
经常吃麦当劳的人会有印象:几乎每一个麦当劳店生意都是很火爆的。

选址问题是运筹学中非常经典的问题,是指在规划区域里确定所要分配的设施的数量、位置以及分配方案,使得目标最优。这些设施主要是指物流系统中的节点,如仓库、配送中心、零售网点、制造商、供应商等。
解决复杂选址问题,需要考虑多种因素,如基础设施、物流成本、服务水平,甚至考虑房地产、劳动力成本和战略位置。

如下图所示,根据定性法可以分为专家选择法、层次分析法;定量的方法具体可以分为线性规划法、重心法、聚类方法等。

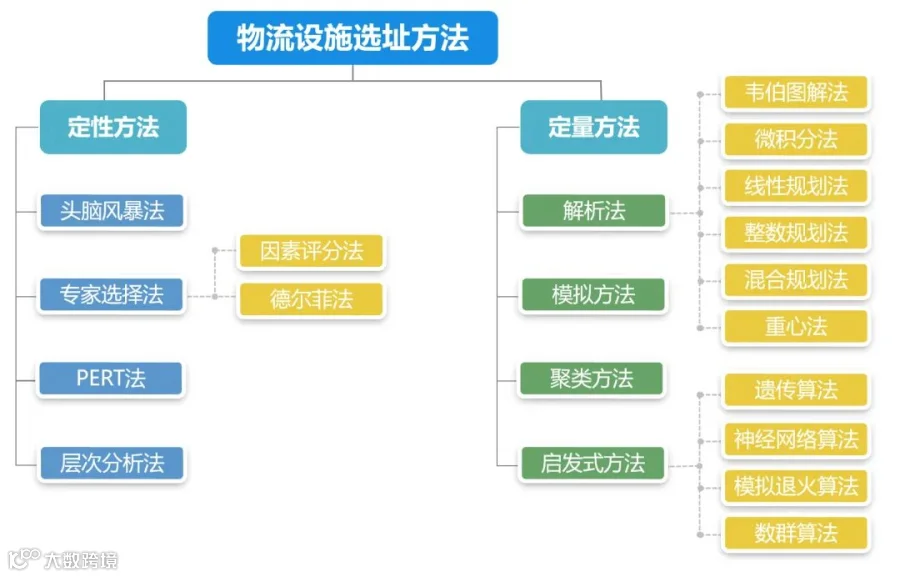
当下,选址已经从“经验时代”转向了“数据时代”,本案例我们利用聚类方法实现配送中心选址分析,并利用“蓝鲸数据挖掘”平台实现基于距离的配送中心(Distribution Center,以下简称DC)选址模型。
1
选址任务
在本案例的研究中,假设其他因素都是固定的,只考虑配送中心距离客户的位置,在此基础上来对选址问题进行分析。
案例假设如下:
1、已知客户的个数和分布位置;
2、已经确定需要的配送中心个数5个;基于以上假设将客户合理分配给配送中心。
2
技术思路
1、首先需要量化地理位置信息量,本案例我们使用处理好的经纬度数据。
2、距离的计算,经纬度能确定一个点,两个点之间的距离是一个很好的量化指标。距离其实有很多计算方式,我们默认的“距离”一般指的是欧式距离,也就是两点的直线距离,对于小范围的选址问题,欧式距离即可求得比较理想的结果。
3、如何确定一个客户属于哪个DC呢?把它分配到离他最近的那一簇里面。距离怎么计算呢?用该客户到这一簇的“均值点”即可。其实就是一个聚类问题,最常见的是K-means。
聚类是指将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。

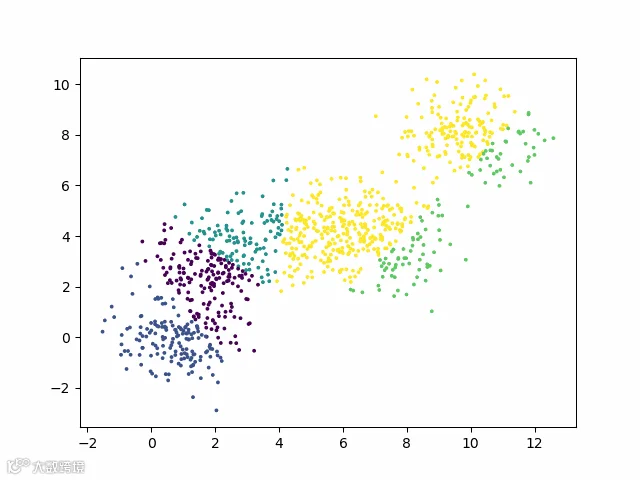

K-means 算法步骤:
Step1:确定初始簇个数K
Step2:选择K个初始质心
Step3:计算所有样本与各质心的距离(本案例为欧式距离)
Step4:就近原则将样本分配到各簇
Step5:重新计算各簇的质心
Step6:重复Step3、Step4、Step5,直到该值小于阈值或达到迭代次数限制。
本案例中我们将K值暂且设定为5。
3
开始实战
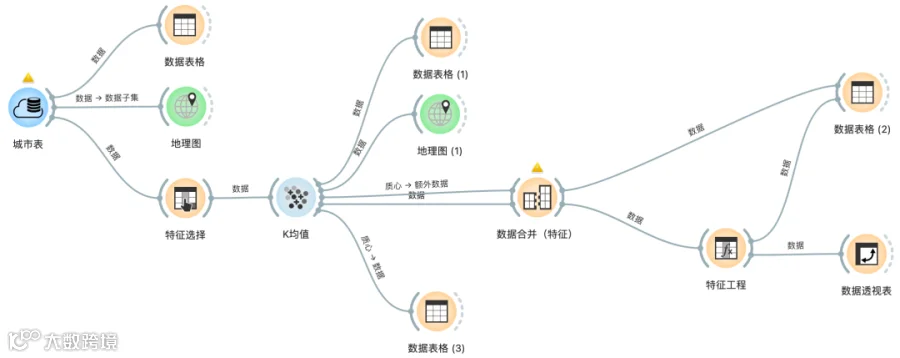
数据分析流程图
1、数据获取与展示
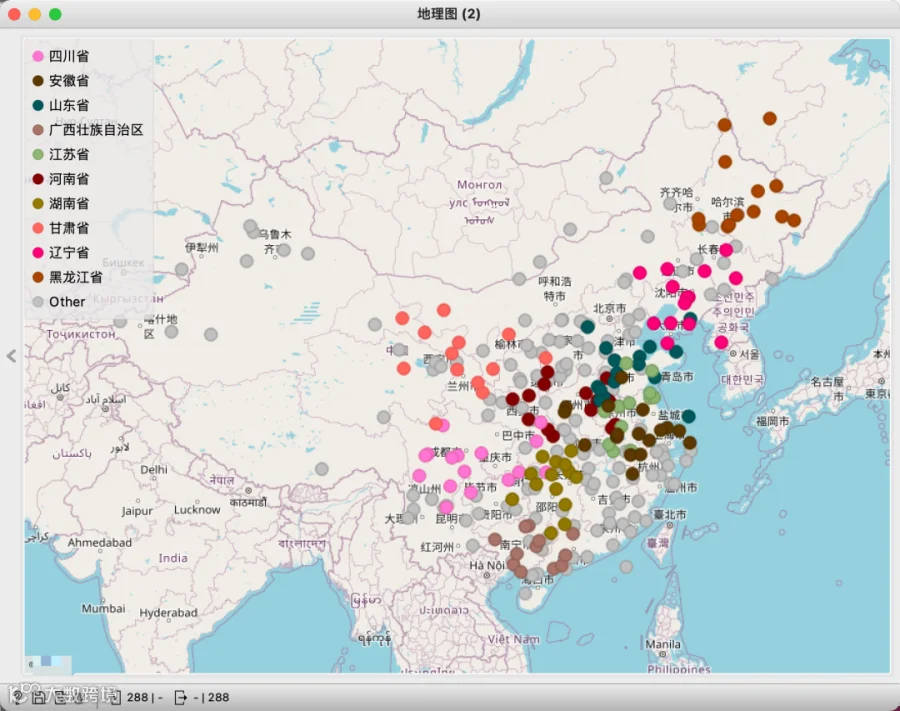
2、聚类实现
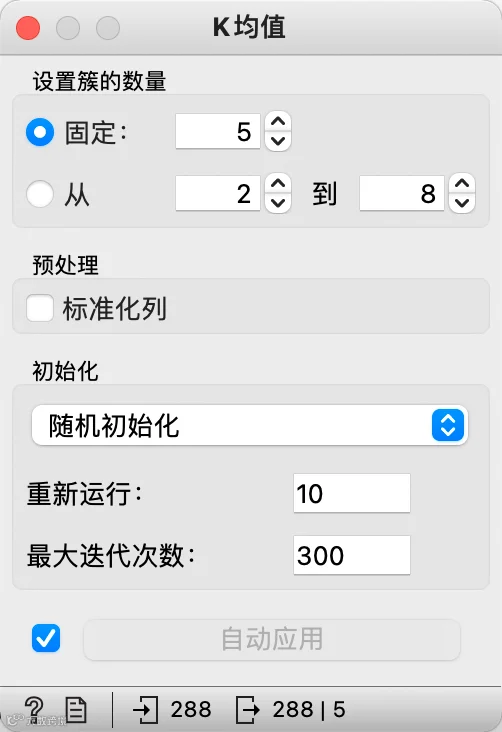
本案例中我们选用地理位置作为聚类的数据,将簇的数量设置为5,关于数量的设置,还可以根据手肘法确定,如设置数量从2~8聚类选择合适的拐点(具体该算法的参数设置我们会另写文章详细介绍,这里不做深究)。
3、结果展示
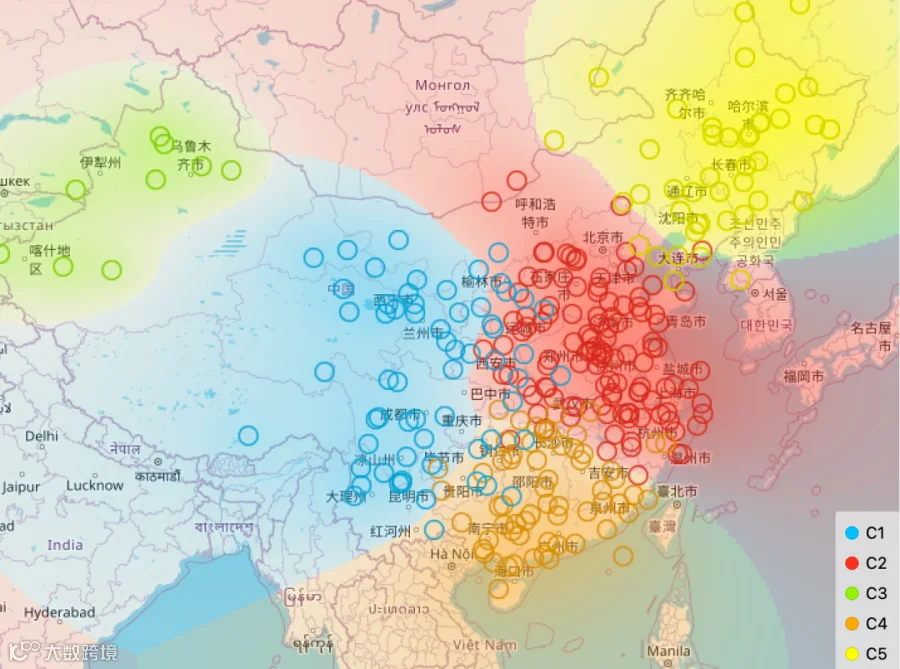
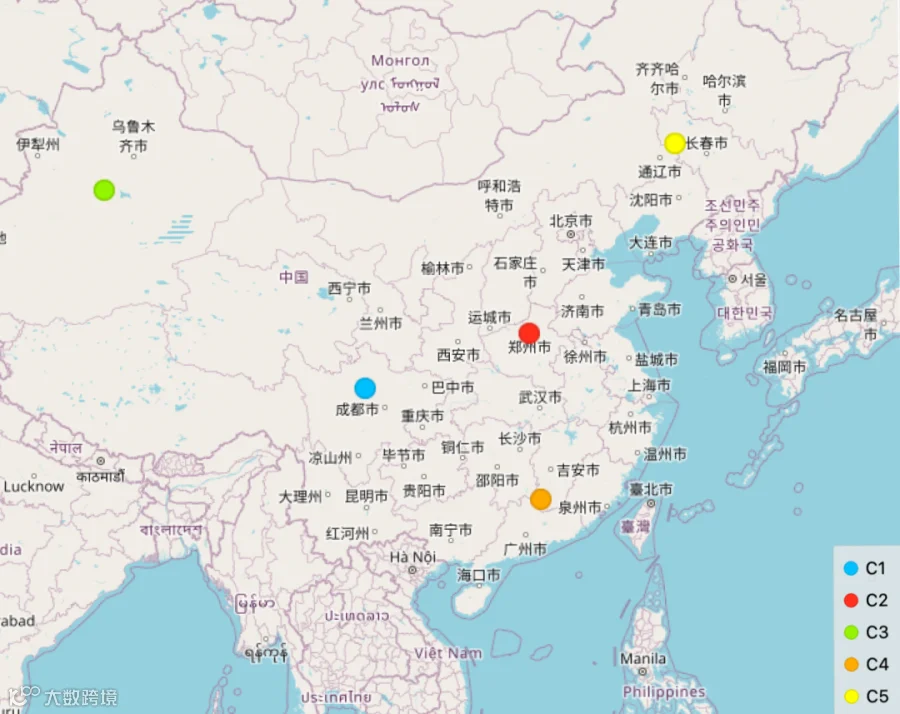
4、配送距离计算
计算出配送中心地址后,我们得到的是经纬度数据,如何计算配送中心到客户的距离呢?还需要将经纬度转化成球面距离。


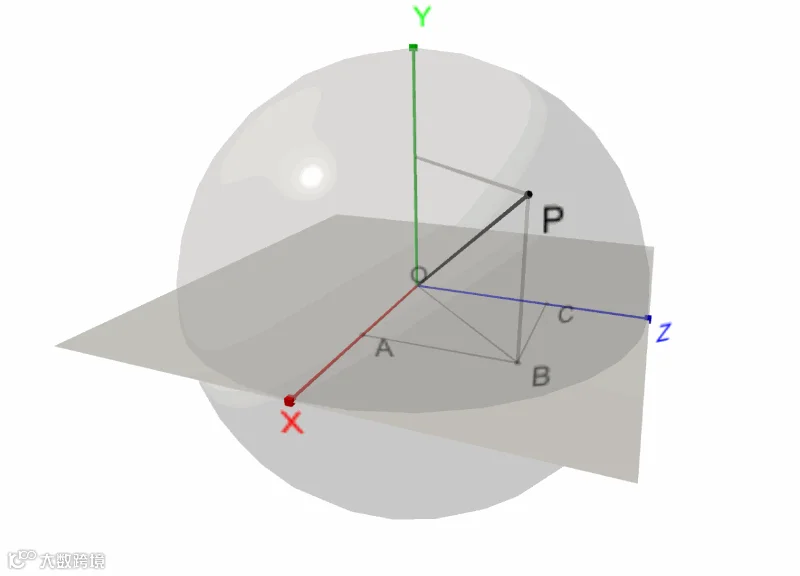
球面距离
简简单单的小公式:
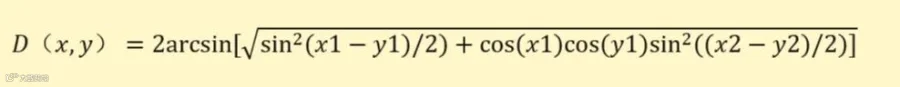
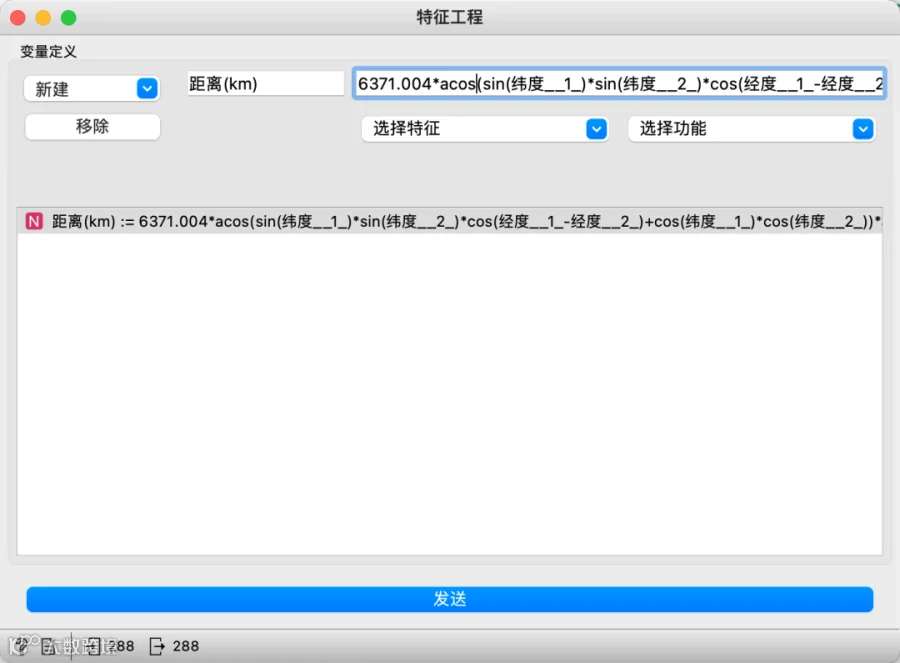
软件中我们可以通过构建特征工程实现:
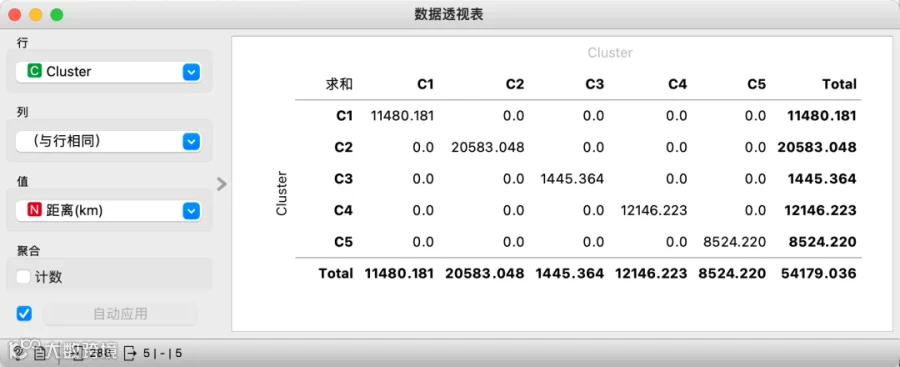
配送中心确定后,整个物流网络中,配送中心到客户的总距离为54179.036km.
4
总结

点击公众号查看更多内容