

对于图片、PDF 转文字这件事,之前一直用的方案是:
要么付费软件,每个月固定成本,有些场景还不方便;要么 AI 转换,截图发给大模型,等它回复,再复制出来。一两张还行,遇到一二十张的时候就麻烦了——来回折腾的时间比手工录入还多。
直到实测了一下 PaddleOCR,效果出乎意料。然后用 OpenCode 开发了一个网页小工具,上传图片/PDF,一键识别,结果直接复制,或者下载成 .md 文件。最小闭环跑通了,后续在项目里需要 OCR 的地方可以直接复用,不用再调用付费服务了。
先搞清楚:PaddleOCR 是什么
光看名字容易误以为它只是个 OCR 引擎,实际上它已经是文档 AI 基础设施了。
来看核心数据(来源:GitHub API,2026-05-24):
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
维护者是百度飞桨团队,GitHub 主页 paddlepaddle/PaddleOCR。
它能做什么
PaddleOCR 已经不是单纯的"文字识别"工具了,而是智能文档解析全家桶:
通用文字识别(PP-OCRv5)
- 支持 100+ 语言,中英日韩俄阿泰等全覆盖
- 移动端/服务端都高效,支持 CPU/GPU/NPU 多硬件
- v5 版本比上一代提升 13% 准确率
文档结构解析(PP-StructureV3)
- 直接输出 Markdown 或 JSON
- 表格识别、公式识别、版面分析
- PDF 转 Markdown,一键搞定
视觉语言大模型(PaddleOCR-VL-1.5)
- 0.9B 参数的 VLM 模型
- 在 OmniDocBench 达到 94.5% 准确率
- 专门应对弯曲、扫描、屏幕拍照、光照不均、倾斜等复杂场景
- 输出格式为 Markdown 或 JSON,天然适配 RAG 应用
官方口号已经变成 "Turn any PDF or image document into structured data for your AI",定位很清晰——给 LLM 喂数据的工具。
大模型已经能看懂图片,为什么还需要 OCR?
这是一个很好的问题。现代多模态大模型(如 GPT-4V、Claude Vision)确实能够理解图片中的文字,但 OCR 开源项目在以下场景仍有不可替代的价值:
场景一:需要提取结构化文本
大模型输出:
"这张图片包含一段关于人工智能的描述..."
OCR 输出:
"人工智能(Artificial Intelligence)...
是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的新兴技术科学。"
大模型给出的是理解性描述,OCR 给出的是逐字提取的原始文本,可以直接复制、搜索、编辑。
场景二:大规模文档处理
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
完全本地,数据不外传 |
|
|
|
|
|
对于企业内部的敏感文档(合同、财务报表、医疗记录),本地 OCR 是唯一合规选择。
场景三:批量自动化流水线
# OCR 可以无缝接入现有自动化流程
for pdf_file in pdf_list:
text = ocr_process(pdf_file)
save_to_database(text) # 存入数据库
send_to_translation_api(text) # 触发翻译
index_to_search_engine(text) # 索引搜索引擎
场景四:离线与边缘部署
- 嵌入式设备、物联网终端
- 内网隔离的政务系统
- 完全没有网络连接的环境
核心价值总结:
✓ 精确文本提取 - 不是"理解图片",而是"复制文字"
✓ 完全隐私保护 - 数据不出本地服务器
✓ 批量自动化处理 - 大规模文档数字化的基础设施
✓ 零边际成本 - 一次部署,无限次使用
✓ 可定制训练 - 根据业务场景优化识别效果
PaddleOCR vs Tesseract:选哪个
这是两个最主流的开源 OCR 方案放在一起对比:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
简单结论:
- 纯文字提取 + 快速上手 → Tesseract(装完就能用)
- 复杂文档(表格、印章、多语言混合、中文为主)→ PaddleOCR
- 想让 OpenCode 帮你写代码 → 两者都行,PaddleOCR 中文场景更强
OpenCode 怎么配合 PaddleOCR
为什么需要 OpenCode
PaddleOCR 本身很强大,但实际用起来有几个绕不开的问题:
- 参数配置复杂
——PP-OCRv5、PP-StructureV3、PaddleOCR-VL 三个系列各有各的参数体系 - 批量处理脚本要自己写
——官方示例都是单图演示,批量跑要自己拼逻辑 - PDF 处理要结合其他库
——PyMuPDF、pdf2image 等工具链要自己组装 - 结果后处理
——识别完了还要清洗、整理、导出
这些问题对于会写 Python 的人不算难,但:
-
每次换新项目都要重新查文档 -
不同文档类型要调不同参数 -
批量处理逻辑容易出 bug
OpenCode 解决的问题是:这些它都能帮你写,你只需要描述需求。
OpenCode 的完整处理流程
OpenCode 接到需求后会按 5 个步骤处理:
1. 需求分析 → 确定技术栈(Flask + PaddleOCR)
2. 设计架构 → 前端上传 → 后端 API → OCR 引擎 → 返回结果
3. 编写代码 → 生成 paddleocr_api.py、index.html
4. 解决难点 → PDF 跨平台处理方案(pypdf + PIL 而非 pdf2image)
5. 整理文档 → README、技术解读
你不需要写一行代码,只需要描述需求和确认方向。
架构是什么样的
┌──────────────────────────────────────────────────────────────┐
│ OpenCode │
│ (AI 编程助手) │
│ │
│ 开发者 ──→ OpenCode ──→ 生成 OCR 代码 │
│ │ (paddleocr_api.py) │
│ │ │
│ └──→ 分析代码 ──→ 调试 ──→ 完成 │
└──────────────────────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────────────┐
│ DocuScan 应用 │
│ │
│ 前端(浏览器) ←→ Flask API ←→ PaddleOCR 引擎 │
│ │
│ index.html ←→ paddleocr_api.py ←→ 文字识别 │
└──────────────────────────────────────────────────────────────┘
图片 OCR 流程
用户上传图片 (PNG/JPG)
│
▼
┌─────────────────┐
│ Flask 接收文件 │ ← multipart/form-data 上传
└────────┬────────┘
│
▼
┌─────────────────┐
│ 保存到临时目录 │
└────────┬────────┘
│
▼
┌─────────────────┐
│ PaddleOCR 识别 │ ← ocr = PaddleOCR(lang="ch")
│ 返回文字列表 │
└────────┬────────┘
│
▼
┌─────────────────┐
│ 构建 Markdown │
└────────┬────────┘
│
▼
┌─────────────────┐
│ 返回 JSON 响应 │ ← {"success": true, "text": "...", "stats": {...}}
└─────────────────┘
PDF OCR 流程(跨平台方案)
PDF 处理比图片复杂一点,因为 PDF 里的内容可能是文本层(直接可提取),也可能是嵌入图片(需要先 OCR)。
OpenCode 生成的方案用了 pypdf + PIL,而不是 pdf2image——原因是 pdf2image 需要安装 poppler 依赖,在 Windows 上需要手动配置环境变量,对普通用户不够友好。pypdf + PIL 是纯 Python 方案,跨平台兼容更好。
用户上传 PDF
│
▼
┌─────────────────┐
│ pypdf 读取 PDF │ ← PdfReader(pdf_path)
└────────┬────────┘
│
▼
┌─────────────────┐
│ 尝试提取文本层 │ ← page.extract_text()
└────────┴────────┘
│
有文本?
├─ 是 → 直接使用文本
└─ 否 → 提取嵌入图片
│
▼
┌─────────────────┐
│ 提取 XObject │ ← 遍历 page["/XObject"]
│ 中的嵌入图片 │
└────────┬────────┘
│
▼
┌─────────────────┐
│ PIL 转换为 PNG │ ← Image.open(io.BytesIO(img_data))
└────────┬────────┘
│
▼
┌─────────────────┐
│ PaddleOCR 识别 │ ← ocr_image(temp_img_path)
│ 临时图片文件 │
└────────┬────────┘
│
▼
┌─────────────────┐
│ 返回 Markdown │
└─────────────────┘
这套方案的关键决策点是 OpenCode 帮你做的——它权衡了跨平台兼容性和实现复杂度,最终选了 pypdf + PIL。这个决策本身就有价值,省去了你自己踩坑的时间。
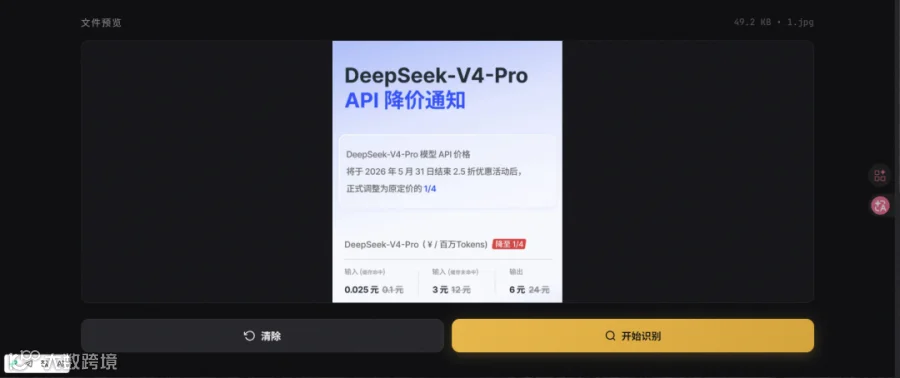
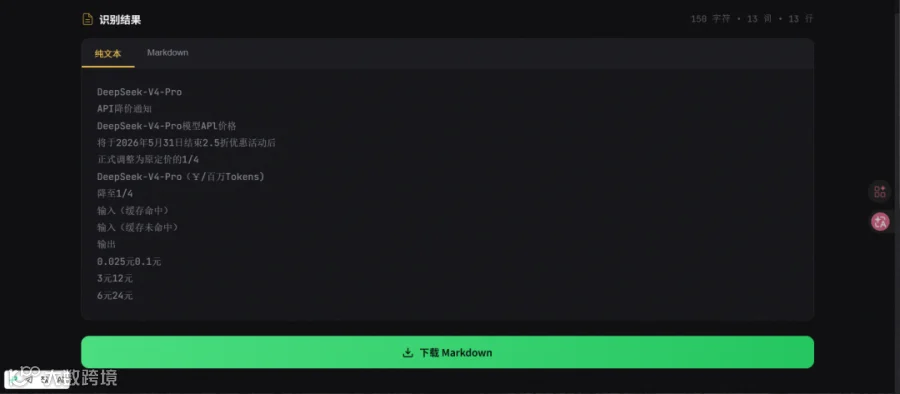
实际跑一遍:用 OpenCode 网页工具识别 DeepSeek 降价信息图
这里演示用 OpenCode 开发的网页工具识别一张 DeepSeek 降价信息图的效果:
操作步骤:
1. 打开网页工具
2. 上传 DeepSeek 降价信息图(截图、PPT 导出图片等均可)
3. 点击识别,等待几秒
4. 结果直接显示在网页上,可一键复制,也可下载为 .md 文件
不同场景怎么选
场景一:发票、合同等固定格式文档
- 推荐:PP-StructureV3
- 理由:直接输出表格结构,字段位置相对固定
- 参数:table=True, use_doc_analysis=True
场景二:身份证、营业执照等证件
- 推荐:PP-OCRv5 + 关键字段检测
- 理由:文字区域明确,适合单字段定位
- 参数:det_model_dir 指定检测模型
场景三:复杂排版的合同、协议
- 推荐:PaddleOCR-VL-1.5
- 理由:VLM 模型理解版面结构,Markdown 输出
- 参数:rec_model 选择 PaddleOCR-VL 系列
典型应用场景
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
安装配置速查
环境准备
# 创建虚拟环境(推荐)
python -m venv paddle_ocr_env
source paddle_ocr_env/bin/activate # Linux/Mac
# paddle_ocr_env\Scripts\activate # Windows
# 安装 PaddlePaddle(CPU 版本)
pip install paddlepaddle
# 安装 PaddleOCR
pip install "paddleocr>=2.7.0"
GPU 加速版本(需要 NVIDIA 显卡):
pip install paddlepaddle-gpu
快速试用(单图片识别)
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang='ch')
result = ocr.ocr('invoice.png')
for line in result[0]:
print(line)
批量处理脚本
from pathlib import Path
from paddleocr import PaddleOCR
import json
def batch_ocr(image_dir, output_file):
ocr = PaddleOCR(use_angle_cls=True, lang='ch')
image_files = list(Path(image_dir).glob("*.png")) + \
list(Path(image_dir).glob("*.jpg"))
all_results = []
for img_path in image_files:
result = ocr.ocr(str(img_path))
all_results.append({
"file": str(img_path),
"text": [line[1][0] for line in result[0]]
})
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(all_results, f, ensure_ascii=False, indent=2)
batch_ocr('./images', 'ocr_results.json')
语言参数参考
# 中文(默认)
ocr = PaddleOCR(lang="ch")
# 英文
ocr = PaddleOCR(lang="en")
# 日文
ocr = PaddleOCR(lang="jp")
# 韩文
ocr = PaddleOCR(lang="ko")
# 法文
ocr = PaddleOCR(lang="fr")
# 德文
ocr = PaddleOCR(lang="de")
扩展方向
|
|
|
|---|---|
|
|
lang 参数(en, jp, ko 等)
|
|
|
table 模块
|
|
|
|
|
|
|
|
|
|
写在最后
用 OpenCode + PaddleOCR 做文档识别流水线,本质上是让 AI 帮你写胶水代码。
PaddleOCR 本身已经把 OCR 的事情做到了 90 分——100+ 语言支持、表格/公式/版面分析、GPU 加速。剩下 10 分就是把它跟你的业务接起来:文件读取、批量处理、结果清洗、格式转换。
这 10 分以前要花不少时间查文档、写调试,现在告诉 OpenCode 你的需求就行。
你在用 PaddleOCR 吗?遇到过什么坑?评论区聊聊。




