

为什么需要上下文管理
LLM 的上下文窗口是有限的——Claude Sonnet 4.5 是 200K,MiniMax M3 是 1M(API 保证 512K)。
听起来很大,但实际使用很快就会塞满:
- 一次 read 工具调用可能返回几千 token
- Bash 命令输出经常上万 token
- 多轮对话 + 工具调用的累积
塞满之后会发生:
- AI 开始「忘记」之前的指令
- 工具调用参数报错(context too long)
- 响应速度变慢(要处理的内容太多)
- 某些 Provider 直接报错拒绝
Pi 的解决思路:旧消息自动总结,保留关键信息,新对话继续往前走。
Pi 的两层压缩机制
Pi 有两套上下文压缩机制,针对不同场景:
|
|
|
|
|---|---|---|
| Compaction(压缩) |
/compact
|
|
| Branch Summary(分支摘要) | /tree
|
|
两套机制用同一个结构化摘要格式,累积追踪文件操作——多次压缩不会丢失文件操作历史。
Compaction(上下文压缩)
自动触发条件
Pi 自动触发压缩的判断逻辑:
contextTokens > contextWindow - reserveTokens
reserveTokens 默认 16384(16K),给 LLM 的响应留空间。
举例:用 200K 上下文的 Claude 模型,剩 184K 空间时自动触发压缩。
手动触发
/compact
/compact 重点保留文件路径和决策,不要细节对话
第二个用法是 自定义摘要重点——告诉 AI「我希望你重点保留什么」。
压缩后会发生什么
压缩前:

压缩后:

AI 实际看到的:

关键是:原始消息没删,只是 AI 看不到。 Session 文件保留完整历史,压缩是「视图」层面的操作。
多次压缩会怎样
反复压缩时,Pi 不是从压缩点重新开始,而是从上一次压缩的「保留边界」开始:
-
第一次压缩:保留 entry 7 之后 -
第二次压缩:保留第一次压缩时保留的 entry 7 之后(不是从压缩点 entry 10 重新开始)
这样多次压缩累积有效,不会把上一轮已经保留的内容又「忘了」。
配置压缩参数
在 ~/.pi/agent/settings.json 或项目级 <project>/.pi/settings.json:
{
"compaction": {
"enabled": true,
"reserveTokens": 16384,
"keepRecentTokens": 20000
}
}
|
|
|
|
|---|---|---|
enabled |
true |
|
reserveTokens |
16384 |
|
keepRecentTokens |
20000 |
|
实战调参建议:
{
"compaction": {
"enabled": true,
"reserveTokens": 32768, // 长输出场景(生成长文、写代码)调大
"keepRecentTokens": 40000 // 不想让 AI 太快「失忆」调大
}
}
注意:keepRecentTokens 调太大,会让自动压缩迟迟不触发,最后反而单次压缩成本更高。
/tree 分支导航
Compaction 是「时间线」上的压缩,/tree 是在「分支」上的导航。
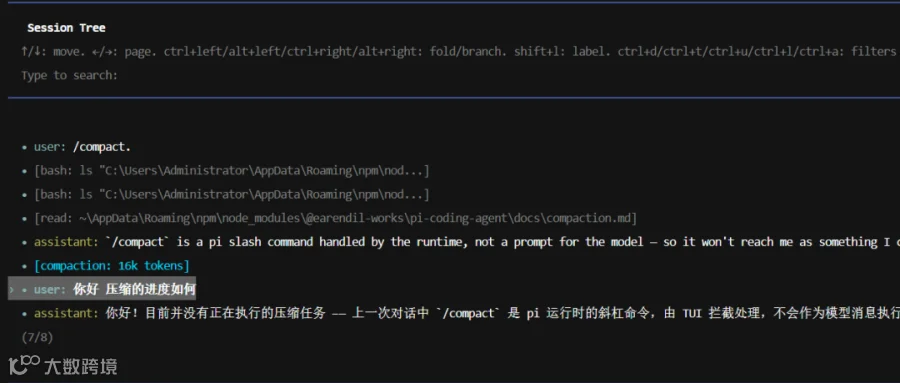
Session 是棵树
Pi 的每个对话不是线性结构,是树形结构。每条消息有 id 和 parentId,当前所在位置是「活跃叶子」。

/tree 命令打开这个树视图,让你 在分支之间跳来跳去。
/tree 操作方式
打开 /tree 后:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
选中后会发生什么
选中 user/custom 消息:
1. 把当前叶子移到选中消息的父节点
2. 选中的消息内容放进编辑器
3. 你可以编辑后重新提交——创建新分支
选中 assistant/tool/压缩条目:
1. 把当前叶子移到该条目
2. 编辑器清空
3. 从那个点继续对话
关键能力:探索多条方案,不用担心「走错了回不去」。 AI 给了 A 方案不满意,跳回决策点试 B 方案。
分支摘要:离开时保留上下文
/tree 切换到另一个分支时,Pi 会问你要不要给「离开的分支」生成摘要。

选中目标后,Pi 提示三个选项:
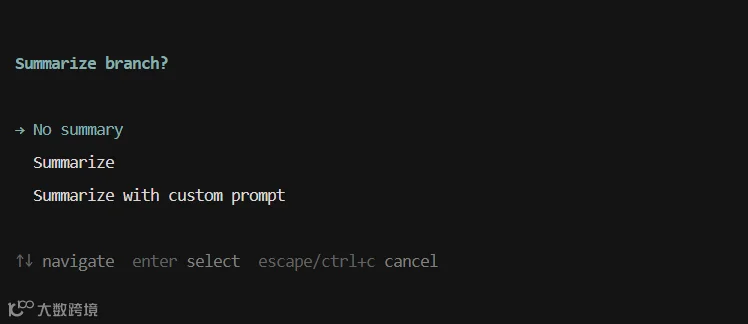
- 不摘要
(默认):直接切换 - 用默认 prompt 摘要
:Pi 用内置 prompt 总结 - 自定义重点摘要
:你可以指定重点
摘要会作为 BranchSummaryEntry 追加到新分支,新分支的 AI 能看到「原来那条分支干了什么」,避免切分支后「失忆」。
/tree /fork /clone 怎么选
|
|
|
|
|---|---|---|
/tree |
同一文件 |
|
/fork |
|
|
/clone |
|
|
经验法则:
- 还在探索 → /tree(不用新文件,简化管理)
- 想开新工作线 → /fork 或 /clone
Session 管理命令汇总
# 命令行启动
pi -c # 续上次会话
pi -r # 浏览历史会话
pi --no-session # 临时模式(不保存)
pi --name "我的任务" # 启动时给会话命名
pi --session <id> # 用特定会话
pi --fork <id> # Fork 特定会话
# 交互模式
/resume # 浏览历史
/new # 新会话
/name <name> # 给当前会话命名
/session # 查看当前会话信息
/tree # 分支导航
/fork # 从历史消息 fork
/clone # 复制当前分支
/compact [prompt] # 手动压缩
/export [file] # 导出 HTML
/share # 上传 GitHub Gist
实战建议
长任务场景
跑跨多个文件的重构任务时:
- 早期阶段
:让 AI 自由探索,不急着重命名 - 找到方向后
: /name "重构 v2:xxx 方案"命名 - 尝试新方案
: /fork出来新会话对比 - 上下文撑不住
: /compact手动触发,配上「保留文件决策和当前进度」
多方案对比
AI 给了两种实现方案?
/tree回到方案选择点 -
选「试试 B 方案」 -
Pi 创建新分支 -
B 方案试完不满意, /tree回到原分支继续 -
全程一份 Session 文件,方便归档
隐私 / 成本敏感
-
用 pi --no-session跑一次性任务(不存盘) -
调小 keepRecentTokens,让压缩更激进,省 token
常见问题
Q1:压缩会丢信息吗
原始数据不丢,Session 文件保留完整历史。丢的是「AI 视图」——AI 看到的旧消息被摘要替代。
如果你后面想看原始内容,/export 导出 HTML,里面有完整记录。
Q2:什么时候用自动 vs 手动压缩
默认靠自动。手动压缩适合以下场景:
- 任务切换前(让旧任务摘要掉)
- 想让 AI 「专注」(主动扔掉旧上下文)
- 测试新 prompt(用 /compact 重点关注 xxx)
Q3:/tree 选错节点怎么办
Escape 取消,不会真的切分支。Tree 视图是只读的,选中 Enter 才生效。
Q4:怎么找之前的 session
pi -r # 启动时浏览
或交互模式 /resume。
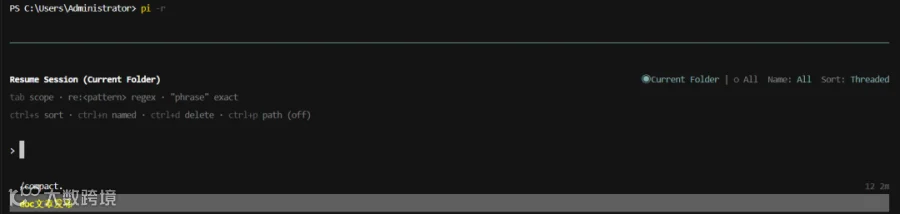
支持:
- 搜索(输入关键词)
- Ctrl+P 切换显示路径
- Ctrl+S 切换排序
- Ctrl+N 只看命名会话
- Ctrl+R 重命名
- Ctrl+D 删除(用 trash CLI,不是 rm)
Q5:Pi 用什么格式存 session
JSONL 文件,存在 ~/.pi/agent/sessions/,按工作目录组织。每条消息是文件一行,附 id 和 parentId 字段。
写在最后
上下文管理是 Pi 区别于「一次性 AI 对话」的关键能力。
很多 AI 工具用着用着就「失忆」了,Pi 的解法是:自动压缩保活跃、tree 分支保探索、Session 文件保完整。
三个机制配合,让 Pi 能跑长任务、多方案、需要回溯的真实工作流。
下次跑 Pi 遇到「AI 忘了之前说过什么」,试试 /compact 配上具体指令。



