今日头条在使用 ClickHouse 的过程中遇到了一些问题,从 ClickHouse 迁移到 ByConity 之后获得了更好的性能,同时提高了可靠性和易用性。
本文将分享头条在迁移过程中遇到的挑战,如何成功迁移到 ByConity 以及迁移之后的效果。
ByConity 是 ByteHouse 产品的执行引擎,在字节内部已有大量应用,之前头条内部大概 1/3 的数据分析已经采用了 ByConity 引擎,也算得上是经受住了头条业务的考验。
第一部分,为什么要迁移到 ByConity,通过结合实际业务场景,去看头条这个业务在使用 ClickHouse 中有哪些问题,怎么去解决这个问题。
第二部分,如何迁移到 ByConity。字节内部从 ClickHouse 迁移到 ByConity 的实际方案,以及在迁移过程中遇到哪些问题,怎么去解决这些问题。
第三部分,总结从 ClickHouse 迁移到 ByConity 有哪些受益,通过这些受益可以更直观地体会 ByConity 的优势。
今日头条推荐中最高频用到的数据集就是推荐样本落的风神表(我们称instance表),是实时记录线上每一次展现产生的模型训练样本,每天产生的数据条数有上百亿条,在推荐侧的日常数据查询、实验分析、在离线问题排查中都有着举足轻重的作用。
之前这个风神表一直跑在风神libra公用集群上,集群逐渐不堪重负,每次查询都至少要几分钟,而且失败率很高,严重拖累了推荐同学的工作效率。在24年初的一次oncall中与 ByConity 沟通得知可以迁移至新的cnch集群,可以更灵活地调整负载情况。迁移的过程很顺利,新集群的效果确实也好了很多,满足了头条推荐侧的业务需求。
查询性能瓶颈
查询性能问题是头条业务在使用 ClickHouse 时遇到的最主要的瓶颈。
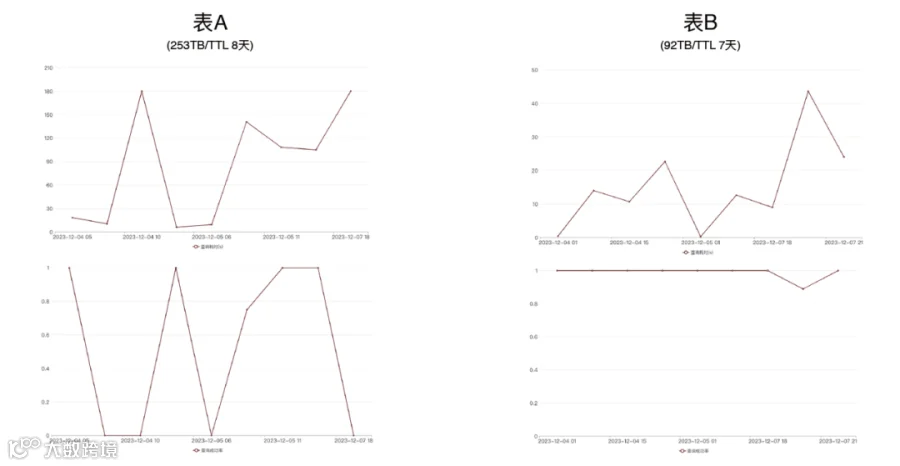
上图中表 A 的生命周期是 8 天,数据量为 253TB,每天的数据函数有 100 亿。左侧下方展示了表 A 查询成功率,从这张图可以看出它的查询成功率经常掉底。左侧上方的图为查询耗时,单位是秒,可以看到查询耗时正常到 180 秒,180 秒是 ClickHouse 查询超时的时间,就是说它经常查询超时。查询成功时,这张表的查询耗时接近 120 秒,这个耗时在 ClickHouse 里已经算是很长了。这张表是业务侧反馈他经常查询不可用,这张表对业务来说也是最重要的一张表,所以我们需要看看这张表怎么优化。
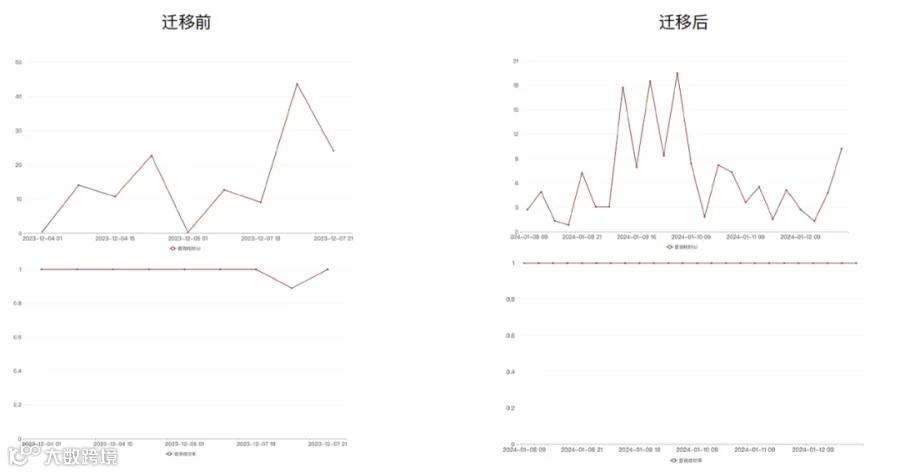
表 B 的数据量大概是表 A 的 1/3,数据量也比较大,生命周期是 7 天。表 B 的查询成功率正常,但查询耗时较高,平均耗时在 15 秒左右。
集群满,扩容困难
使用过 ClickHouse 的同学都会遇到扩容困难这个问题,原因是 ClickHouse 采用的是 shard 架构,数据分布在不同的节点上,不同节点的数据没有交集,导致扩容的时候需要搬迁数据。ClickHouse搬迁存量数据很困难,如果容量即将满的集群在扩容后不搬迁存量数据,老节点的磁盘使用率仍然居高不下,而新写入的数据会均匀落到所有节点,老节点也还是在不停写入数据,就导致老节点的磁盘容易被打满,扩容效果差。
为什么使用 ByConity
为什么可以用 ByConity 来支持这个业务,这里列出了三个主要的 ByConity 优势:
第一,云原生。ByConity 是云原生的,有一系列云原生的特性:
-
一是可以灵活扩缩容。ByConity 的扩缩容是分钟级别的,很灵活、快捷的就可以实现扩缩容。
-
二是实现读写分离和存算分离的架构。相对于 ClickHouse,读和写都是在一个节点上,计算资源和存储资源也是在一个节点上。这样的架构让 ClickHouse 可以达到极致的性能,但我们如果扩缩容,在实际的使用过程中,它会造成资源的竞争和抢占,也会提高用户的使用成本,特别是运维成本特别高。
-
三是租户隔离。ByConity 实现了租户隔离的功能,不同的用户可以灵活地申请自己的计算组,所有的计算组都是隔离的,不会相互影响。
第二,自研表引擎。ByConity 实现了自研的表引擎,可以去更好地支持业务:一是 Unique 唯一键表。它主要的应用场景就是关系型数据库迁移到 ClickHouse 的这种场景,这个场景在我们内部现在有大量的应用。二是 BitEngine 表。如果业务需要用到自研表,我们这个引擎可以提供很大的性能提升。三是其他性能优化。
第三,查询优化器。我们针对复杂查询的场景做了很多的优化,性能提升特别大。
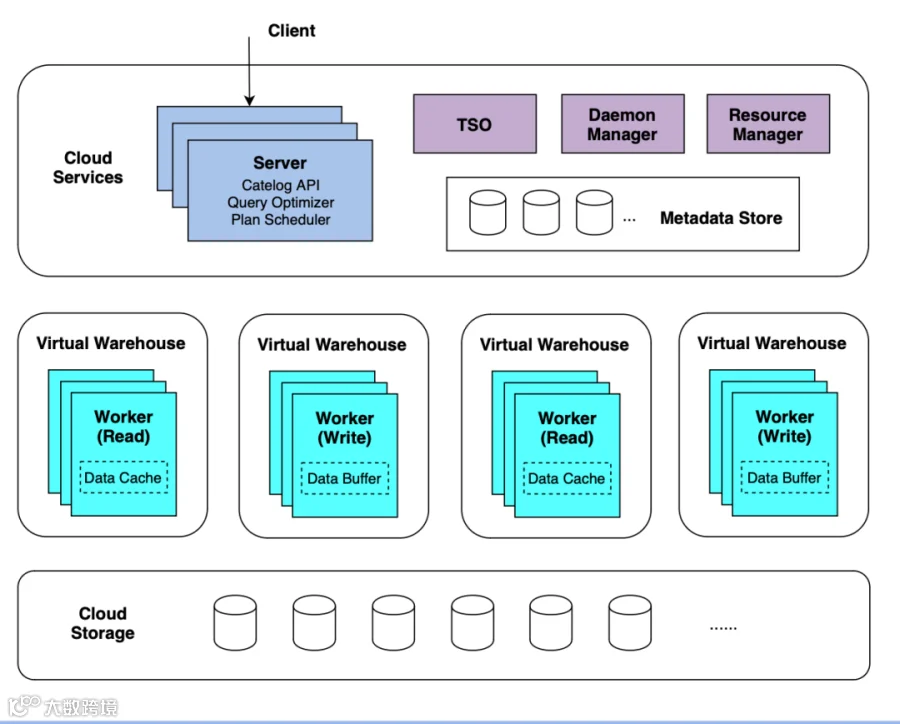
这是 ByConity 的架构。最上面的架构是服务的接收层,里面会做一些 client 接入、任务调度、事务管理、元信息管理。第二层是计算层,这层主要是体现 ByConity 云原生的部分。这里可以看到,有很多计算组,读和写是分开的,实现了读写分离。不同的租户可以申请不同的计算组,实现了租户隔离。第三层是数据存储层,使用的是大数据的数据服务,比如说 HDFS 和 S3,能够实现灵活的扩缩容。通过第二层计算层和第三层存储层,实现了计算和存储分离。
从 ClickHouse 迁移到 ByConity
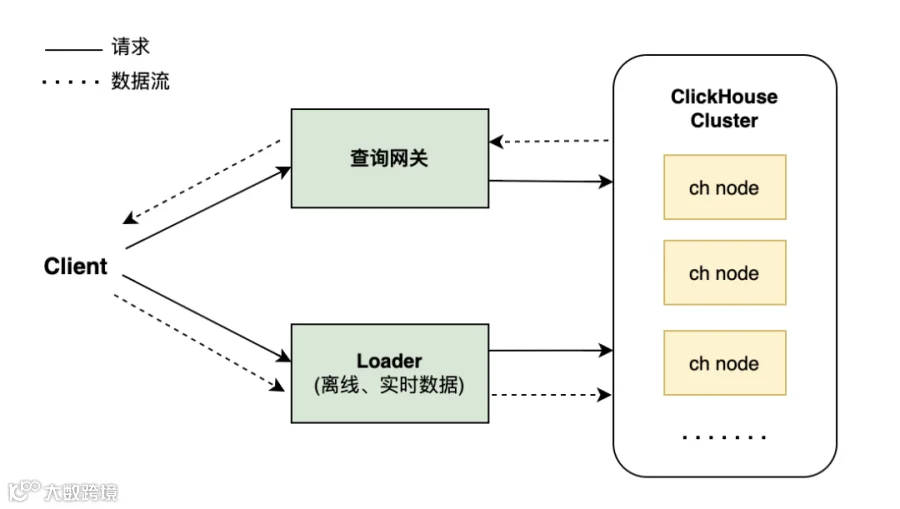
图中右边是 ClickHouse 集群,左边是用户,我们在用户和集群之间做了一个服务平台,用户不会直接连 ClickHouse 集群,都是通过服务平台去接入。在服务平台我们做了一些接入和管控的操作,对用户屏蔽掉了 ClickHouse 集群的一些细节。这里我们将 ClickHouse 集群替换成 ByConity 集群,就可以实现集群的替换。
迁移流程
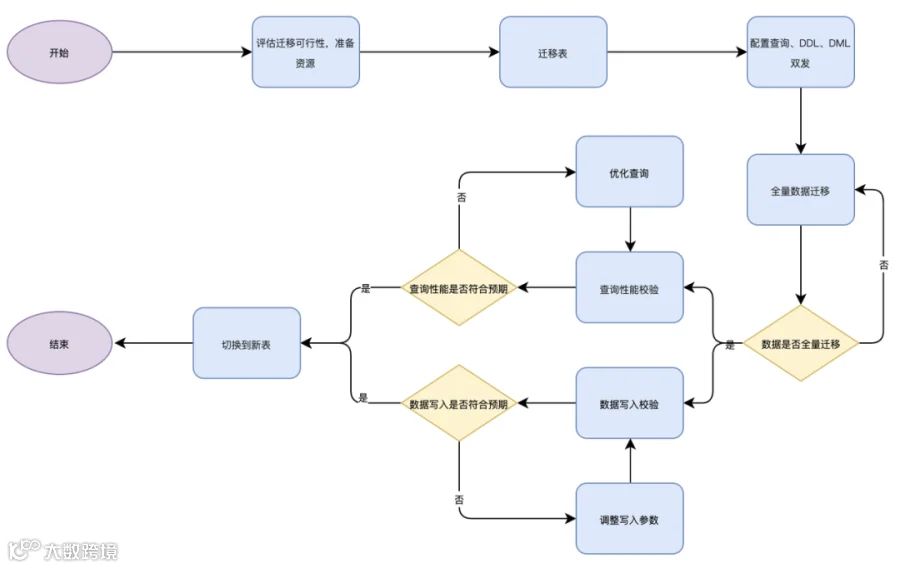
我们首先要评估迁移的可能性,然后准备 ByConity 资源。我们将 ClickHouse 上所有的表结构都迁移到 ByConity 集群上,再配置查询分发以及 DDL 和 DML 分发,这样就可以实现增量数据的同步。实现查询分发之后,也可以到后期方便验证查询有没有问题。之后,我们做存量的全量数据的迁移,存量数据迁移完之后,就会去查询性能和数据写入有没有问题。如果查询性能有问题,我们要单独去优化查询,数据写入也是,有一些优化参数可以去做调整。这块主要是针对一些大数据量的场景会有优化的场景,如果数据量比较小,这块都不需要。最后,我们可以将流量都切换到新表上,再下线旧集群,就完成了整个 ClickHouse 迁移到 ByConity 集群。我们实现了对用户来说是透明、无缝的迁移,用户全程不需要干预进来,可以直接在我们的服务平台上做迁流,对用户来说是无感知的。
迁移中遇到的问题
性能问题
性能问题有以下几点:一是查询 pct 高;二是查询失败率高;三是数据 merge 不过来,导致 parts 多,这也会导致查询 pct 高,任务失败率高;四是数据写入慢。
解决方法有以下几点:一是开启查询优化器。现在我们是默认把查询优化器开启,现在一般都是有很好的优化效果。二是增加计算资源。如果检查出现性能问题,是资源不够的原因,我们直接加资源就可以了,ByConity 加资源现在很方便,直接灵活地加就好了。三是调优 merge 参数。主要是针对一些大表,数据量特别大,merge 不过来。四是调优写入参数。如实时数据写入消费不过来,我们把消费的线程数提高,这是 OK 的。五是开发新功能。如果上面的方法都解决不了,我们也会针对实际的场景,支持一些新的功能、新的性能。
兼容性问题
早期的 ByConity 有比较多的兼容性问题,如 SQL 语法不⽀持,表引擎不⽀持等,目前基本都已解决。如果有兼容性问题,现在属于高优解决。我们在迁移过程中会做一个查询分发,如果有兼容性问题,可以通过查询分发去及时发现,不会影响到业务的实际使用。
迁移到 ByConity 之后,查询性能提升比较明显,主要是表 A。可以看到表 A 的查询成功率已经达到 100%,没有出现掉底的情况。查询耗时也从 120 秒左右提升到 20 秒左右,查询性能提升还是挺大的。
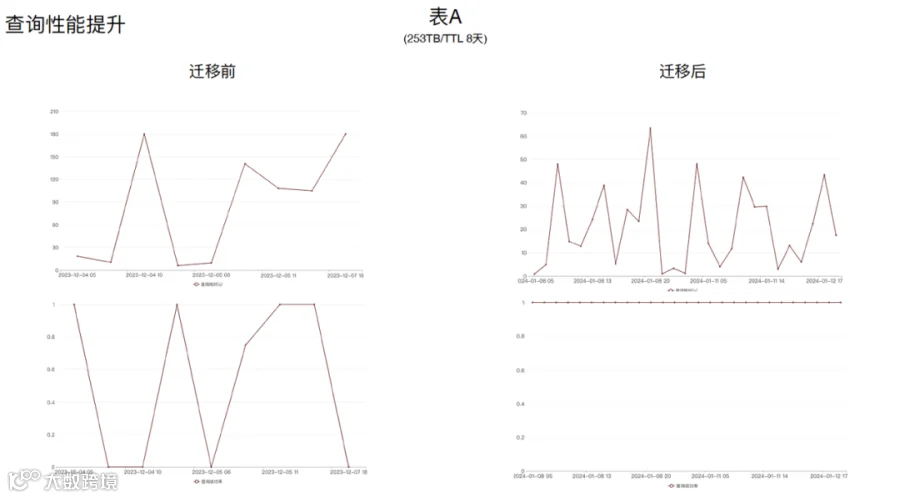
表 B,查询成功率都是 OK 的,查询耗时从 14 秒左右提升到 6 秒左右,提升了接近一倍的性能。
扩容的收益很明显,表 A 在之前集群不能扩容,迁移到 ByConity 之后,生命周期从 8 天扩容到 32 天,数据量增长了 4 倍多,更好地满足了业务的需求。如果是 ClickHouse 集群,则很难去做扩容的。资源由 48 pod 扩容到 80 pod,因为数据量增加了,ByConity 这边是分钟级的扩容,不需要我们去介入,它就直接扩容好了。
成本这块,收益也比较明显,原集群有 74 台物理机,迁移到 ByConity 之后,只用了 48 pod,成本降低了 38.2%。按照我们内部的一些迁移经验,集群迁移到 ByConity 之后,成本一般会降低 30%-50%左右。