

今天一早,雷军在微博宣布:小米 MiMo-V2.5 系列做了一次大幅度的价格调整,最高降幅达到 99%,不再区分上下文窗口。小米技术随后发布正式公告,北京时间 5 月 27 日 0:00 起全球同步生效。
消息一出,技术群里马上有人在问:"降了多少?实际多少钱?对做 AI 编程的有多大影响?"我翻了一圈报道,结合这个模型本身的实力数据,把关键信息整理出来了。
发生了什么
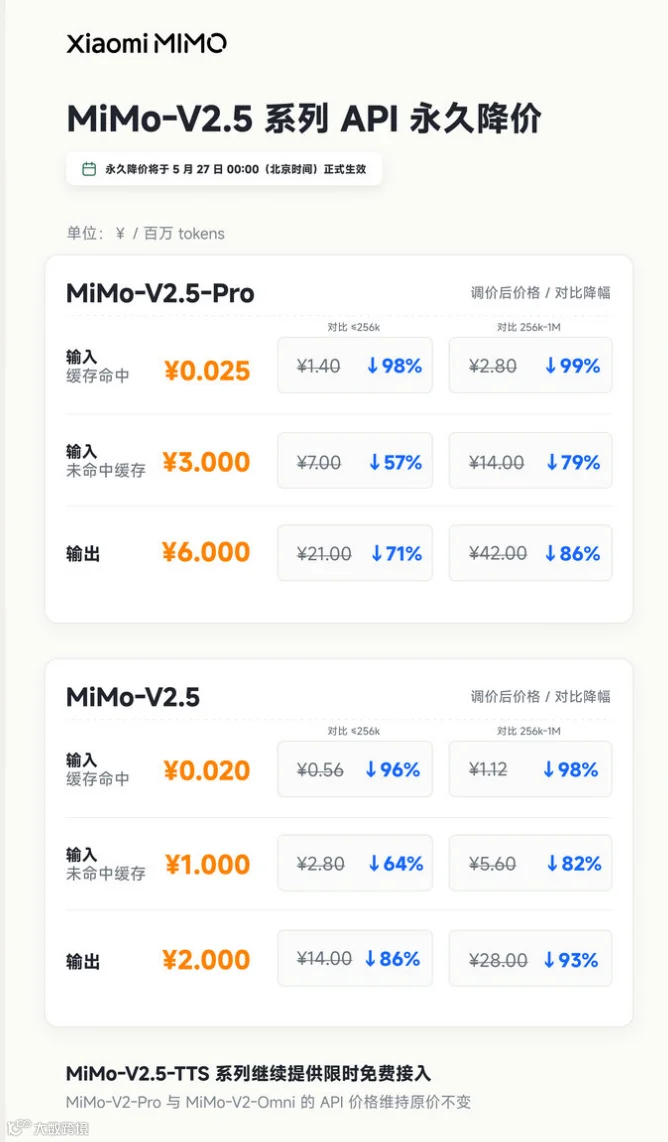
小米 MiMo-V2.5 系列 API 于昨天凌晨正式永久降价,全球同步。相比原始 API 定價,新定價最高降幅可达 99%,且不再区分上下文窗口长度。这也是继 DeepSeek 之后,又一家宣布 API 永久降价的大模型公司。
此前几天,DeepSeek 刚刚宣布 V4-Pro 模型 API 将于 5 月 31 日结束 2.5 折优惠后永久调整为原价的 1/4。小米此次降价直接把价格拉到同一水位线,而且生效时间比 DeepSeek 的 5 月 31 日更早——就是昨天。
具体价格
以下是两个主力模型的完整调价表格,数据来自小米官方公告(36氪、界面新闻报道):
MiMo-V2.5-Pro(旗舰编程 Agent 模型)
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MiMo-V2.5(全模态通用 Agent 模型)
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
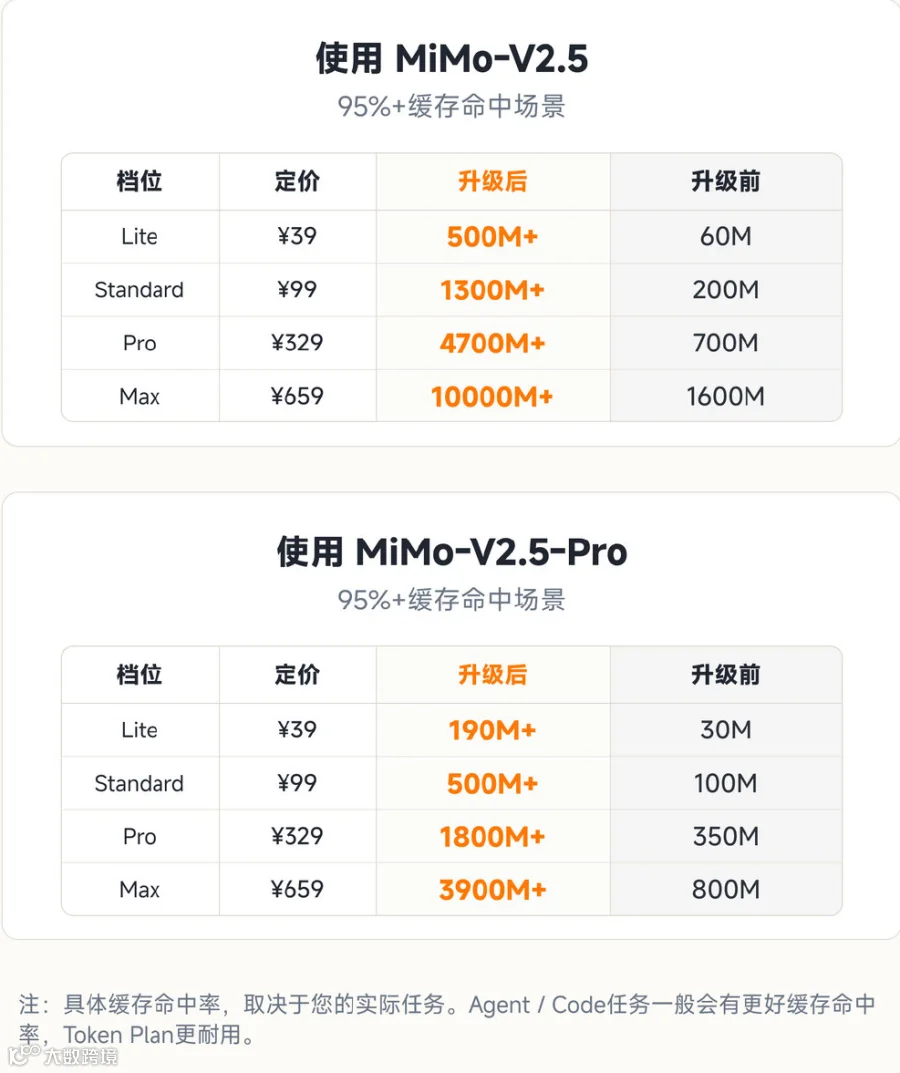
缓存命中这个场景的价格降幅最猛——Pro 版从最高 2.80 元直接砍到 0.025 元,降幅 99%。这个数字是实打实的。
几个关键变化
除了价格数字本身,这次调价还有几个点值得展开:
取消上下文窗口分级。 以前大模型 API 定价通常按上下文长度分段——输入 token 越多,单价越高。这次小米把这个区分完全取消了,长上下文和短上下文走同一个价格标准。对经常处理长文档、长代码库的开发者来说,这个变化比单纯的折扣更实用。
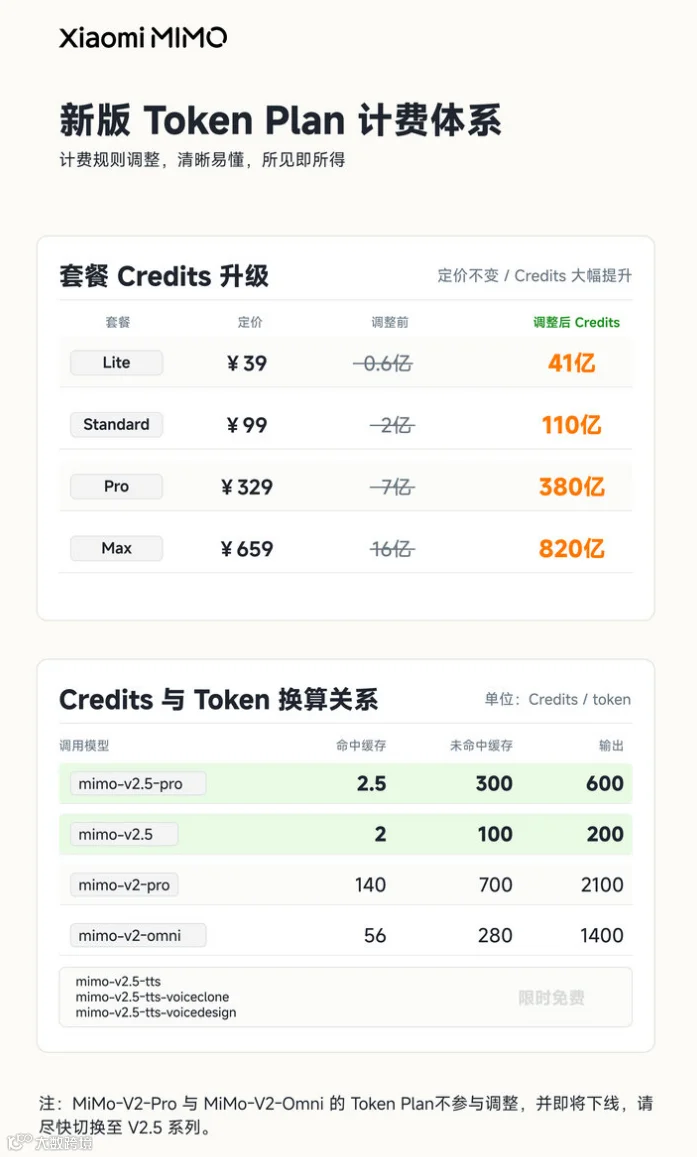
Token Plan 套餐大幅扩容。 在保持原套餐价格不变的前提下,用户可使用的 Token 数量提升至原来的 5 到 8 倍。同时,所有已订阅 Token Plan 且当前仍在有效期内的用户(包括参与百万亿 Token 创造者激励计划的用户),Credits 额度已于昨天 0 点全量重置,并按新计费规则执行。
高阶旧款模型维持原价,引导迁移 V2.5。 本次调价主要聚焦 MiMo-V2.5 核心系列。MiMo-V2-Pro 和 MiMo-V2-Omni 两款高阶模型 API 价格维持原价不变,其 Token Plan 套餐也不再参与调整并即将下线,小米在引导开发者向高性价比的 V2.5 系列迁移。
这个模型本身能打吗?
先搞清楚 MiMo-V2.5 的能力定位,再判断值不值得切过去。
4 月 23 日开源的 MiMo-V2.5 系列包含两个主力模型:MiMo-V2.5-Pro 是 1.02 万亿总参数(42B 激活参数)的 MoE 旗舰,专攻复杂软件工程和长程 Agent 任务,支持 1M 上下文窗口;MiMo-V2.5 是 3100 亿总参数(15B 激活参数)的原生全模态模型,支持文本、图像、视频、音频输入,推理速度更快。
几个硬核数据值得关注:
编程能力。 在 SWE-bench Pro 软件工程基准上解决率达 57.2%。从零写一个完整 SysY 编译器,4.3 小时、672 次工具调用,以 233/233 满分通过。还曾仅凭简单指令,独立构建出一个包含多轨道时间线等功能的 Web 视频编辑器。
Token 效率。 在 Agent 任务中,MiMo-V2.5-Pro 每任务仅消耗约 7 万 Token,而 Claude Opus 4.6、GPT-5.4 等普遍需要 12-18 万 Token,同等效果下直接省 40%-60% 的 Token 消耗。也就是说它不单单价便宜,完成任务本身耗的 Token 也更少——双重节省。
Agent 能力。 Artificial Analysis 综合智能指数和 Agent 指数全球开源模型并列第一。ClawEval Agent 基准中,Pro 版以约 64% 成功率领先开源领域,直接对标 Claude Opus 4.6 和 GPT-5.4。
生态验证。 开源 Agent 平台 Hermes Agent 已登顶 OpenRouter 全球应用 Token 消耗榜首,日消耗 2910 亿 Token,周调用量超 1.75 万亿。支撑其运行的模型中,小米 MiMo 排名第一,近一个月累计贡献 1.45 万亿 Token 调用量。这是百万级开发者"用脚投票"的结果——真正经过规模化验证的模型。
为什么突然降价?技术底座做了什么?
大模型降价不是简单的"烧钱换市场",背后离不开推理系统层面的持续优化。
根据官方公告,团队基于 SGLang HiCache 完整支持 SWA(Sliding Window Attention),将 KV Cache 在 GPU 显存、CPU 内存、SSD 等多级存储之间的数据搬运量降低至优化前的近 1/7,并将可缓存 Token 数量提升至优化前的近 5 倍。同时通过优化专家并行方案、输入长度分桶策略等,进一步提升集群输入吞吐能力。
简单理解:缓存命中率越高,实际服务成本越低——这是降价能够"永久化"的底气所在。
怎么接入?三种方式
方式一:小米 MiMo 开放平台。 访问官方平台注册账号、申请 API Key 即可使用,支持 OpenAI 兼容格式。适合直接调用、需要官方技术支持的场景。
方式二:OpenRouter。 已在 OpenRouter 上线,模型名称为 xiaomi/mimo-v2.5-pro 和 xiaomi/mimo-v2.5,提供标准化请求/响应格式,支持 reasoning 参数启用思维链推理。适合已在用 OpenRouter 管理多模型的开发者。
方式三:本地部署。 MiMo-V2.5 系列采用 MIT 许可证开源,可直接从 Hugging Face 下载模型文件部署到自有服务器,无商用限制。
注意: 本次调价仅针对 MiMo-V2.5 和 MiMo-V2.5-Pro。MiMo-V2-Pro 和 MiMo-V2-Omni 两款高阶模型 API 价格维持原价不变。如果你还在用 V2 系列,现在是最佳的切换窗口。
对 AI 编程场景意味着什么?
结合本号的定位,重点说下这对 AI 开发者的实际影响。
这个模型本身定位就是"专为 Agent 场景打造"。它在编程 Agent 场景下的 Token 消耗本就比竞品少 40%-60%,现在 API 价格又降到几乎可以忽略不计的水平——缓存命中场景每百万 Token 仅 0.025 元,输出 6 元。
打个比方:在 OpenCode 或 Hermes Agent 中跑一个标准的编码任务,消耗约 7-10 万 Token,其中大部分如果命中缓存,实际费用可能不到一分钱。对于高频使用 AI 编程的开发者来说,用这个模型几乎不会有成本顾虑。DeepSeek V4-Pro 降价后也到了同一水位(缓存命中 0.025 元),两家竞争最终受益的是开发者。
写在最后
几个要点总结:
- 降价真实且永久。
Pro 版缓存命中输入从最高 2.80 元降到 0.025 元,降幅 98% 以上,昨天 0 点起全球生效,不是限时促销。 - 取消上下文分级同样重要。
对长上下文使用场景来说,实际节省远超单纯的价格降幅。 - 降价不降质。
MiMo-V2.5-Pro 在 ClawEval Agent 评测开源第一、SWE-bench Pro 解决率 57.2%、千亿 Token 调用量验证的稳定性——这些数据在降价前就已存在。 - Token Plan 扩容让个人开发者更受益。
同等价格下额度提升 5-8 倍,对于日均调用量不大的个人开发者和团队,实际成本进一步被摊薄。 - 生态已成熟。
OpenRouter 已上线,接入成本为零。现有订阅用户的 Credits 昨天已重置,现在接入或切换正是时候。
你目前在用哪个模型跑 Agent 任务?有没有考虑切到 MiMo V2.5?欢迎在评论区分享你的实测体验。



