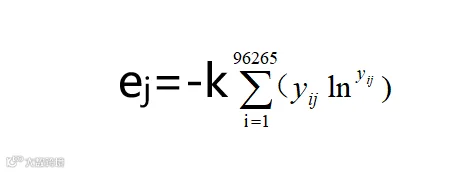
式中,k为波尔茨曼常数,
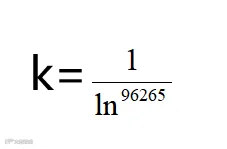
计算第j项指标的差异系数,
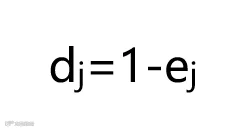
计算各个指标的权重,
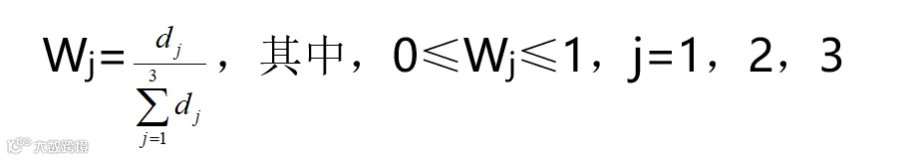
利用程序计算R、F、M指标的客观权重分别为0.02,0.86,0.13。
03
综合集成赋权法确立最终权重
设Pj和Qj分别为R、F、M三个指标的主观权重向量和客观权重向量,最终权重计算公式为:
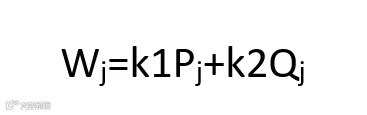
其中,k1和k2为合成系数(k1,k2>0,且k1+k2=1)
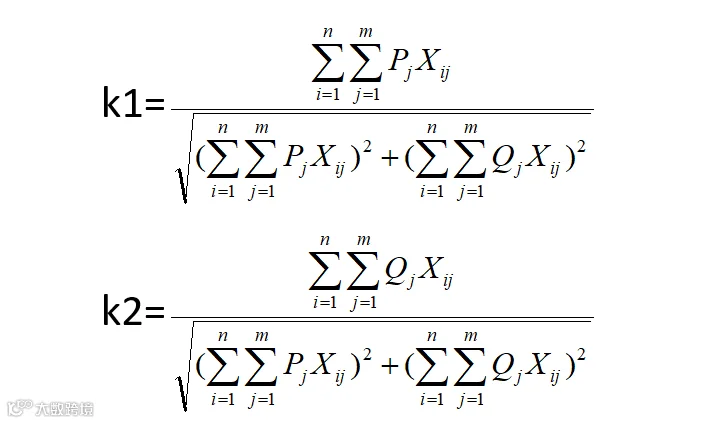
将主客观权重进行结合,确定巴西电子商务交易数据R、F、M指标的最终权重分别为0.14、0.33、0.52。
对标准化的R、F、M进行加权求和,得到每一个用户的价值得分:
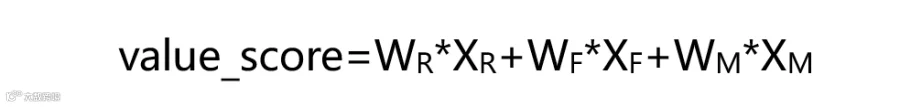
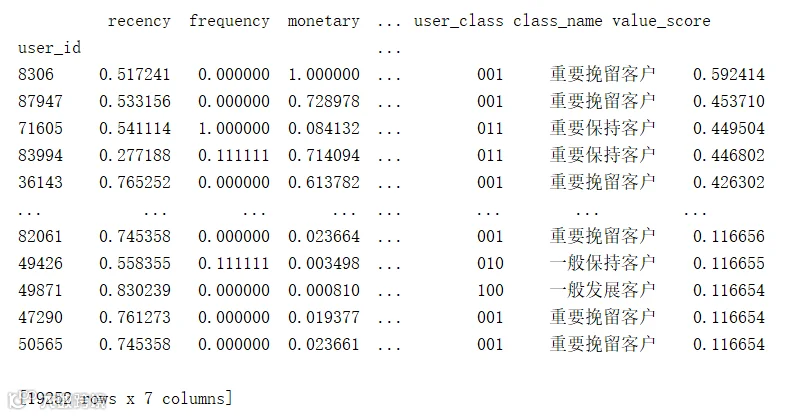
筛选优质用户
以value_score这一列对数据进行降序排序,并筛选出价值得分位于前20%的客户,从下图可以看到,引入动态权重之后,价值最高的不一定是重要价值客户,以此评估的用户价值更加科学。
模型的应用
将构建好的模型应用于CDnow网站的销售数据和kaggle的某一零售数据。用户价值识别结果如下图所示。
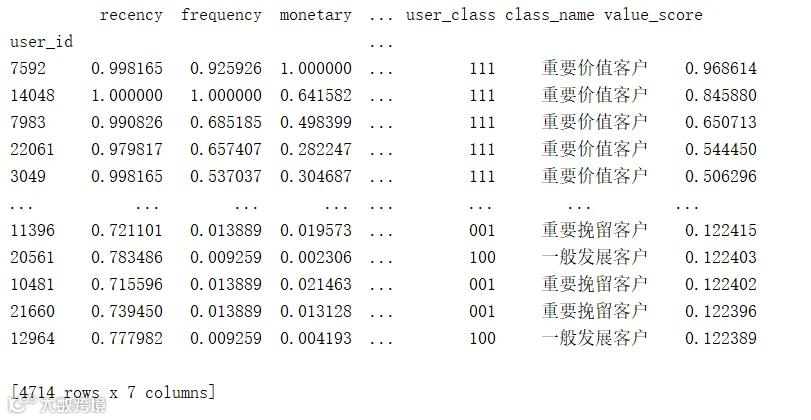
CDnow网站销售数据
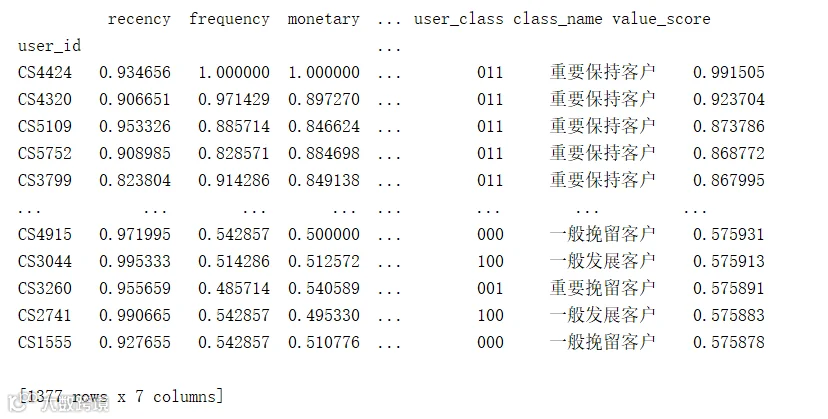
kaggle某一零售数据
现实意义
RFM模型能够快速的识别最有价值和最没有价值的客户,但是对于中间的客户没有办法进行区分,因为不同行业、不同领域的业务需求是不一样的,各指标的重要性也不一样。动态权重的引入能够更好的识别用户价值,量化用户价值差异,从而筛选最优质的用户实现精准营销。此外,动态权重RFM模型建立在传统RFM模型基础之上,能够适应不同行业的业务需求。

长风大数据(微信号:cf-dsj)
基于多行业的海量数据资源,为企业运营和院校科研提供先进的数据挖掘分析工具,帮助用户释放数据价值、捕获深层信息。
联系电话:010-65568598转8007
电子邮箱:cfdsj@logis.cn
网址:http://www.cfdsj.cn