
引言:一个“老问题”的新答案
朋友们,大家好。今天咱们坐下来,聊一个在人工智能领域里,尤其是大语言模型(LLM)这个圈子里,最近掀起了一场不小风暴的话题。时间过得真快,转眼已经2026年了。回想几年前,我们还在为GPT-4、Claude 3这些模型的强大能力惊叹不已,但大家心里其实都揣着一个共同的焦虑:这些模型越来越大,越来越“贵”,训练和推理的成本像滚雪球一样,同时,它们在处理和记忆海量静态知识这事儿上,总感觉有点“笨”。
怎么说呢?就好像一个绝顶聪明的学生,每次考试前都得把整本百科全书重新读一遍、理解一遍,而不是直接从脑子里把“法国的首都是巴黎”这个知识点给“调”出来。这种“万事皆计算”的模式,效率显然不高。
就在大家觉得模型发展是不是要撞上“缩放定律”的天花板时,DeepSeek和北京大学在不久前联合扔出了一篇重磅论文,标题有点长,叫《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》(通过可扩展查找实现条件记忆:大语言模型稀疏性的一个新轴心)。
说实话,第一眼看到这个标题,可能有点懵。但别急,我写这篇文章的目的,就是把这篇可能改变游戏规则的论文,用咱们能听懂的大白话,给它掰开了、揉碎了,讲个明明白白。不仅如此,我们还要站在此刻,大胆预测一下,这篇论文给大模型的“记忆”功能捅开了一个多大的天窗,未来的路可能会怎么走。这不仅仅是一篇技术解读,更像是一场关于AI未来形态的思想实验。
01 风暴之眼:为什么“条件记忆”是个颠覆性的想法?
要理解这篇论文的颠覆性,咱们得先搞清楚它想解决的根本问题,以及它提出方案之前,大家都是怎么干的。
旧时代的“奢侈”:当计算成为一种肌肉记忆
传统的大语言模型,比如Transformer架构,它的核心是什么?是注意力机制(Attention)。你可以把它想象成一个极其复杂的“关系探测器”。你给它一句话,它内部的神经元就会疯狂计算每个词和另外所有词之间的关联强度。这种机制赋予了模型强大的上下文理解和推理能力,但代价也是巨大的。
打个比方,当模型处理“中国的首都是哪里?”这个问题时,它并不是像我们人类一样,直接从记忆库里提取“北京”这个答案。它的内部运作更像是:通过海量的计算,分析“中国”、“首都”这些词在训练数据里最常和哪个词(比如“北京”)以一种特定的模式共同出现,然后“推理”出答案是“北京”。对于这种已经成为“常识”的、固定不变的知识,每次都这么大动干戈地算一遍,是不是有点浪费电?
这就引出了一个核心矛盾:模型的参数量越来越大,其中很大一部分其实是用来“硬背”这些静态知识的,但调用这些知识的方式,却又是极其低效的“重复计算”。
第一次尝试:聪明的“分包商”——混合专家模型(MoE)
为了解决这个效率问题,研究者们想出了一个好办法,叫做“混合专家模型”(Mixture-of-Experts, MoE)。这个想法很直观,既然一个大模型干所有活太累,那就把它拆成一群“小专家”。
想象一下,你有一个庞大的工程项目,你可以雇一个无所不能的全才,也可以雇一堆专才:一个管电工,一个管水暖,一个管砌墙……再配一个聪明的“路由门卫”,来活儿了,门卫一看,“哦,这是个电路问题”,就把任务直接分发给电工专家。这样,每次只有一个或几个专家在干活,其他专家都在“待机”,整体的计算量就下来了。
MoE就是这个思路。它把模型的前馈网络层(FFN)拆分成很多个“专家网络”,每次处理一个token时,一个“门控网络”(Gating Network)会决定激活哪个专家来处理。这就是所谓的“条件计算”(Conditional Computation)。也就是说,计算是根据输入条件动态选择的,实现了计算上的稀疏性。
MoE在很长一段时间里都是稀疏化模型的主流,也确实取得了巨大的成功。但是,它并没有从根本上解决我们前面提到的那个问题:无论是全才来算,还是专家来算,对于“法国首都是巴黎”这种固定知识,它本质上还是在“算”,而不是在“查”。 它只是让“算”这个动作变得更有效率了而已。
划时代的呐喊:“查—算分离”与“条件记忆”的诞生
终于,我们来到了这篇论文的核心。DeepSeek和北大的研究者们提出了一个振聋发聩的新思想:我们为什么非得死磕“计算”这条路呢?能不能开辟一条全新的赛道?
他们说,模型的智能,应该由两个部分组成:一部分负责动态的、复杂的、需要逻辑推理的计算;另一部分,则负责静态的、模式化的、高频出现的记忆。这两部分应该解耦,各司其职。
这就是“查—算分离”(Lookup-Compute Separation)的核心哲学。
基于这个哲学,他们提出了一个与“条件计算”(MoE)并列的、全新的稀疏性维度——“条件记忆”(Conditional Memory)。
- 条件计算(MoE):是激活路径的稀疏。像一个开关网络,决定哪条计算电路通电。
- 条件记忆(Engram):是记忆访问的稀疏。像一个巨大的图书馆,只有当你需要查某本书的某一页时,才会去翻它。
这个想法,在我看来,是真正意义上开始模仿生物大脑工作方式的一次重要尝试。我们的大脑里,既有负责逻辑推理的前额叶皮层,也有负责储存长期记忆的海马体和新皮层。我们解决一个复杂问题时,是推理能力和记忆提取能力的协同作战。
而这篇论文,就是为大语言模型设计了一个类似“海马体”的外部记忆模块。这个模块,他们取名为Engram,中文可以翻译成“印迹”,一个神经科学里的术语,指记忆在脑中留下的物理痕跡。这个名字起得真是绝了,充满了对生物智能的敬意和模仿的野心。
所以,这篇论文的颠覆性在于,它不再满足于在“如何更有效地计算”上做文章,而是直接开辟了一个新的战场:“如何更有效地记忆和查询”。它为模型设计引入了一个全新的、与计算正交的稀疏化维度,这无疑是一次范式转移。
02 深入“印迹”(Engram):这个“外挂记忆库”到底是怎么工作的?
好了,宏大的叙事讲完了,我们现在就撸起袖子,钻到Engram这个模块的内部,看看它的“三头六臂”究竟是什么。我会尽量用最简单的比喻来解释。
核心设计:一个巨大无比的“键值对”字典
Engram模块的本质,其实非常朴素,你可以把它理解成一个巨大无比的、可扩展的字典,或者叫键值对(Key-Value)记忆表。
- 键(Key):就是我们要查找的“索引”或者“词条”。
- 值(Value):就是这个词条对应的内容。
举个例子,一本《新华字典》,它的“键”就是拼音或者部首,它的“值”就是那个字的解释、用法等。
Engram也是一样。它存储了海量的“模式”或“知识片段”。当模型在处理文本时,遇到一个它认识的“模式”(键),就直接去这个大字典里把对应的内容(值)给取出来用,省去了自己从头计算的麻烦。
那么问题来了,这个字典的“键”和“值”具体是什么?又是怎么实现快速查找的呢?
“键”的奥秘:哈希N-gram,给知识片段一个“身份证号”
Engram是怎么识别出文本中那些它“认识”的模式的呢?答案是哈希N-gram。
我们一步步拆解:
-
1. N-gram:这个很简单,就是文本中连续的N个词(或token)。比如“the capital of France”这句话里,如果我们取N=4,那么“the capital of France”就是一个4-gram。如果我们取N=2,那么“the capital”、“capital of”、“of France”都是2-grams。这些N-grams就构成了我们知识库里最基本的“模式单元”。 -
2. 哈希(Hashing):N-gram是文本,计算机处理起来不方便,而且直接用文本做索引会非常慢。所以需要一个“哈希函数”,把这些文本N-gram转换成一个独一无二的数字ID,就像给每个N-gram办一个“身份证号”。比如,"the capital of France" 经过哈希函数一算,可能就变成了数字58392048。这个数字就是我们在Engram大字典里要查找的“键”。
这种方法的好处是,查找速度极快。基于哈希表的查找,其理论上的时间复杂度接近O(1),意思就是不管你这个字典有多大,我找到一个词条需要的时间几乎是固定的,不会因为字典变大而变慢。这对于一个动辄可能包含万亿级别知识片段的记忆库来说,简直是性能上的生命线。
论文里还提到了“多头哈希”(multi-head hashing),这可以理解为为了防止“哈希冲突”(两个不同的N-gram算出了同一个身份证号)并且增加模型的表达能力,我们不用一个哈希函数,而是用好几个不同的哈希函数,给同一个N-gram生成好几个不同的“身份证号”,从不同的角度去记忆库里查找信息,最后再把找到的信息整合起来。
“值”的内涵:不是原始文本,而是浓缩的“知识嵌入”
找到了“键”,那我们从记忆库里取出来的“值”是什么呢?是“Paris”这个单词吗?
不是的。如果只是简单地存取文本,那这个模块的想象力就太有限了。Engram里存储的“值”,是一个高维向量,我们称之为“嵌入”(Embedding)。
这个向量,是模型在训练过程中学习到的、对那个N-gram后面应该接什么内容的一种高度浓缩的、数学化的表达。它包含了极其丰富的语义信息。比如,对应于“the capital of France”这个键的那个值向量,它在向量空间里的位置,可能就和代表“Paris”的向量,以及代表“Eiffel Tower”、“Louvre”等相关概念的向量非常接近。
当模型把这个“值”向量取出来之后,会把它和自己当前的内部状态(也就是Transformer层的隐藏状态)进行融合。这个过程,你可以想象成:模型本来正在自己琢磨,“‘法国的首都是’...后面该接啥呢?”,这时候Engram外挂突然递过来一张小纸条(那个值向量),上面写满了关于“巴黎”的各种线索和提示。模型一看,“哦!原来是这个意思!”,瞬间就明白了,然后把这些线索融入到自己后续的思考和生成过程中。
工作流程:一场“计算”与“查找”的无缝协作
现在,我们把整个流程串起来,看看Engram是怎么和Transformer主干网络打配合的:
-
1. 输入文本:模型拿到一段输入文本,比如“I traveled to the capital of France last year”。 -
2. 并行处理:文本被送入两个并行的路径: - 计算路径:常规的Transformer层开始工作,通过自注意力机制分析整个句子的语法结构、长距离依赖等复杂关系。
- 查找路径:同时,文本里的N-grams(比如“the capital of France”)被提取出来,经过哈希处理,变成一个个“键”。
-
3. 记忆查找:Engram模块拿着这些“键”,去它那巨大的记忆库里进行超高速查找。 -
4. 信息融合: - 如果某个N-gram在记忆库里找到了对应的值(一个知识向量),这个向量就会被取出来。
- 如果没找到(说明这是一个模型没见过的、或者不认为是固定模式的短语),Engram就啥也不干。
-
5. 输出决策:取出的知识向量,会与Transformer计算路径的输出结果进行融合。这个融合后的信息,再送给模型的下一层进行处理。
看到了吗?这就是“条件记忆”的精髓所在。“条件”就体现在第四步:只有当输入的模式能够匹配到记忆库里的键时,记忆才会被激活和调用。对于那些需要灵活推理、没有固定答案的复杂上下文,模型就完全依赖自己的“计算”大脑。
而“可扩展性”(Scalable)则体现在,这个Engram记忆库的大小,可以和Transformer计算部分的参数量脱钩。我可以让模型的计算核心(比如4B参数)保持不变,但把它的记忆库从100GB扩充到1TB。这就像给一个聪明的大学生配一个越来越大的图书馆,他的知识量可以无限增长,而他本人的“智商”(计算能力)不需要改变。这在模型迭代和知识更新上,带来了巨大的想象空间。
03 是骡子是马,拉出来遛遛:实验结果说了什么?
理论说得天花乱坠,最终还得看疗效。DeepSeek的团队用详尽的实验数据,证明了Engram架构不是花架子,而是实打实的能打。
性能大比拼:同等投入,更高产出
实验的核心思路是“公平对决”。他们设置了几个不同规模和架构的模型,比如:
- Dense-4B:一个传统的、40亿参数的密集型模型。
- MoE-27B:一个总参数270亿,但每次计算只激活一小部分的MoE模型。
- Engram-27B:一个参数规模和计算量与MoE-27B相当,但把一部分资源从“计算专家”挪到了“记忆库”上的Engram模型。
结果怎么样呢?一句话总结:在参数总量和计算量(FLOPs)大致相同的情况下,Engram模型在很多关键任务上,都显著优于纯MoE模型,甚至能和更大规模的模型掰手腕。
具体来说:
- 知识密集型任务:在需要精确调用事实知识的问答、阅读理解等任务上,Engram的优势尤为明显。这完全符合我们的直觉,因为它就是为此而生的。
- 推理、代码和数学:更让人惊喜的是,在这些普遍被认为更依赖“计算”和“逻辑”的任务上,Engram模型也表现出了强大的竞争力,甚至超越了MoE基线。这说明,“查—算分离”不仅没有损害模型的推理能力,反而可能因为减轻了计算核心记忆知识的负担,让它能更专注于复杂的逻辑推演。
解锁长上下文新姿势
还有一个非常有意思的发现,Engram显著提升了模型处理长上下文的能力,尤其是在大海捞针式的长文检索任务(Needle-in-a-Haystack)上。
这个背后的道理也挺巧妙的。我们知道,Transformer的注意力机制虽然强大,但它的“注意力”是有限的。当文本变得非常长时,它很难同时关注到所有细节。
而Engram的引入,相当于给注意力机制“减负”了。对于文本中那些局部的、固定的、模式化的依赖(比如“A is B”这种事实性短语),Engram通过查找直接搞定了。这样一来,宝贵的注意力资源就被释放了出来,可以更专注于去捕捉那些全局的、跨度非常大的、真正需要深度理解的上下文关联。
打个比方,你在读一篇万字长文写一份报告。如果文章里所有的人名、地名、专业术语你都烂熟于心(就像Engram一样可以直接“查”到),你就可以把全部精力放在梳理文章的整体逻辑脉络和核心论点上。反之,如果你每看到一个术语都得停下来想半天它是啥意思,你的精力就会被这些局部信息严重分散,很难把握全局。
揭示“U型缩放定律”:记忆与计算的最佳平衡点
这篇论文还有一个非常重要的理论贡献,就是揭示了神经计算(以MoE为代表)和静态记忆(以Engram为代表)之间的一个“U型缩放定律”。
这是什么意思呢?
想象一下,你现在有一笔固定的“模型资源预算”。你可以把这笔预算全部用来堆计算单元(更多的MoE专家),也可以全部用来堆记忆单元(更大的Engram记忆库),或者在两者之间做一个分配。
研究者们通过实验发现,性能并不是随着你把资源压在哪一边而线性提升的。
- 如果你只堆计算,不堆记忆(纯MoE),模型可能很会“思考”,但知识储备不足,巧妇难为无米之炊。
- 如果你只堆记忆,不堆计算,模型可能像一本死记硬背的字典,知识渊博但缺乏灵活的推理和泛化能力。
最佳的性能,出现在计算资源和记忆资源达到一个特定比例的平衡点时。如果你把性能作为Y轴,把资源分配比例(从100%计算到100%记忆)作为X轴,画出来的曲线会呈现一个“U”型(或者说是倒U型,取决于你怎么定义Y轴)。这个“U”的谷底,就是性能的巅峰。
这个发现的意义极其重大。它告诉我们,未来的大模型设计,不再是单维度地追求更多参数或者更多专家,而是在“计算-记忆”这个二维空间里寻找最优的资源配置。这为稀疏化大模型的架构设计提供了一个全新的、极其宝贵的指导原则。
04 未来已来:大模型记忆功能的演进之路狂想曲
好了,论文本身的内容我们基本聊透了。现在,让我们戴上“未来学家”的帽子,站在2026年的今天,基于“条件记忆”这个火种,来一场关于LLM记忆功能未来的“头脑风暴”。在我看来,这条演进之路,可能会分这么几个阶段:
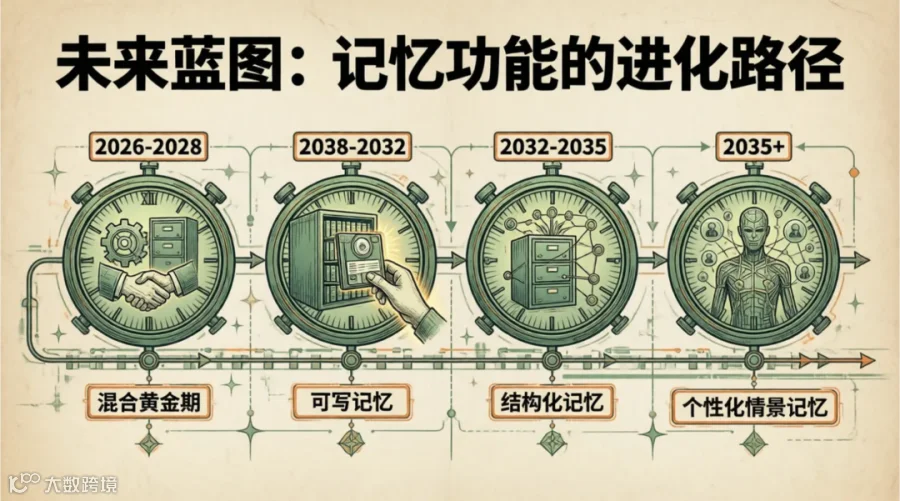
第一阶段(现在-2028年):混合架构的黄金时代
这是最显而易见的趋势。既然“U型缩放定律”告诉我们计算和记忆的结合才是王道,那么下一代的主流模型架构,几乎必然会是MoE(条件计算)和Engram(条件记忆)的混合体。DeepSeek自己也说了,Engram将是他们下一代模型(如V4)的核心技术基础。
我们可以想象,未来的LLM会像一个“超能学霸”。它的大脑里,既有一群负责数理化、文史哲的“专家博士”(MoE),还有一个容量堪比整个互联网、查找速度快如闪电的“超级记忆宫殿”(Engram)。
这种混合模型将在两个方面带来质变:
-
1. 能效比:在同等效果下,模型的训练和推理成本将大幅下降。AI普惠化的进程会大大加速。 -
2. 能力边界:模型将同时擅长需要严谨逻辑的推理任务和需要海量知识支撑的生成任务,成为真正的“通才”。
第二阶段(2028年-2032年):可写的、动态更新的记忆
目前论文里描述的Engram,它的记忆库主要是在训练阶段形成的,相对是静态的、只读的。这就像我们上学时背的课本,一旦印刷出版,内容就固定了。这就导致了LLM一个经典的老毛病:知识截止日期。
那么,下一步的进化,必然是让这个记忆库变得动态可写、实时更新。
这会是什么样的场景?
- 实时学习:模型读了一篇今天早上刚刚发布的新闻,能立刻把其中的核心事实(比如某公司发布了新产品、某项政策出台)自动解析、提炼,并作为新的“键值对”写入自己的Engram记忆库。下一次你问到相关问题时,它就能给出最新的信息,彻底告别“我的知识截止到XXXX年”这种尴尬的回答。
- 知识的“热插拔”:我们可以为模型打造各种专业的“记忆插件包”。比如,给一个通用模型“插入”一个完整的医疗知识图谱Engram模块,它就瞬间变成一个医疗问答专家。明天需要它做法律咨询,再换上法律领域的记忆模块。知识的更新和定制化将变得前所未有的灵活。
这在技术上,其实是把现在流行的RAG(检索增强生成)思想,以一种更原生、更高效的方式,深度集成到了模型的核心架构里。RAG是在模型外部做检索,而未来的动态Engram则是在模型内部完成记忆的读写,效率和融合度不可同日而语。
第三阶段(2030年-2035年):分层、关联与因果记忆
人类的记忆系统,远比一个扁平的“键值对”字典要复杂。我们的记忆是有层次的、相互关联的,并且包含了因果逻辑。
比如,我们记住“苹果会从树上掉下来”,这不仅仅是一个事实,我们还知道它背后的原因是“万有引力”。我们知道“巴黎”和“法国”是“首都-国家”的关系,和“埃菲尔铁塔”是“城市-地标”的关系。这些知识在我们的脑中是以一张复杂的关系网络(知识图谱)存在的。
因此,LLM记忆的第三阶段进化,我预测是从“事实记忆”走向“结构化记忆”。
Engram的形态可能会发生改变:
- 从扁平KV到图结构:记忆库的底层结构可能不再是简单的键值表,而是一个庞大的知识图谱。模型查找的不再是孤立的N-gram,而是在这个图谱上进行推理和漫游(multi-hop reasoning),从而发现更深层次的关联。
- 因果记忆的萌芽:模型不仅能记住“A发生了”,还能学习和存储“因为B,所以A发生了”。这将是模型迈向真正理解世界、具备初级常识推理的关键一步。
到那时,你问模型一个问题,它的回答可能不再是基于概率的文本拼接,而是基于内部知识图谱的一条清晰的、可解释的推理链。这对于AI在科研、教育、决策支持等严肃领域的应用,将是革命性的。
第四阶段(2035年及以后):个性化、情景与自我记忆的诞生
这是最激动人心,也可能是最富争议的终极阶段。目前的记忆,无论是事实还是结构,都属于“语义记忆”(Semantic Memory),即关于世界的一般知识。但人类还有一种更重要的记忆,叫做“情景记忆”(Episodic Memory),即关于个人经历的记忆,“我昨天晚饭吃了什么?”“我上周和谁聊过天?”。
LLM记忆的终极形态,必然要走向个性化和情景化。
这意味着:
- 拥有个人历史:AI助手将拥有与特定用户交互的完整记忆。它会记得你所有的偏好、之前的对话、你的工作项目、你的家人朋友……它不再是一个对所有人都说一样话的通用模型,而是真正属于你的、独一无二的“个人AI”。
- 上下文的无缝延续:你可以随时中断和它的任何对话,几天后再回来,它能立刻接上之前的话题,因为它记得你们聊到哪里了。这种跨越时间维度的长期、稳定上下文,将彻底改变我们与AI的协作方式。
- “自我意识”的雏形?:当一个模型开始拥有关于“自己”与“外部世界(用户)”交互的连续记忆时,它是否会开始形成某种初级的“自我模型”?这是一个深刻的哲学问题,但从技术演进上看,似乎是难以避免的方向。
当然,这一阶段会带来巨大的技术挑战和伦理隐私问题。如何安全地存储和管理个人记忆?如何防止记忆被滥用?这些问题的重要性,将不亚于技术本身。
写在最后:一小步,一大步
回到我们今天讨论的这篇论文。DeepSeek和北大的《Conditional Memory via Scalable Lookup》,它所做的,可能看起来只是在庞大的模型架构里增加了一个新的模块。但从更宏大的视角看,它完成了一次关键的“思想破冰”。
它告诉整个AI社区:不要只在“计算”的道路上内卷,旁边还有一片名为“记忆”的广阔新大陆等待开垦。它提出的“查—算分离”哲学,以及对“计算-记忆”U型缩放定律的揭示,为我们绘制了探索这片新大陆的初步地图。
从静态的事实记忆,到动态的实时记忆,再到结构化的关联记忆,最终到个性化的情景记忆——这条演进之路,每一步都充满了挑战,但更充满了无限的可能性。
2026年的今天,我们或许正站在一个新时代的开端。这个时代,AI不再仅仅是一个强大的计算器或推理机,它将开始拥有真正意义上的、可扩展的、可演化的“记忆”。而拥有了记忆的智能,才更接近我们所理解的“生命”的形态。这篇论文,无疑是朝那个方向迈出的,坚实而又优雅的一大步。

—— END ——
(都看一年了,还不关注我们吗 ?小心别在数字洪流中掉队哦 ↓)
往期回顾:
2. CES 2026:当“预言”照进现实,一个AI原生纪元的全面降临
4. 2026开年巨献:DeepSeek的新架构默默给AI“地基”动了刀
5. 2025最后一天:别聊AI了,聊聊我们和它挤在同一屋檐下的这一年