

万众瞩目的2018世界杯即将在俄罗斯拉开战幕。四年一次的足球盛宴,更是每一个球迷翘首以盼的狂欢节日,球迷们痴迷的呐喊,激动至晕厥的欢呼仿佛已经随着2018世界杯的临近在我们耳边响起。
毫无疑问,谁将捧起世界杯是我们最关心的问题,长风数据君作为一名“资深”球迷自然得发挥下自己的专长,用python模拟2018世界杯,先给大家解解渴。

世界杯即将开打,一切都是未知数,不过整个赛程已定,我们可以完全按照赛程模拟全部64场比赛比分10000次,得出A~H组各自的出线形势、每支队伍进四强的概率、以及最终的夺冠概率。
接下来我们将要运用离散概率分布中的泊松分布来对本次世界杯进行预测,一共分为四个步骤:
1. 数据采集(用python实现网络爬虫,进行抓取资源);
2. 计算球队进球、失球均值,构建算法模型;
3. 模拟10000次世界杯赛事,进行分析;
4. 统计出线概率、夺冠概率、四强概率;
寻找有利资源和所要采集的网站,准备开始数据采集。这次采集以球探网为例:
首先找到32个国家各自的网站链接;然后分别进入32个链接,采集各自的比赛记录数据;
解析网站,构造大体思路,创建网络爬虫实施采集。由于该网站是静态网站,所以就很容易的对网站的采集,在采集的过程中,我们首先找到,每个国家球队的链接,建立国家球队链接和国家球队名,然后进行采集给定国家队页面的所有历史比赛的数据。
在寻找国家链接的时候请注意链接的准确性,球探网每一个球队都有一个独立的链接,比如巴西的id是778,链接地址就为:http://zq.win007.com/cn/team/CTeamSche/778.html,如果对链接的不放心,可以先将链接复制到浏览器中,看是否能够找到网页。
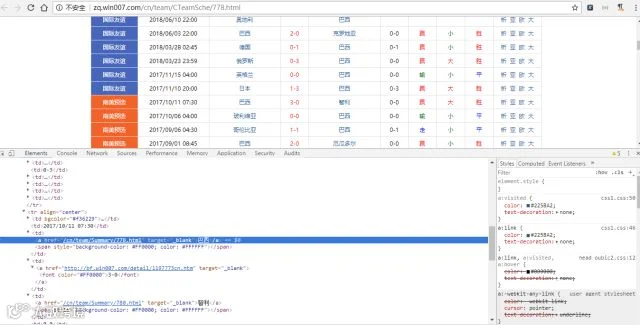
以下为数据采集详细代码:
这只是网站的其中一种采集方法,也可是使用scrapy框架在进行抓取(在此不再详细介绍),只要获得到数据我们将进行下一步的分析。
泊松分布适合于描述单位时间(或空间)内随机事件发生的次数。如某一服务设施在一定时间内到达的人数,电话交换机接到呼叫的次数,汽车站台的候客人数,机器出现的故障数,自然灾害发生的次数,一块产品上的缺陷数,显微镜下单位分区内的细菌分布数等等。
从泊松分布的应用实例中可以看出非常适合世界杯的预测,所以今天我们要建立泊松模型来模拟本次比赛。
若进球数 x>4 ,强制 x=4 。这是因为热身赛双方实力差距过大,德国8:0马来西亚,这种差距在世界杯决赛圈是很难看到的。
亚洲球队与欧洲球队水平存在一个差异值,需要整体乘以一个系数。韩国场均进2球,相比德国场均1.5球,韩国的对手亚洲球队居多,德国打过欧洲杯对手实力不俗,韩国的场均2球必须打折扣。
在本次预测中我将使用一款软件(Logis PMT)进行python脚本的开发,最后我将补充说明该软件。首先我从OPTA获取到每场球的比分,通过用软件的python脚本对数据进行清洗,得到干净的数据框用来建模。
以下为软件的部分截图与使用情况:
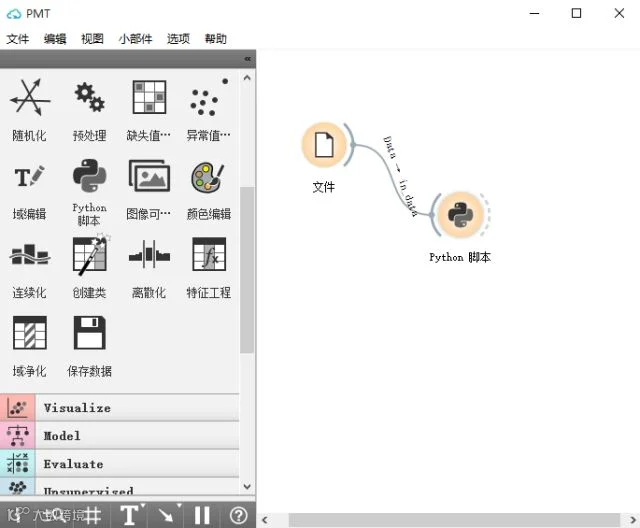
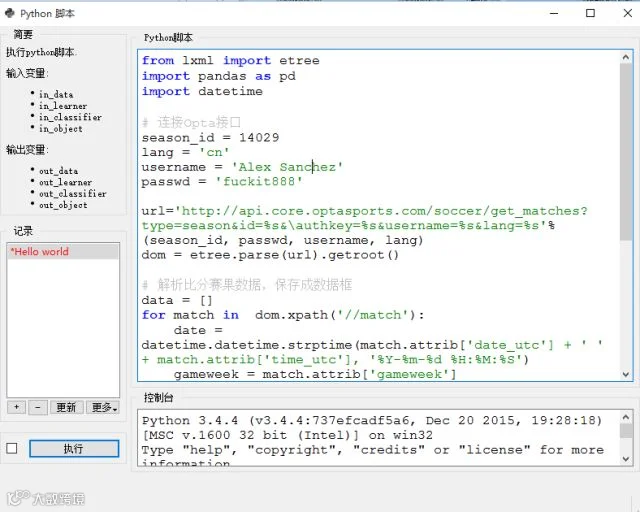
接下来我们计算球队进球率、失球率。
上面我们提到了泊松模型,这里i,j指代两支球队,Xij表示两队比赛中主队进球数,Yij表示客队进球数。Φij表示主队进球率,Ψij表示客队进球率, 通过我们采集的赛事比分数据,可以利用极大似然估计方法将进球率、失球率估算出来。
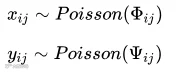
得到计算结果,按进攻实力排序(尾部的球队没有列出来):

先模拟一场比赛:淘汰赛与小组赛不同,如果打成平局必须进行点球大战,决出胜负。点球大战就设定各自50%概率晋级,下面这个simulate_match函数传入knockout参数为True时,就会激发这个机制,返回晋级的球队名。如果不是knockout,就是小组赛,就是输出模拟的比分。
在本次预测中,我还是继续使用PMT中的脚本进行分析:
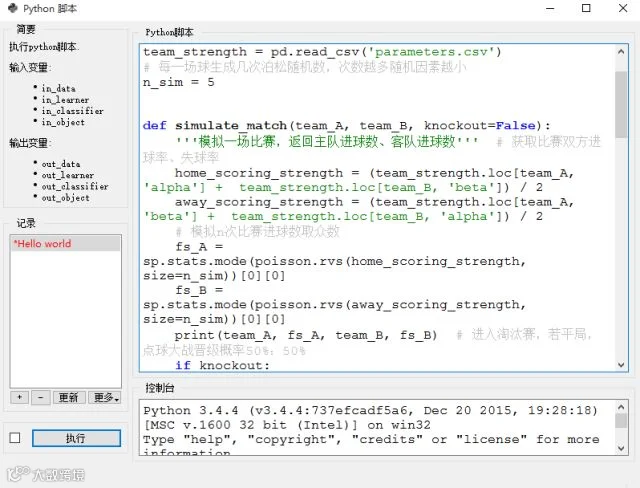
详细代码如下:
接下来是赛程,小组赛有6场每个组,8组共48场。按照赛程我手动写入列表里,比如A组的比赛按顺序,对战双方分别是这样:
然后建了一个类,每个组分别各自初始化自己的类,传入参数fixture就是上面创建的赛程,只需调用play函数就可以模拟该小组6场比赛比分。self.table是小组积分榜,保存下来每次模拟的小组头两名球队名,后面统计每支队在10000次模拟里出线的次数,即出线概率。
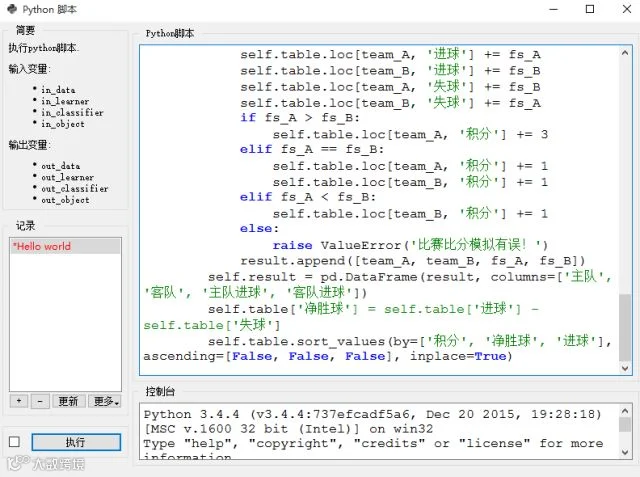
代码如下:
随后淘汰赛,16进8、8进4、半决赛和决赛。赛程球探网给出了,包括进入16强的对阵形势,每场由哪组第一对阵哪组第二都写清楚了,我们只要继续用上面模拟比赛的方式继续按照赛程模拟就可以了。
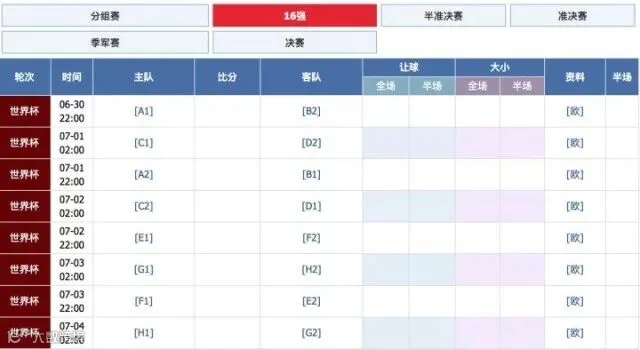
至此,我们可以完整模拟一届世界杯的全部64场比赛的比分。
最重要的,我们记录下每组的出线球队、以及冠亚军、季军、殿军分别是哪个国家。接下来就可以轻松循环10000次,并进行统计。
A~H组各自的出线概率我已经统计完成,东道主俄罗斯的FIFA世界排名已跌至65位,不过俄罗斯抽签抽到上上签,有望小组出线进入下一轮。
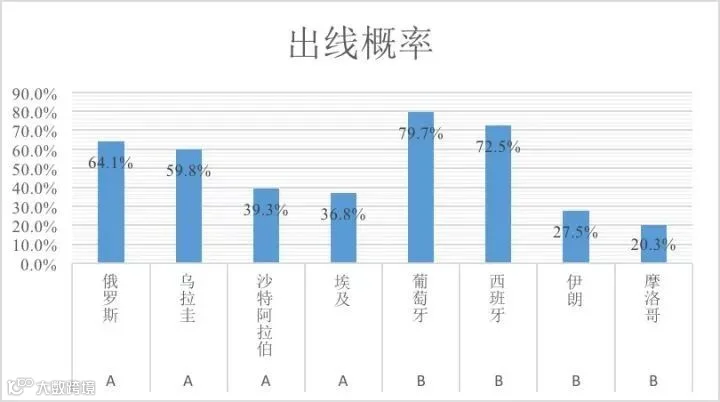
A组B组出线形势
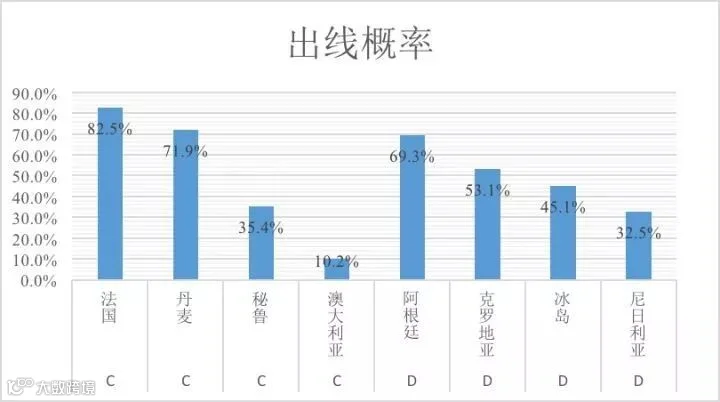
C组D组出线形势
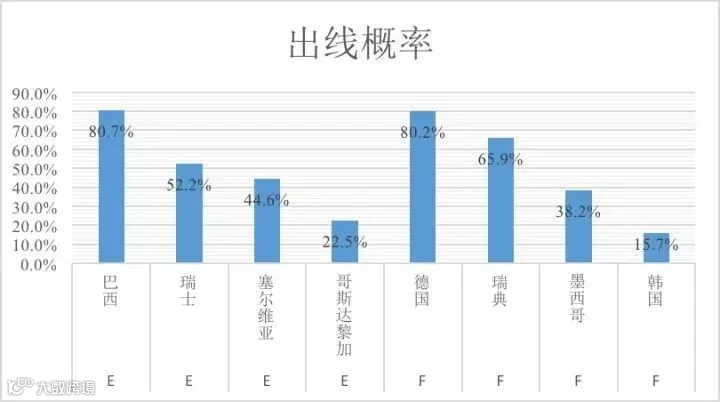
E组F组出线形势
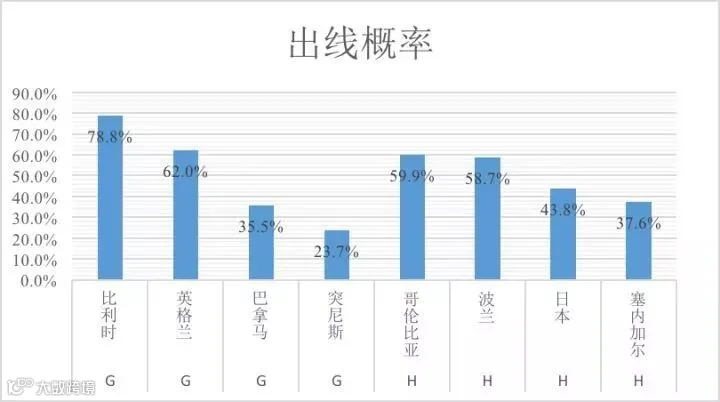
G组H组出线形势
以下是夺冠概率、及打进四强的概率(列出了所有夺冠热门球队):
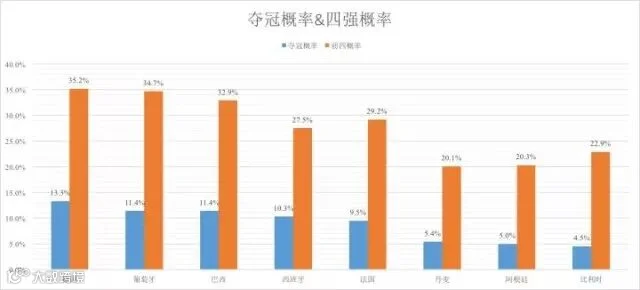
地球是圆的,数据是死的,球迷自己心中的球队夺冠是可能的!世界杯即将打响,让我们拭目以待!

我们对2018世界杯的预测做完了,小伙伴们有没有get到新技能呢?是不是跃跃欲试,想对NBA季后赛、乒乓球联赛、网球赛统统预测一遍?
光复制粘贴长风数据君的代码是远远不够滴,你还需要一款数据挖掘分析神器-PMT。
想要免费获取的小伙伴赶快关注长风大数据微信公众号,在后台回复“PMT”即可获取工具下载权限,工具简单易学,扩展性强,技术小白也可以用呦
声明:微信文章为独家原创,欢迎个人用户分享到朋友圈;其他任何形式的转载,请联系本公号取得授权,否则将追究法律责任。长风大数据(微信号:cf-dsj)隶属于Logis北京络捷斯特科技发展股份有限公司,简称:络捷斯特,证券代码:834832。

长风大数据(微信号:cf-dsj)基于多行业的海量数据资源,为企业运营和院校科研提供先进的数据挖掘分析工具,帮助用户释放数据价值、捕获深层信息。
联系电话:010-65568598转8013
电子邮箱:cfdsj@logis.cn
网址:http://www.cfdsj.cn
长风大数据 ∣一个有逼格的平台

