


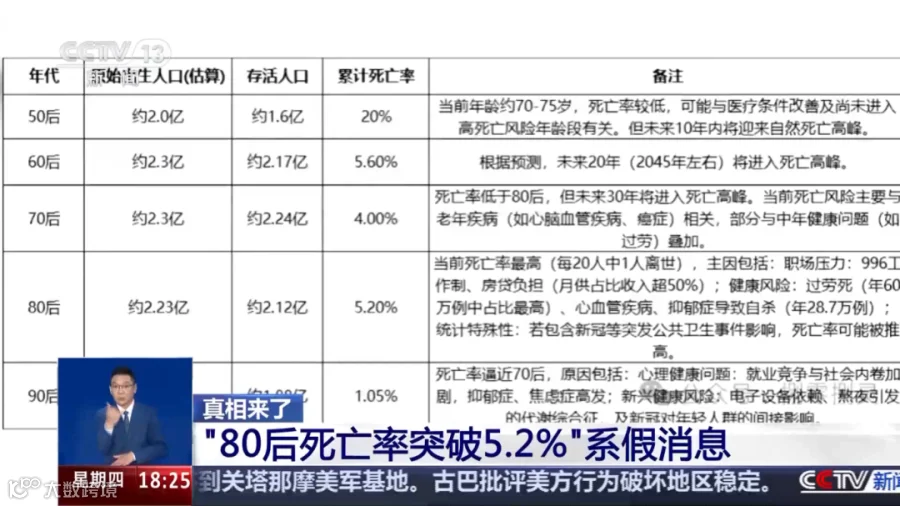


错误死亡率源头可能为“AI运算偏差”

错误死亡率源头可能为“AI运算偏差”




AI生成虚假信息,
AI的研发者和使用者是否要承担法律责任?
网络平台在发现谣言传播后,
应该履行怎样的责任义务“止谣”?
为规范AI生成信息传播,
亟待完善的法律法规和监管措施有哪些?
通化市互联网违法和不良信息举报方式
①举报电话:0435-3951710
②举报邮箱:thsjbslzx@163.com
③网上举报:关注“网信通化”微信公众号,选择“举报专区”,点击相应类别进行举报

